







阅读笔记 - RedTE: Mitigating Subsecond Traffic Bursts with Real-time and Distributed Traffic Engineering
阅读论文:
- Gui F, Wang S, Li D, et al. RedTE: Mitigating subsecond traffic bursts with real-time and distributed traffic engineering[C]//Proceedings of the ACM SIGCOMM 2024 Conference. 2024: 71-85.
背景与动机
网络流量具有突发性,这能带来时延和丢包方面的问题。而传统TE往往是中心化和大时间范围的,这引出了控制循环时延问题,使得处理分钟级甚至小时级粒度的TE方案不能及时应对毫秒级的突发流量。因此文章希望利用分布式流量工程(dTE)减少中心化流量工程中的信息收集和规则表更新的时间,从而缓解总体的控制循环时延问题;同时由于LP-based TE方案存在计算复杂度问题,因此文章希望通过Distributed ML-based TE方案,即多智能体强化学习(MARL)直接令router通过本地信息进行决策,大大减少控制循环时延。
控制循环时延:TE系统运行的控制循环中通常存在三个阶段,即收集信息、计算以及更新规则表,均会引入时延。其中收集信息阶段通常会收集流量需求信息(例如全局的流量矩阵或路由器局部的流量需求向量)。
突发流量及其缓解机制
由于应用本身的突发性质、TCP拥塞控制和网络栈的批量操作等,流的发送率可能短时间(10-100毫秒)内剧烈增加,引发路由器处理队列累积,影响延迟敏感型应用。
有两种传统缓解机制,对ISP而言都不够有效,ISP需要具备全局流量信息视野且对传输层与应用层透明的突发流量缓解方案。
- 终端主机机制:位于传输层或应用层,采取在路径拥塞前提前调整终端主机发送速率的方式
- 设备本地流量管理器:可以在多条路径上分配流量以防止链路过载。但会忽略全局流量模式而陷入局部最优
基于线性规划的TE系统
TE问题常被形式化为MCF问题,例如Gurobi这种全局线性规划求解器是其经典求解方法。通常使用MLU衡量TE算法性能。
优缺点:
- 具有很强的理论TE性能表现
- 控制循环时延长,特别是计算环节时延会随着网络规模增大而急剧增大
基于机器学习的TE系统
强化学习在基于机器学习的TE系统中广泛应用。TE问题也可被建模为CMAS任务,让每个agent协作学习,分布式部署,从而可以利用局部性共同实现全局最优。现有CMAS-based TE方案存在两个主要问题:
CMAS: Cooperative Multi-Agent System,合作型多智能体系统,基于多智能体强化学习,系统中每个智能体自主学习,并与其他智能体合作达到全局目标。(另一种MAS是竞争型多智能体系统)
-
学习不稳定问题:CMAS在实际部署中可能产生不协作现象,因为现有MARL算法无法准确评估单个agent动作对全局目标的贡献,也就是没有很好的奖励函数来作衡量,并平衡局部和全局目标。
-
忽视信息收集时延和规则表更新时延的问题:机器学习往往有训练和推理两大部分,其中训练耗时多但可离线进行,而推理阶段相对全局线性规划则非常快速。但在TE中减少了计算时延仍然有另外两部分时延成为TE的时延瓶颈。
模型与方法
假设:
- ISP控制WAN路由器但不控制终端主机,本文方法RedTE的输入是从路由器数据平面收集的流量计数
- RedTE与控制平面其他协议如
BGP和RSVP正交。因此已经给定候选路径,TE系统只需决定候选路径间的流量分配比例 - 假设每个OD对间有 k k k个候选路径( k ≥ 1 k\geq1 k≥1)
Overview :
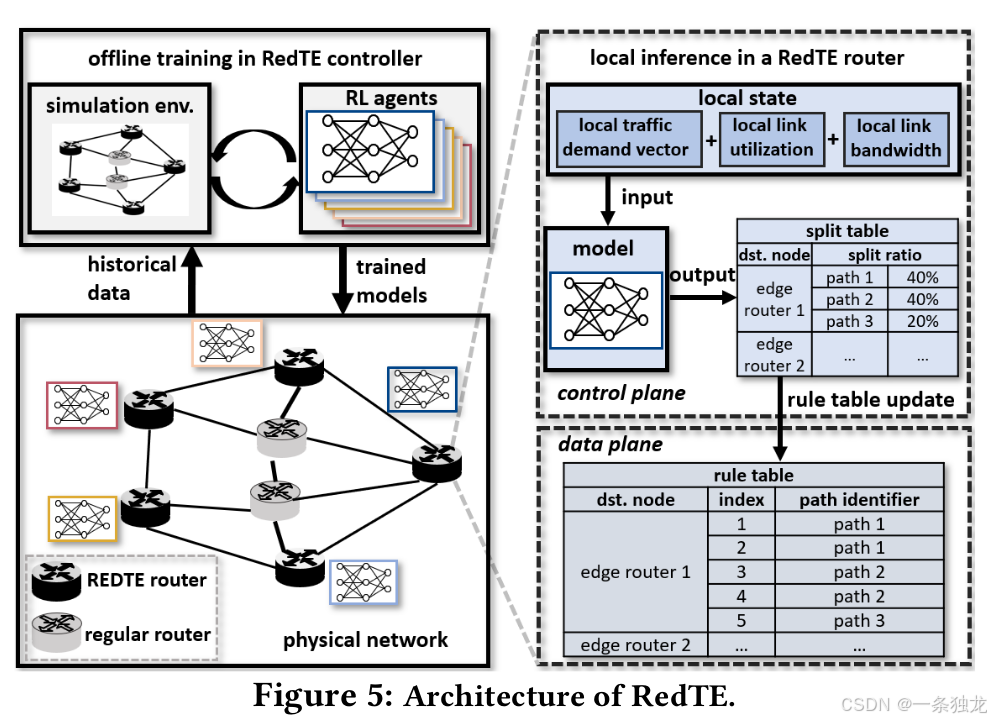
整个RedTE系统分为控制器和边缘路由器组成的物理网络两大部分,是一个简单的云边协同场景。其中控制器在模拟环境中定期利用物理网络收集的历史数据离线训练MARL agents。而边缘路由器则持续收集流量需求数据并上传到控制器,并定期从控制器下载训练好的RL模型用于在线推理;物理网络是一个SDN,每个RedTE路由器在控制层面通过将局部流量需求向量、局部链路利用情况和局部链路带宽信息输入RL模型,独立地计算并输出到每个目的点的路径分配比率,并更新到数据平面的规则表中。
核心算法 :
控制器部分:采用属于Actor-Critic RL的multi-agent deep deterministic policy gradient (MADDPG)算法来训练agents。其中全局critic网络获取模拟网络环境的全局信息作为状态,以多个actor网络输出拼接的动作(路径划分比率)为动作输入,计算动作价值 Q ( s , a ) Q(s,a) Q(s,a)用于actor网络进行策略梯度更新;而每个actor则只获取模拟网络环境中各自负责路由器的局部信息(流量需求向量、链路利用率、链路带宽)作为状态输入,并训练策略网络计算相应动作(即路径流量分配比率)。
可以推断参数为 θ i \theta_i θi的actor网络 μ i \mu_i μi的策略梯度更新公式为:
∇ θ i J ( μ i ) = E x , a ∼ D [ ∇ θ i μ i ( a i ∣ o i ) ∇ a i Q
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











