







GIL
概述:
GIL(Global Interperter Lock) 称作全局解释器锁.我们所讲的GIL并不是Python语言的特性,它是在实现Python解释器时引用的概念.GIL只在CPython解释器上存在。
GIL和线程互斥锁的区别:
GIL是在CPython应用程序层面的锁,为了解决解释器中多个线程的竞争资源问题。
线程互斥锁是在Python代码层的锁,为了解决Python程序中多线程的竞争共享资源问题。
计算密集型程序:
计算密集型任务的特点是要进行大量的计算,消耗CPU资源。
GIL与计算密集型程序的关系:
Python 中的多线程不适合计算密集型的程序。如果程序需要大量的计算,利用多核CPU资源,可以使用多进程来解决。
IO密集型程序:
涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。
GIL对IO密集型程序的关系
GIL锁遇到IO等待时,会释放GIL锁, 可以提高Python中IO密集型程序的效率。
GIL对程序产生的影响
GIL的存在无法充分利用多核CPU, Python中的同一时刻只有一个线程会执行。
如何改善GIL对程序产生的影响:
因为 GIL 锁是解释器层面的锁,无法去除 GIL 锁在执行程序时带来的问题, 只能去改善。
- 更换更高版本的解释器
- 更换解释器 Python为了
- 解决程序使用多核问题, 使用多进程代替多线程
深拷贝浅拷贝
概述:
在开发过程中防止数据被修改,就需要传递一个副本,即使副本被修改也不会影响原数据使用,为了生成这个副本,就产生了拷贝.
相关技术点回顾:
1.Python中一切皆对象
2.不可变对象 : int, str, tuple 等
3.可变对象: list, set, dict, 等
4.引用
Python中每个对象都会在内存中开辟一块空间保存该对象,该对象在内存中所在位置的地址称为引用.——— 变量名实际就是对象的地址的引用
引用赋值
赋值的本质就是让多个变量同时引用同一个对象的地址.
1.不可变对象的引用赋值
在不可变对象赋值时,不可变对象不会被修改,所以会开辟一个新的空间.
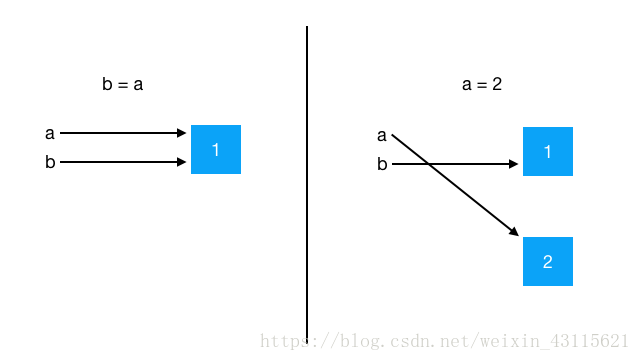
a = 1
b = a
# a, b的值相同
print(a, b)
# 因为a, b都是 1 的引用,所以a 和 b 的引用相同
print(id(a), id(b))
a = 2
# 因为a 引用的是不可变对象,所以不能修改 1,只能再开辟一个新空间来保存 2,但是 b 还在引用 1
print(a, b)
# 因为引用的对象发生了变化 ,所以a,b的引用也发生了变化
print(id(a), id(b))输出结果:
1 1
4305275264 4305275264
2 1
4305275296 4305275264程序原理图:
2.不可变对象的引用赋值
在可变对象中,保存的并不是真正的对象数据,而是对象的引用.对可变对象进行修改时,只是将可变对象中保存的引用进行修改.
l1 = [1, 2, 3]
l2 = l1
# l1, l2的数据相同
print(l1, l2)
# 因为 l1,l2 都是列表的引用,所以 l1 和 l2 的引用相同
print(id(l1), id(l2))
l1[0] = 11
# 因为 l1, l2 是引用同一个列表,所以在修改 l1 中的数据时,l2 也随之发生变化
print(l1, l2)
# 因为并没有改变 l1, l2 的引用,所以引用地址不会变化
print(id(l1), id(l2))输出结果 :
[1, 2, 3] [1, 2, 3]
4355926728 4355926728
[11, 2, 3] [11, 2, 3]
4355926728 4355926728程序图解:

函数在传递参数时,实际上就是实参对形参的赋值,如果实参是可变对象,那么就可以在函数的内部修改传入的数据。
浅拷贝
单层次拷贝,只拷贝顶层的引用. copy()函数在拷贝对象时,只是将指定对象中的所有引用拷贝了一份.
copy.copy()
不可变类型
不可变类型的浅拷贝与赋值没有区别, 不可变对象不会被修改,所以修改时会开辟一个新的空间.
