







阅读论文:
Lim, Bryan, et al. “Temporal fusion transformers for interpretable multi-horizon time series forecasting.” International Journal of Forecasting 37.4 (2021): 1748-1764.
Giacomazzi, Elena, Felix Haag, and Konstantin Hopf. “Short-Term Electricity Load Forecasting Using the Temporal Fusion Transformer: Effect of Grid Hierarchies and Data Sources.” arXiv preprint arXiv:2305.10559 (2023).
目录
背景
在论文1中,时序预测被限定在了multi-horizon forecasting的背景下,通过Fig. 1可以很好理解这点,我认为通俗来说所谓multi-horizon,主要是指模型看到的输入数据的种类和范围扩展了,并且支持动态步数的多步预测。
- 输入数据种类扩展,其实就是多变量时序预测,图1中包含了静态协变量、待预测数据的历史观测数据、其他相关已知数据。从这个种类扩展的角度看和多变量时序预测没有区别。
- 输入数据范围扩展,multi-horizon与multivariate的关注重点的区别就出来了,multi-horizon的输入数据使用到了预测时间以后的数据(除了待预测的数据以外的,比如天气预报),具体到Fig. 1就是Known Inputs包含了未来时间范围部分,而静态协变量因为静态不变性因此也存在未来时间的范围部分。
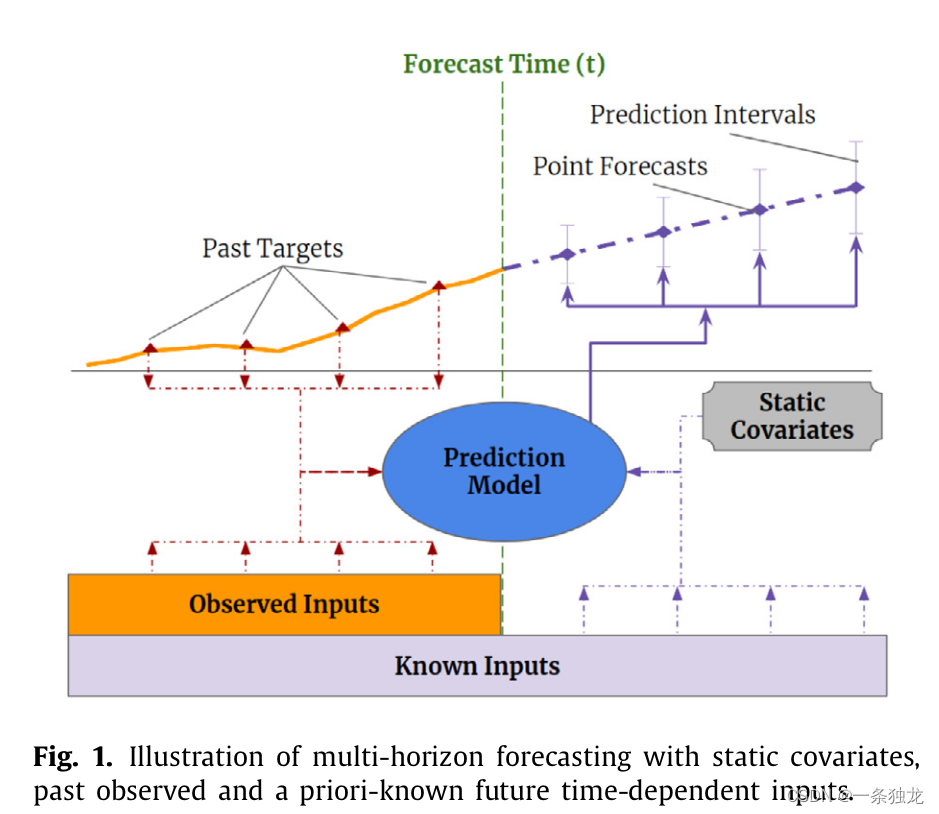
变量的两方面扩展带并不会直接带来模型精度提升,不当地处理甚至可能导致模型训练推理速度和精度的下降。传统多变量预测中常常需要实施特征工程,对变量进行自动或手工的选择和处理,但都没有认真思考如何充分利用各种异质输入数据。因此这篇文章的主要问题就是如何可解释地高效利用这些异质的输入数据。
因为论文2是用论文1的方法做电负荷预测的评估,因此这里一并写一下背景。电网的电力负荷和发电、输电、配电、用电等环节息息相关,而近年来我国发电环节受能源结构改革影响,用电环节受社会各方面因素复杂化影响(例如疫情下各类用电的载荷特征的特殊变化),电力负荷的预测变得更具挑战。电力负荷预测根据预测时间跨度长短可分为长期、中期、短期和超短期等,其时间跨度单位从年直到秒均有覆盖,每种预测时间跨度有其不同的重要意义,其中以短期负荷预测更具直接价值。比较常见的预测时间范围有提前预测一天和预测一周的完整电力负荷路径,例如,若以15分钟为采样间隔,则两种时间范围下分别需要预测96和96*7个电力负荷数据点。
