










CNN类
一 . ResNet
提出问题:网络越深,越难训练,这是因为存在梯度消失和梯度爆炸问题
解决方案:残差连接时,先加法运算,再激活
模型图:

ResNet采用网络中增加残差网络的方法,解决网络深度增加到一定程度,更深的网络堆叠效果反而变差的问题。在网络深度到一定程度,误差升高,效果变差,梯度消失现象越明显,后向传播时无法把梯度反馈到前面网络层,前面网络参数无法更新,导致训练变差。残差网络增加一个恒等映射,跳过本层或多层运算,同时后向传播过程中,下一层网络梯度直接传递给上一层,解决深层网络梯度消失的问题。
优点:1. 过于深的网络在反传时容易发生梯度弥散,一旦某一步开始导数小于1,此后继续反传,传到前面时,用float32位数字已经无法表示梯度的变化了,相当于梯度没有改变,也就是浅层的网络学不到东西了。这是网络太深反而效果下降的原因。加入ResNet中的shortcut结构之后,在反传时,每两个block之间不仅传递了梯度,还加上了求导之前的梯度,这相当于把每一个block中向前传递的梯度人为加大了,也就会减小梯度弥散的可能性。
2. 在正向卷积时,对每一层做卷积其实只提取了图像的一部分信息,这样一来,越到深层,原始图像信息的丢失越严重,而仅仅是对原始图像中的一小部分特征做提取。这显然会发生类似欠拟合的现象。加入shortcut结构,相当于在每个block中又加入了上一层图像的全部信息,一定程度上保留了更多的原始信息。上一层信息保留了一些简单的特征用于判断,对部分任务会好。不同层次上的特征组合。
3.恒等映射增加基本不会降低网络的性能。
缺点:
1.训练时间长,深度残差网络中有大量的冗余
2、Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs 论文中指出 resnet的感受野 其实并没有理论上那么大,虽然堆叠了很多网络层,但是有效深度是不够的。
我们曾经相信大 kernel 可以用若干小 kernel 来替换,比如一个 7x7 可以换成三个 3x3,这样速度更快(3x3x3< 1x7x7),效果更好(更深,非线性更多)。有的同学会想到,虽然深层小 kernel 的堆叠容易产生优化问题,但这个问题已经被 ResNet 解决了(ResNet-152 有 50 层 3x3 卷积),那么这种做法还有什么缺陷呢?——ResNet 解决这个问题的代价是,模型即便理论上的最大感受野很大,实质上的有效深度其实并不深,所以有效感受野并不大。这也可能是传统 CNN 虽然在 ImageNet 上跟 Transformer 差不多,但在下游任务上普遍不如 Transformer 的原因。也就是说,ResNet 实质上帮助我们回避了「深层模型难以优化」的问题,而并没有真正解决它。
二. EfficientNet
提出问题:如何获取高效的模型
解决方案:模型缩放
对网络深度、宽度和分辨率中的任何温度进行缩放都可以提高精度。EfficientNet通过这三个维度进行了模型缩放,分为B0-B7 八个版本
EfficientNet网络内部使用了MBConv(mobile inverted bottleneck convolution)是通过神经网络架构搜索得到的,该模块结构与深度分离卷积(depthwise separable convolution)相似,该移动翻转瓶颈卷积首先对输入进行1x1的逐点卷积并根据扩展比例(expand ratio)改变输出通道维度(如扩展比例为3时,会将通道维度提升3倍。但如果扩展比例为1,则直接省略该1x1的逐点卷积和其之后批归一化和激活函数)。接着进行kxk的深度卷积(depthwise convolution)。如果要引入压缩与激发操作(SE模块),该操作会在深度卷积后进行。再以1x1的逐点卷积结尾恢复原通道维度。最后进行连接失活(drop connect)和输入的跳越连接(skip connection)。 SE模块首先对特征图进行压缩操作,在通道维度方向上进行全局平均池化操作(global average pooling),得到特征图通道维度方向的全局特征。然后对全局特征进行激发操作,使用激活比例(R,该比例为浮点数)乘全局特征维数(C)个1x1的卷积对其进行卷积(原方法使用全连接层),学习各个通道间的关系,再通过sigmoid激活函数得到不同通道的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在通道维度上做(注意力)attention或者(门控制)gating操作,这种注意力机制让模型可以更加关注信息量最大的通道特征,而抑制那些不重要的通道特征。
SE模块首先对特征图进行压缩操作,在通道维度方向上进行全局平均池化操作(global average pooling),得到特征图通道维度方向的全局特征。然后对全局特征进行激发操作,使用激活比例(R,该比例为浮点数)乘全局特征维数(C)个1x1的卷积对其进行卷积(原方法使用全连接层),学习各个通道间的关系,再通过sigmoid激活函数得到不同通道的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在通道维度上做(注意力)attention或者(门控制)gating操作,这种注意力机制让模型可以更加关注信息量最大的通道特征,而抑制那些不重要的通道特征。
优点:精度高与Resnet,参数少。
缺点:使用大分辨率的图片进行训练会很慢,网络结构里的深度可分离卷积也不快, α,β,γ 的参数只对b0到b1是最优的,但对于b2到b7并不一定。
三. ResNeXt(CVPR2017)
提出问题:如何获得简洁且高度可调节的神经网络结构
解决方案:分组卷积,split-transform-merge
该网络的提出主要吸收了VGG/ResNet和Inception家族网络的优点。VGG/ResNet的优点是网络结构是通多堆叠相同拓扑结构的模块而成,这样的话可以减少超参数的自由选择,网络深度称为最根本的超参数。而Inception家族的网络的Inception模块都是精心设计的,但是都遵循一个特性,那就是split-transform-merge。Inception网络的这种设计可以用最低的计算复杂性达到大的和深的网络的表征能力。但是Inception有一个缺点就是超参数太多了,因此不知如何调整这个网络去适应新的数据集。
split-transform-merge
Split:输入分支, 引入1×1卷积:参数量太复杂,做一个低维嵌入,让输入的数据变的简单化,容易操作
transform:每个分支相当于一个变换,对数据做了一系列操作,由网络层完成。
merge:逐通道拼接
优点:在不增加参数量情况下,提高了准确率。
缺点:ResNeXt比ResNet的方差大,需要大数据集来训练。
四. DenseNet(CVPR2017,Best Paper)
提出问题:梯度消失问题在网络深度越深的时候越容易出现
解决方案:每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题
DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing问题的产生.结合信息流和特征复用的假设,DenseNet当之无愧成为2017年计算机视觉顶会的年度最佳论文.
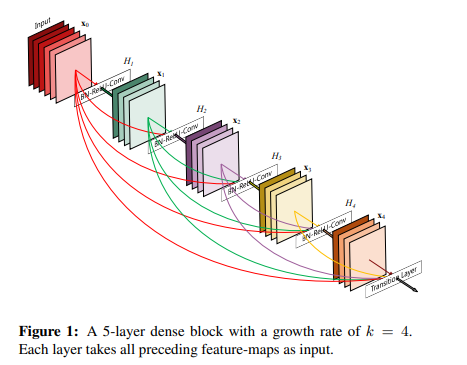
DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L LL 层的网络,DenseNet共包含
个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。

优点:
减轻了vanishing-gradient(梯度消失)
加强了feature的传递
更有效地利用了feature
一定程度上较少了参数数量(增加了参数利用率)
缺点:
占用显存
由于不断的拼接操作,也导致过多的重复梯度信息














 2147
2147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