可变类型
简单一些的数据比对:
import copy
# 创建一个可变对象
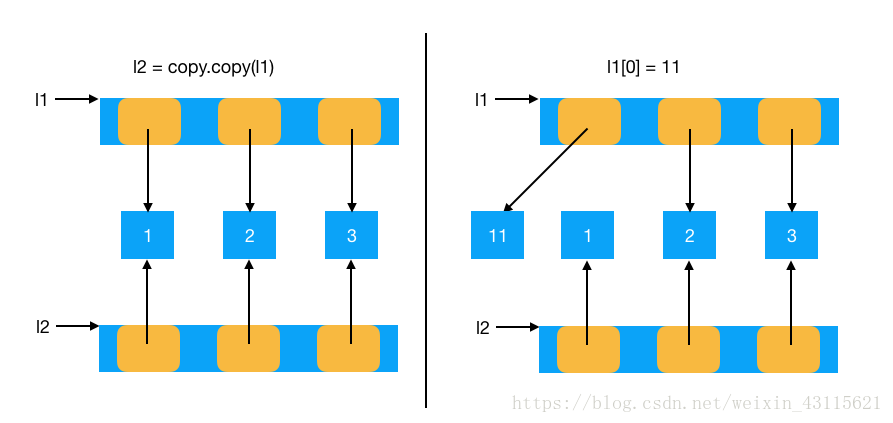
l1 = [1, 2, 3]
# 拷贝 l1 对象,生成副本 l2
l2 = copy.copy(l1)
# l1 和 l2 的值完全相同
print(l1, l2)
# 但是 l1 和 l2 的引用不同,说明拷贝成功
print(id(l1), id(l2))
# 华丽的分割线
print('*'*20)
# 修改 l1 中的数据
l1[0] = 11
# l1 修改后, l2确实没有随着发生变化
print(l1, l2)
print(id(l1), id(l2))输出结果:
[1, 2, 3] [1, 2, 3]
4356975496 4356975752
********************
[11, 2, 3] [1, 2, 3]
4356975496 4356975752程序原理图:
复杂一些的数据比对:
import copy
# 创建一个可变对象a
a = [1, 2]
# 创建一个可变对象 l1 中包含可变对象 a
l1 = [3, 4, a]
# 拷贝 l1 对象,生成副本 l2
l2 = copy.copy(l1)
# l1 和 l2 的值完全相同
print(l1, l2)
# l1 和 l2 的引用不同,说明拷贝成功
print(id(l1), id(l2))
# 华丽的分割线
print('*'*20)
# 修改 a 中的数据
a[0] = 11
# a中的数据修改后, l1,l2也发生了变化
print(l1, l2)
print(id(l1), id(l2))输出结果:
[3, 4, [1, 2]] [3, 4, [1, 2]]
4365364360 4365364616
********************
[3, 4, [11, 2]] [3, 4, [11, 2]]
4365364360 4365364616程序原理图:
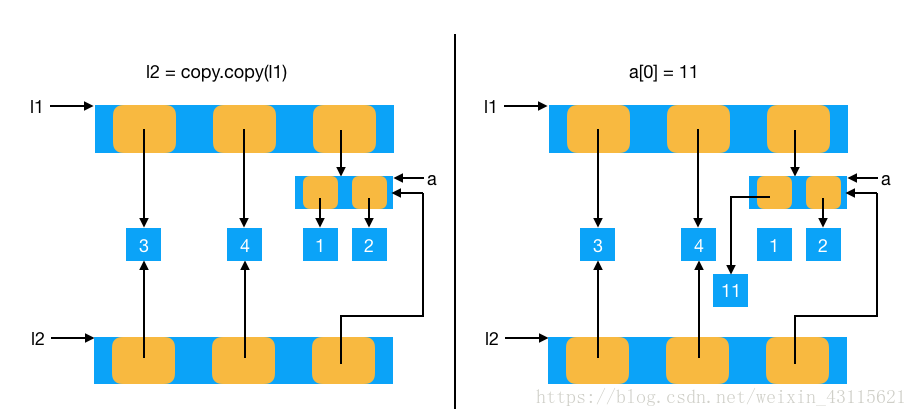
可变类型的浅拷贝,并没有真正的解决数据传递后,数据被改变的问题,复杂的对象进行拷贝时,如果里面含有一个可变对象的话,数据还是会被改变。
深拷贝
应用deepcopy()函数进行逐层进行拷贝引用,知道所以的引用都是不可变引用为止.解决了数据在传递时,不想被修改的问题.