论文2针对电力负荷的短期预测问题,探索了时间融合Transformer(TFT)在不同预测时间范围(day-ahead和week-ahead)和电网层级(电网级别和变电站级别)上的效果。近年来深度学习方法(尤其是LSTM)在负荷预测中表现出色。但是LSTM在处理较长时间序列时仍有局限性。Transformer架构能够克服LSTM已知的局限性,TFT进一步增强了Transformer在时间序列预测上的能力。已有的TFT用于电力负荷预测的研究还存在数据集单一、考虑变量有限等问题,需要进一步的外部验证。本文通过在不同数据集上考察TFT的效果,以及在不同电网层级上(电网级别和变电站级别)进行分层预测,来验证TFT在短期电力负荷预测中的潜力。
方法
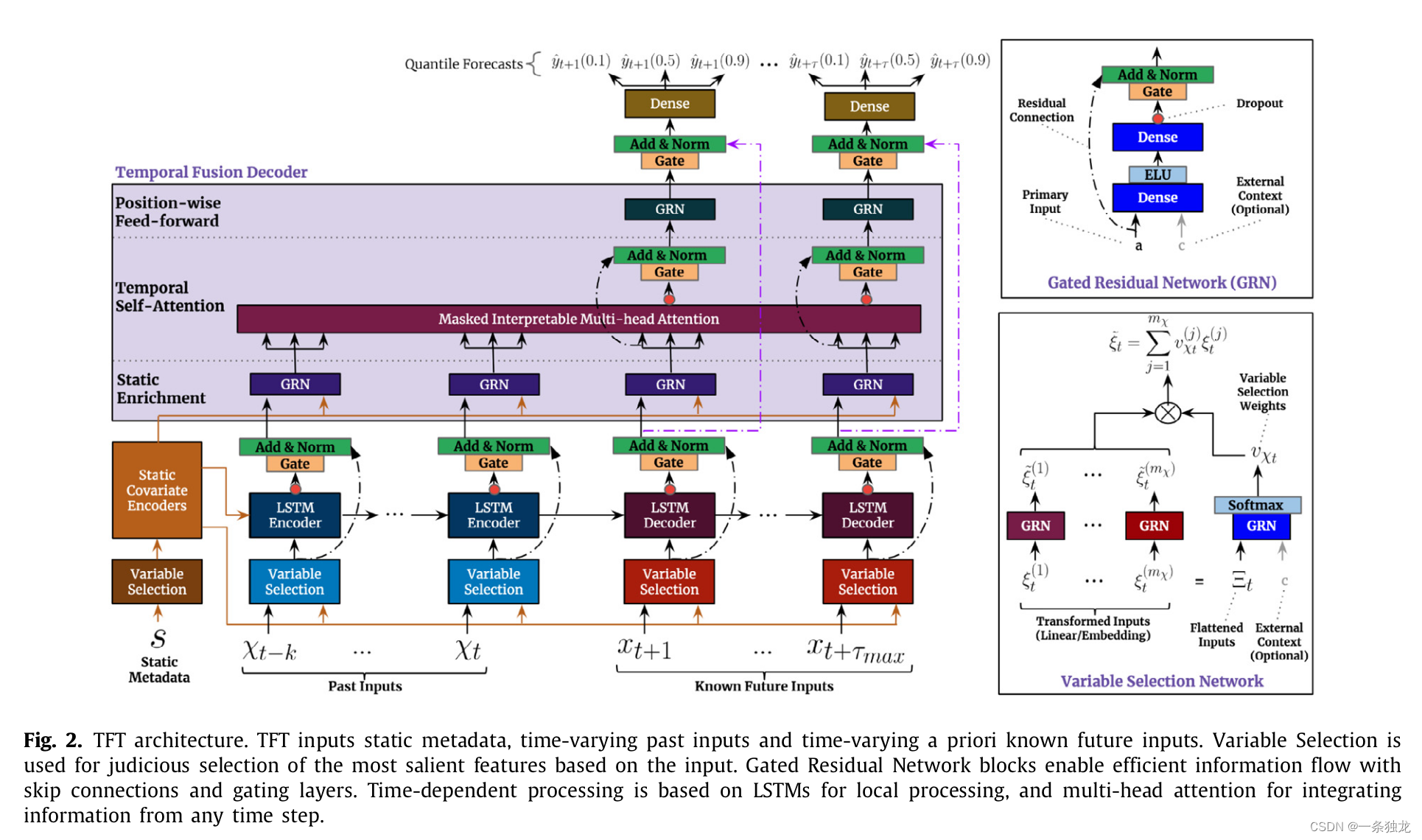
TFT模型比较复杂,包含了很多针对输入数据设计的结构。输入数据包含了静态协变量、历史数据(包括目标变量历史观测值和其他异质数据)、已知未来数据。
一个很关键的基础结构设计是门控残差网络(Gated Residual Network),通过残差连接和门控层确保有效信息的流动,使得整个模型的各部分具有类似长短期记忆的特性。其输入是主要输入
a
\mathbf{a}
a和可选的上下文向量
c
\mathbf{c}
c,门控线性单元GLU和指数线性激活单元激活函数ELU是用别人论文提出的。
G
R
N
ω
(
a
,
c
)
=
LayerNorm
(
a
+
G
L
U
ω
(
η
1
)
)
,
η
1
=
W
1
,
ω
η
2
+
b
1
,
ω
,
η
2
=
E
L
U
(
W
2
,
ω
a
+
W
3
,
ω
c
+
b
2
,
ω
)
,
\begin{aligned} \mathrm{GRN}_{\omega}(\mathbf{a},\mathbf{c})& =\text{LayerNorm}\left(\mathbf{a}+\mathrm{GLU}_\omega(\eta_1)\right), \\ \eta_{1}& =\boldsymbol{W}_{1,\omega}\boldsymbol{\eta}_2+\boldsymbol{b}_{1,\omega}, \\ \eta_{2}& =\mathrm{ELU}\left(\boldsymbol{W}_{2,\omega}\boldsymbol{a}+\boldsymbol{W}_{3,\omega}\boldsymbol{c}+\boldsymbol{b}_{2,\omega}\right), \end{aligned}
GRNω(a,c)η1η2=LayerNorm(a+GLUω(η1)),=W1,ωη2+b1,ω,=ELU(W2,ωa+W3,ωc+b2,ω),
G L U ω ( γ ) = σ ( W 4 , ω γ + b 4 , ω ) ⊙ ( W 5 , ω γ + b 5 , ω ) , \mathrm{GLU}_{\omega}(\boldsymbol{\gamma})=\sigma(\boldsymbol{W}_{4,\omega}\boldsymbol{\gamma}+\boldsymbol{b}_{4,\omega})\odot(\boldsymbol{W}_{5,\omega}\boldsymbol{\gamma}+\boldsymbol{b}_{5,\omega}), GLUω(γ)=σ(W4,ωγ+b4,ω)⊙(W5,ωγ+b5,ω),
TFT模型中,首先所有输入数据都经过变量选择网络(Variable Selection Network),通过学习不同权重实现对变量的选择和解释。接着经过选择的变量通过LSTM处理层进行特征提取。通过给LSTM Encoder喂入过去的特征
ξ
~
t
−
k
:
t
\tilde{\boldsymbol{\xi}}_{t-k:t}
ξ~t−k:t ,给LSTM Decoder喂入未来的特征
ξ
~
t
+
1
:
t
+
τ
max
\tilde{\boldsymbol{\xi}}_{t+1:t+\tau_{\max}}
ξ~t+1:t+τmax ,然后LSTM编码器和解码器会生成一组统一的时序特征,输入可表示为:
ϕ
(
t
,
n
)
∈
{
ϕ
(
t
,
−
k
)
,
…
,
ϕ
(
t
,
τ
max
)
}
\phi(t,n)\in\{\boldsymbol{\phi}(t,-k),\ldots,\phi\left(t,\tau_{\max}\right)\}
ϕ(t,n)∈{ϕ(t,−k),…,ϕ(t,τmax)} ,
n
n
n为位置索引。最后,在进入TFD前,会经过残差连接和层归一化操作:
ϕ
~
(
t
,
n
)
=
LayerNorm
(
ξ
~
t
+
n
+
G
L
U
ϕ
~
(
ϕ
(
t
,
n
)
)
)