import copy
# 创建一个可变对象a
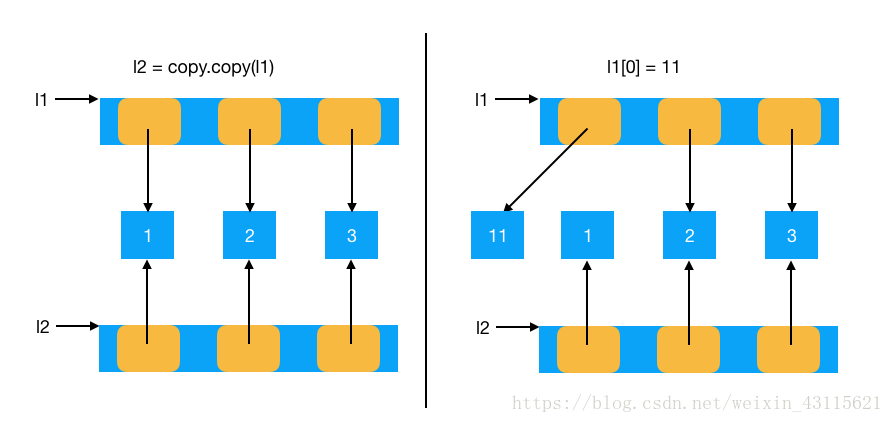
a = [1, 2]
# 创建一个可变对象 l1 中包含可变对象 a
l1 = [3, 4, a]
# 拷贝 l1 对象,生成副本 l2
l2 = copy.deepcopy(l1)
# l1 和 l2 的值完全相同
print(l1, l2)
# l1 和 l2 的引用不同,说明拷贝成功
print(id(l1), id(l2))
# 华丽的分割线
print('*'*20)
# 修改 a 中的数据
a[0] = 11
# a中的数据修改后, 因为l2 逐层的拷贝了所有的引用,所以l2不会发生变化
print(l1, l2)
print(id(l1), id(l2))输出结果:
[3, 4, [1, 2]] [3, 4, [1, 2]]
4364205192 4364205448
********************
[3, 4, [11, 2]] [3, 4, [1, 2]]
4364205192 4364205448程序原理图:
但是大多数的情况下,我们并不希望这样,反而希望数据可以被修改,以达在函数间共享数据的目的。
浅拷贝的几种应用方式
一. copy 模块的 copy 方法
import copy
a = [1, 2]
l1 = [3, 4, a]
l2 = copy.copy(l1)
print(l1, l2)
print(id(l1), id(l2))
print('*'*20)
a[0] = 11
print(l1, l2)
print(id(l1), id(l2))输出结果:
[3, 4, [1, 2]] [3, 4, [1, 2]]
4365364360 4365364616
********************
[3, 4, [11, 2]] [3, 4, [11, 2]]
4365364360 4365364616二. 对象本身的 copy 方法
a = [1, 2]
l1 = [3, 4, a]
l2 = l1.copy()
print(l1, l2)
print(id(l1), id(l2))
print('*'*20)
a[0] = 11
print(l1, l2)
print(id(l1), id(l2))输出结果:
[3, 4, [1, 2]] [3, 4, [1, 2]]
4364204936 4364205192
********************
[3, 4, [11, 2]] [3, 4, [11, 2]]
4364204936 4364205192三. 工厂方法
a = [1, 2]
l1 = [3, 4, a]
l2 = list(l1)
print(l1, l2)
print(id(l1), id(l2))
print('*'*20)
a[0] = 11
print(l1, l2)
print(id(l1), id(l2))输出结果:
[3, 4, [1, 2]] [3, 4, [1, 2]]
4363156360 4363180744
********************
[3, 4, [11, 2]] [3, 4, [11, 2]]
4363156360 4363180744四. 切片
a = [1, 2]
l1 = [3, 4, a]
l2 = l1[1:]
print(l1, l2)
print(id(l1), id(l2))
print('*'*20)
a[0] = 11
print(l1, l2)
print(id(l1), id(l2))[3, 4, [1, 2]] [4, [1, 2]]
4355816328 4355816584
********************
[3, 4, [11, 2]] [4, [11, 2]]
4355816328 4355816584浅拷贝的优势
时间角度,浅拷贝花费时间更少
空间角度,浅拷贝花费内存更少
效率角度,浅拷贝只拷贝顶层数据,一般情况下比深拷贝效率高。
模块导入

import module
import BB
BB.show()import package.module
import MyModules.AA
MyModules.AA.show()from module import 成员
from BB import show
show()from package import module
from MyModules import AA
AA.show()from package.module import 成员
from MyModules.AA import show
show()模块别名 as
如果模块名过长不方便使用,可以用as 给模块起个别名. 编写代码时可以直接使用别名代替.
import MyModules.AA as MMAA
MMAA.show()模块搜索路径
sys 模块中有一个 path 变量,记录了程序在导入模块时的查找位置。
import sys
print(sys.path)模块的搜索顺序是:
- 当前程序所在目录
- 当前程序根目录
- PYTHONPATH
- 标准库目录
- 第三方库目录site-packages目录
path 变量本质就是一个列表,使用 append() 方法可以将新路径加入到 path 中也可以使用 insert 方式添加
重新加载模块
重新加载模块需要使用 imp 模块下的 reload 函数
import 和 from-import 导入的使用区别
import 方式
可以将 import 导入方式理解成浅拷贝,只是拷贝了模块的一个引用。通过引用可以使用所有的数据 。
from-import 方式
from-import 方式在导入数据时:
- 会将导入模块中数据复制一份到当前文件中,可以直接使用模块中的变量,函数,类等内容。
- 文件内私有属性 _xxx 形式的数据不会被导入。
- 如果模块内和当前文件中有标识符命名重名,会引用命名冲突,当前文件中的内容会覆盖模块的数据.
from-import 方式可以理解成深拷贝,被导入模块中的数据被拷贝了一份放在当前文件中。
_all_ 魔法变量
Python 中还提供种方式来隐藏或公开数据 ,就是使用 all
all 本质是一个列表,在列表中以字符串形式加入要公开的数据
小结
从使用便利的角度,使用from-import
从命名冲突的角度,使用 import














 9065
9065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