\tilde{\boldsymbol{\phi}}(t,n)=\text{LayerNorm}\left(\tilde{\boldsymbol{\xi}}_{t+n}+\mathrm{GLU}_{\tilde{\phi}}\left(\phi(t,n)\right)\right)
ϕ~(t,n)=LayerNorm(ξ~t+n+GLUϕ~(ϕ(t,n)))
进入TFD中,数据流进内部3个模块:SEL(Static Enrichment Layer)、TSL(Temporal Self-Attention Layer)和PFL(Position-wise Feed-forward Layer)。进入TFD的数据首先在SEL利用来自静态协变量编码器的特征进行增强,其实就是将前面层的输出
ϕ
~
(
t
,
n
)
\tilde{\boldsymbol{\phi}}(t,n)
ϕ~(t,n)和来自静态协变量编码器的
c
e
\boldsymbol{c}_e
ce两种数据输入到GRN:
θ
(
t
,
n
)
=
G
R
N
θ
(
ϕ
~
(
t
,
n
)
,
c
e
)
\boldsymbol{\theta}(t,n)=\mathrm{GRN}_\theta(\tilde{\boldsymbol{\phi}}(t,n),\boldsymbol{c}_e)
θ(t,n)=GRNθ(ϕ~(t,n),ce)
接着数据进入时序自注意力层TSL,自关注模块可以学习时序数据的长期依赖关系,并提供时序依赖可解释性。在TSL中,主要是可解释性多头自关注层,再加个门控层:
B
(
t
)
=
InterpretableMultiHead
(
Θ
(
t
)
,
Θ
(
t
)
,
Θ
(
t
)
)
B(t) =\text{ InterpretableMultiHead }(\boldsymbol{\Theta}(t),\boldsymbol{\Theta}(t),\boldsymbol{\Theta}(t))
B(t)= InterpretableMultiHead (Θ(t),Θ(t),Θ(t))
I n t e r p r e t a b l e M u l t i H e a d ( Q , K , V ) = H ~ W H H ~ = A ~ ( Q , K ) V W V = { 1 / H ∑ h = 1 m H A ( Q W Q ( h ) , K W K ( h ) ) } V W V , = 1 / H ∑ h = 1 m H Attention ( Q W Q ( h ) , K W K ( h ) , V W V ) , \begin{aligned} &InterpretableMultiHead(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})=\boldsymbol{\tilde{H}}\boldsymbol{W}_{\boldsymbol{H}} \\ \boldsymbol{\tilde{H}}&=\tilde{A}(\boldsymbol{Q},\boldsymbol{K})\boldsymbol{V}\boldsymbol{W}_{V} \\ &=\left\{1/H\sum_{h=1}^{m_H}A\left(\boldsymbol{Q}\boldsymbol{W}_Q^{(h)},\boldsymbol{K}\boldsymbol{W}_K^{(h)}\right)\right\}\boldsymbol{V}\boldsymbol{W}_V, \\ &=1/H\sum_{h=1}^{m_H}\text{ Attention }\left(\boldsymbol{Q}\boldsymbol{W}_Q^{(h)},\boldsymbol{K}\boldsymbol{W}_K^{(h)},\boldsymbol{V}\boldsymbol{W}_V\right), \end{aligned} H~InterpretableMultiHead(Q,K,V)=H~WH=A~(Q,K)VWV={1/Hh=1∑mHA(QWQ(h),KWK(h))}VWV,=1/Hh=1∑mH Attention (QWQ(h),KWK(h),VWV),
δ ( t , n ) = Layer N o r m ( θ ( t , n ) + G L U δ ( β ( t , n ) ) ) \boldsymbol{\delta}(t,n)=\text{Layer}\mathrm{Norm}(\boldsymbol{\theta}(t,n)+\mathrm{GLU}_\delta(\boldsymbol{\beta}(t,n))) δ(t,n)=LayerNorm(θ(t,n)+GLUδ(β(t,n)))
最后数据进入到一个前行传播层PFL,做额外的非线性处理:
ψ
(
t
,
n
)
=
G
R
N
ψ
(
δ
(
t
,
n
)
)
ψ
~
(
t
,
n
)
=
Layer
Norm
(
ϕ
~
(
t
,
n
)
+
GLU
ψ
~
(
ψ
(
t
,
n
)
)
)
\begin{aligned} &\boldsymbol{\psi}(t,n) =\mathrm{GRN}_{\psi}(\boldsymbol{\delta}(t,n)) \\ &\tilde{\boldsymbol{\psi}}(t,n) =\text{Layer}\operatorname{Norm}\Big(\tilde{\boldsymbol{\phi}}(t,n)+\operatorname{GLU}_{\tilde{\psi}}(\boldsymbol{\psi}(t,n))\Big) \end{aligned}
ψ(t,n)=GRNψ(δ(t,n))ψ~(t,n)=LayerNorm(ϕ~(t,n)+GLUψ~(ψ(t,n)))
最终的预测输出是分位数形式的,也就是做的是分位数预测,可以得到一个置信区间:
y
^
(
q
,
t
,
τ
)
=
W
q
ψ
~
(
t
,
τ
)
+
b
q
\hat{y}(q,t,\tau)=\boldsymbol{W}_{q}\tilde{\boldsymbol{\psi}}(t,\tau)+b_{q}
y^(q,t,τ)=Wqψ~(t,τ)+bq
总的来说,就是GRN通过skip connections和gating layers确保有效信息的流动;VSN基于输入,明智地选择最显著的特征。SCE 编码静态协变量上下文向量。TFD学习数据集中的时间关系,里面主要有以下3大模块。
-
SEL(Static Enrichment Layer):用静态元数据增强时间特征。
-
TSL(Temporal Self-Attention Layer):学习时序数据的长期依赖关系并提供为模型可解释性。
-
PFL(Position-wise Feed-forward Layer):对自关注层的输出应用额外的非线性处理。
最后是损失函数方面,文章用了一个分位数损失,将全部分位数预测输出加和:
L
(
Ω
,
W
)
=
∑
y
t
∈
Ω
∑
q
∈
Q
t
m
a
x
Q
L
(
y
t
,
y
^
(
q
,
t
−
τ
,
τ
)
,
q
)
M
τ
m
a
x
Q
L
(
y
,
y
^
,
q
)
=
q
(
y
−
y
^
)
+
+
(
1
−
q
)
(
y
^
−
y
)
+
\begin{aligned}\mathcal{L}(\Omega,\boldsymbol{W})&=\sum_{y_t\in\Omega}\sum_{q\in Q}^{tmax}\frac{QL\left(y_t,\hat{y}(q,t-\tau,\tau),q\right)}{M\tau_{max}}\\QL(y,\hat{y},q)&=q(y-\hat{y})_++(1-q)(\hat{y}-y)_+\end{aligned}
L(Ω,W)QL(y,y^,q)=yt∈Ω∑q∈Q∑tmaxMτmaxQL(yt,y^(q,t−τ,τ),q)=q(y−y^)++(1−q)(y^−y)+
实验
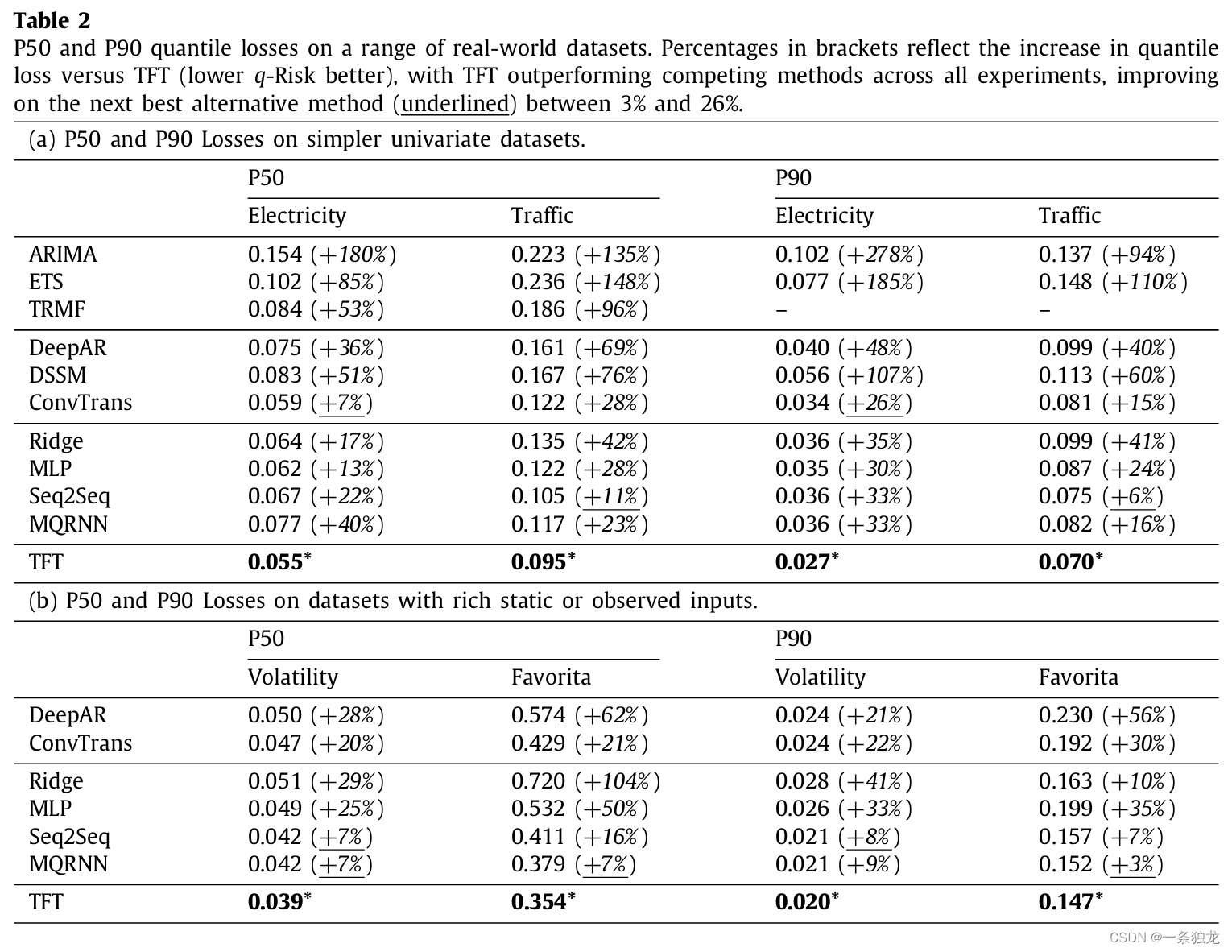
论文1在电力负荷、交通占用率、百货销售和金融波动率数据集上进行了评估实验,TFT明显优于各种基准模型,包括直接方法和迭代方法的模型。还做了消融实验,对门控层、静态协变量编码器、变量选择网络、自注意力层以及seq2seq本地处理层各个模块的贡献进行了验证 。
Table 2展示了TFT与其他方法在P50和P90下的分数位损失对比,明显TFT更好。
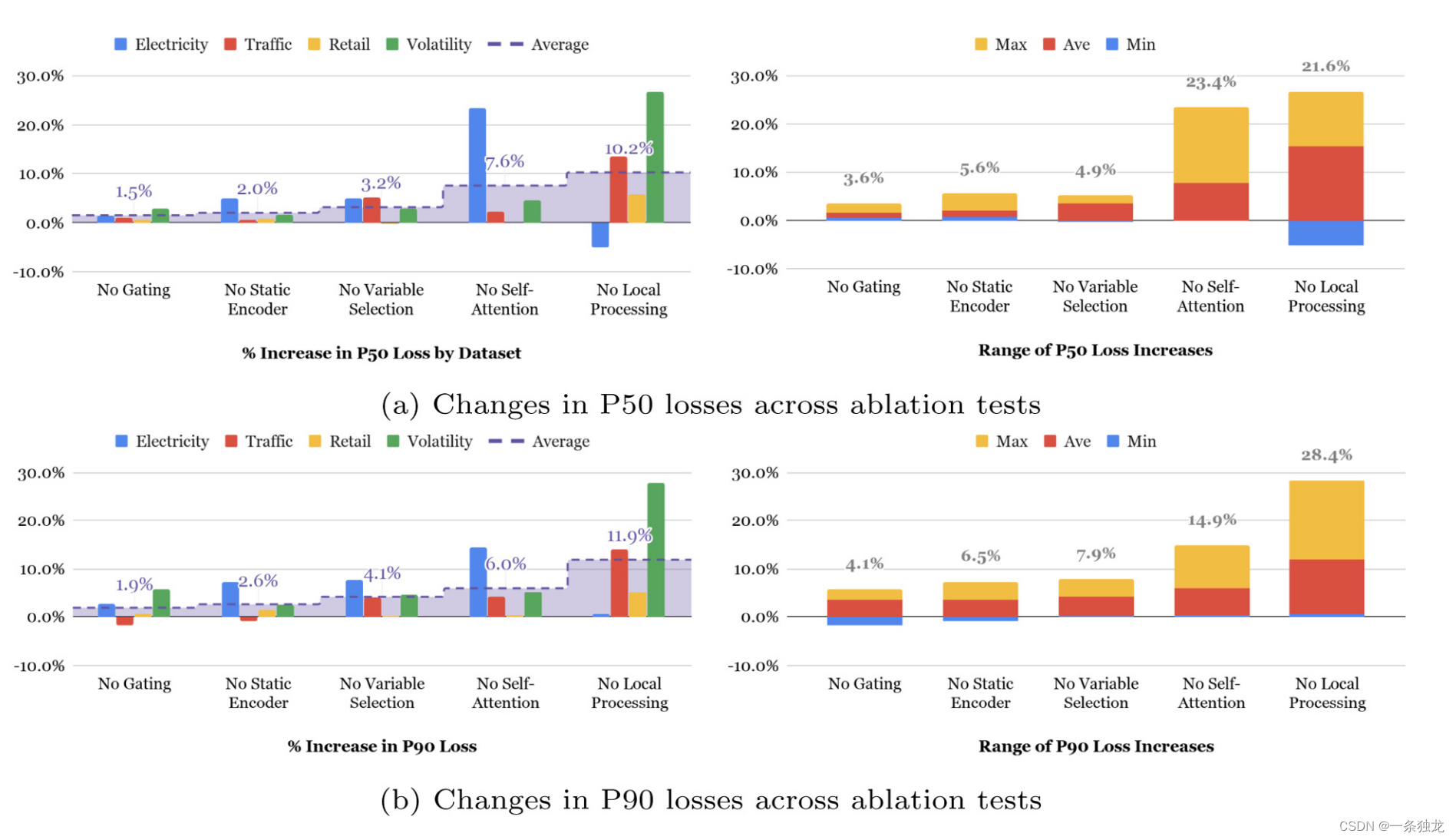
从Fig.3可以看到Self-Attention和Local Processing(LSTM层)贡献最大,但不同数据集上,两者的贡献大小并不绝对,比如对于Traffic数据集,Local Processing更重要,作者认为是Traffic数据集得目标历史观测值更重要,所以Local Processing发挥了更大的作用。而对于Eelectricity数据集,Self-Attention更重要,作者认为是电力的周期性明显,hour-of-day特征甚至比预测目标Power Usage的历史观测值更重要,所以自关注发挥作用更大。
论文2使用了论文1的模型方法在电负荷数据上进行了评估,这里一并介绍。论文2使用过去的用电数据、日历数据、天气数据和疫情数据作为模型输入。使用TFT、LSTM和ARIMA进行对比。TFT使用独立的变量选择网络连接不同类型的输入特征。对整个电网层级进行预测,及在变电站层级进行预测后汇总到电网层级。
- 数据集:使用德国本地电网运营商提供的数据(2019-2021年)和GEFCOM2012竞赛公开数据集(美国20个电网区域,2004-2007年)。
- 超参数优化:使用随机搜索找到TFT和LSTM的最佳超参数
- 评价指标:RMSE、MAPE和SMAPE。
- 实验设置:预测时间范围(day-ahead和week-ahead)、特征组合(用电+日历、用电+天气+日历等)、预测层级(电网级别、变电站级别)。
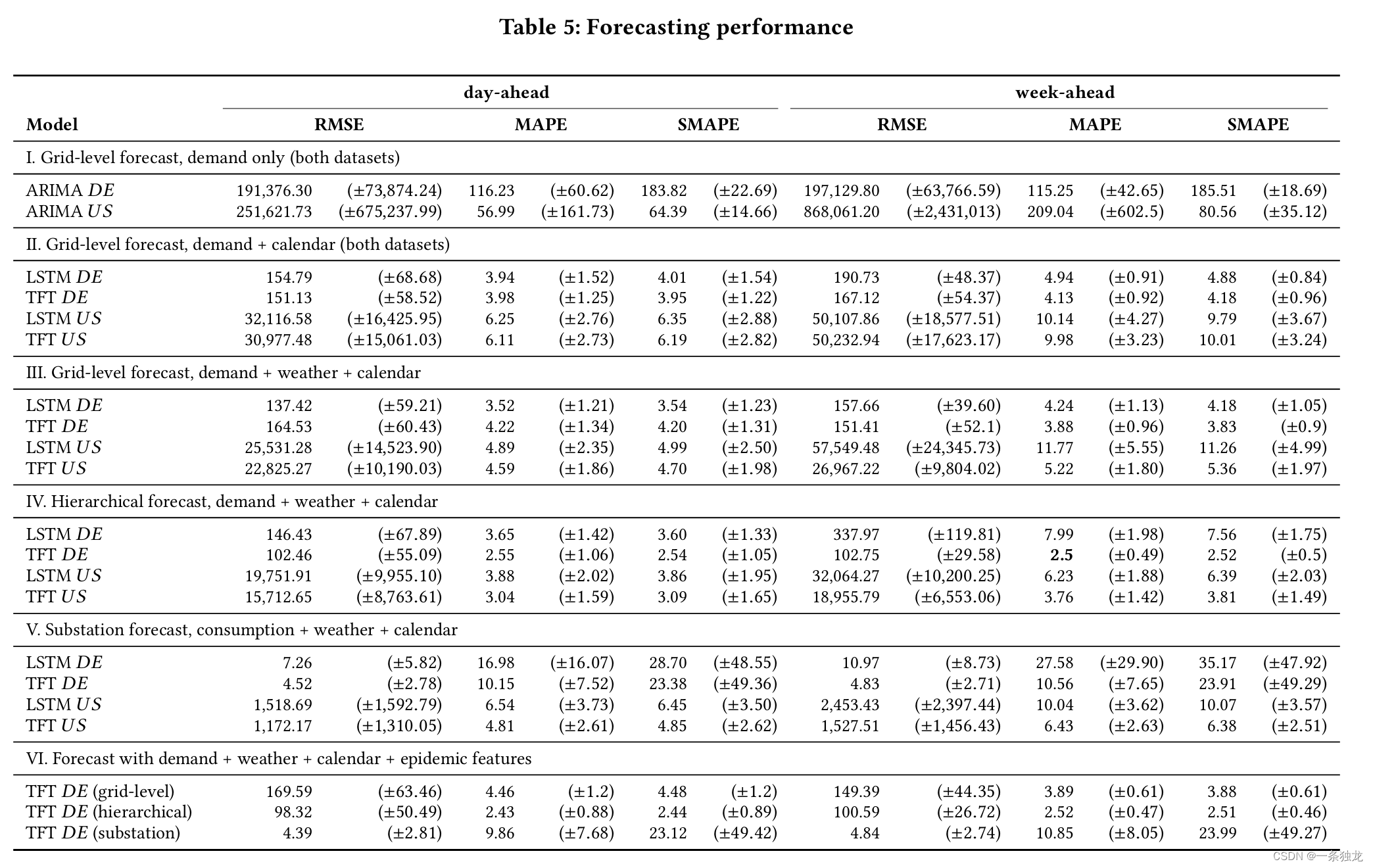
根据实验结果可以得到以下结论:
- TFT在week-ahead预测中明显优于LSTM,但在day-ahead预测中两者效果相近
- 分层预测可以提升电网级别的预测性能。在变电站级别预测后汇总到电网级别,TFT的MAPE为2.43%(day-ahead)和2.52%(week-ahead)
- 增加天气、日历等外生特征可以提升预测准确度
- TFT有望成为电力负荷短期预测的有效方法,但计算成本较高,未来可探索不同电网层级的预测以发挥TFT的优势
个人思考
- 我们知道对时序数据分析时常常做ACF和PACF图来分析时序的自相关性和偏自相关性,从而可以提取高相关性时点用于手工做特征工程。其实论文1中不管是用LSTM的Local Processing层还是用自注意力的TFD层,都能很好地去对时序数据进行自动编码和特征提取,特别是自注意力,可以很好捕捉时序数据的自相关性。因此将Transformer用在时序预测可以说是非常合适的。
- 论文1中的变量选择网络VSN对于减少手工特征分析设计很有帮助,因为电负荷预测做特征工程可能需要手工去对每各变量去算相关性,分析变量之间、变量与目标数据的相关性这些,再根据经验手工选择变量作为模型输入。因此这个变量选择网络的实用性,不论是不是TFT方法,在别的模型中也可以考虑去使用。
- TFT作为基于Transformer的方法,依然没有很好避免计算成本高的问题。虽然论文1中说电力负荷预测的部分最优模型用V100只训练了6小时点多一点,但考虑到实践中如果要定期用新数据更新模型的话,计算成本问题仍然是不可忽视的。
引用
Lim, Bryan, et al. “Temporal fusion transformers for interpretable multi-horizon time series forecasting.” International Journal of Forecasting 37.4 (2021): 1748-1764. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Giacomazzi, Elena, Felix Haag, and Konstantin Hopf. “Short-Term Electricity Load Forecasting Using the Temporal Fusion Transformer: Effect of Grid Hierarchies and Data Sources.” arXiv preprint arXiv:2305.10559 (2023). ↩︎ ↩︎ ↩︎ ↩︎
















 4326
4326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











