







目录
一、第一阶段——变分推断及相关知识
(一)神经网络的3种分类
- 分类神经网络
- 生成神经网络(GAN)
- VAE(上一层的生成并不是下一层的输入,而是进行重采样之后,再输入到下一层。即中间的输入又是一个随机的)
(二)根据P_data、P_G是否可求划分的的3种距离计算
1. 均可求:直接用交叉熵。
熵(Entropy) 被用于描述一个系统中的不确定性:
(1)信息熵:
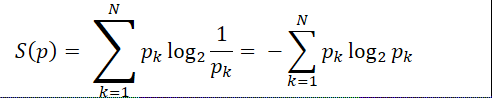
(2)交叉熵:
①含义:基于非真实分布下采用的非最优策略消除系统的不确定性所付出努力的大小。
②适用:给定分布。
③公式:
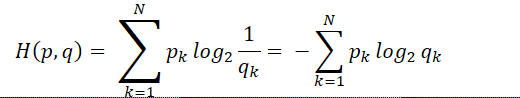
④交叉熵越小,说明该非真实分布越好,即越接近真实分布。
⑤交叉熵>=熵
最低的交叉熵就是,使用真实分布(最优策略)计算的信息熵。此时
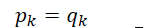
信息熵 = 交叉熵
(3)相对熵(即KL_Divergence)
①含义:衡量两个取值为正的函数or概率分布之间的差异
②公式:
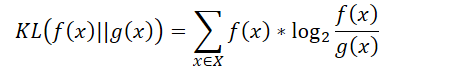
③判断某个策略和最优策略之间的差异:
相对熵 = 某个策略的交叉熵 - 真实分布的信息熵,即
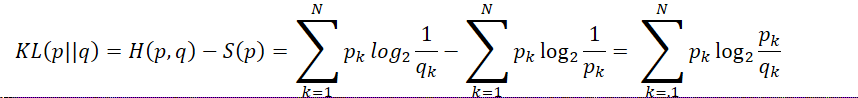
2. P_data不可求、P_G可求:max 最大似然L = ∏P_G(Xi; θ) or min KL-Divergence(有方向的,即i到j的距离不等于j到i的距离)。
3. 均不可求:GAN,JS-Divergence(无方向,即i到j的距离等于j到i的距离)。
(三)交叉熵为什么可以用来计算代价?
取自:https://www.zhihu.com/question/65288314

(四)变分推断
(GAN、VAE、AAE、ALI他们的本质都是可以用变分推断出来的。)
假设x为显变量,z为隐变量。p ̃(x)为x的证据分布,并有
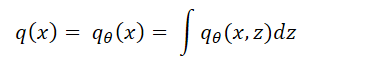
我们希望q_θ(x)能逼近p ̃(x)。
一般情况下我们会去最大化似然函数,这也等价于最小化KL散度KL(p ̃(x) || q(x)),但是由于积分可能很难计算,因此大多数情况下难以直接优化。
所以我们采用变分推断:
首先引入联合分布p(x, z),使p ̃(x) = ∫ p(x, z)dz。
(引入联合分布是因为在很多情况下,联合分布的KL散度比边缘分布的KL散度更容易计算。)
变分推断的本质是将边缘分布的KL(p ̃(x) || q(x))改为联合分布的KL(p(x, z) || q(x, z))或KL(q(x, z) || p(x, z)):

上述式子得:
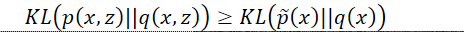
因此可知联合分布的KL散度是一个比边缘分布的KL散度更强的条件。
所以一旦优化成功,我们就得到 q(x, z) -> p(x, z),再 ∫ q(x, z)dz -> ∫ p(x, z)dz = p ̃(x)。即 ∫ q(x, z)dz成为真实分布 p ̃(x) 的一个近似。
(五)GAN学习推进方向:GAN ——> WGAN ——> WGAN-GP
- GAN的问题:GAN的损失函数无法使两个分布重合,会出现生成图片完全失败的情况(比如,我要生成手写数字,但生成器生成的是黑色的图片,完全与手写数字无关)。
- WGAN的问题:生成的图片两极分化。
- WGAN-GP:解决了两极分化的问题,产生了中间的插值。
(六)目标
- 自己能推导 P_data、P_G是否可求的三种计算
- 形成报告:让别人也听懂。
二、第二阶段——变分推断下的GAN
(一)变分推断下的GAN
三、第三阶段——VAE《变分自编码器(一)》
(一)VAE初现
-
首先我们假设的是p(Z|X)后验分布是正态分布。
-
给定一个真实样本X_k,我们假设一个“ 专属于 ”X_k的分布p(Z|X_k)。为什么要强调“ 专属 ”?因为我们后面要训练一个生成器X=g(Z),希望能把从p(Z|X_k)采样出来的Z_k还原回X_k。现在p(Z|X_k)专属于X_k,我们就有理由说这个采样出来的Z_k应该要还原到X_k中去。
它在论文中的体现:

上述式子表明q(z|x_i)是正态分布 -
那我们怎么找出专属于X_k的正态分布p(Z|X_k)的均值和方差呢?那我们就用神经网络拟合出来把!于是我们构造两个神经网络 μ_k = f1(X_k) 和 log (σ_k)^2 = f2(X_k)
(我们选择拟合log (σ_k)^2 是因为(σ_k)^2总是非负的,需要加激活函数,而log (σ_k)^2可正可负,不需要加激活函数。)
这样我们就知道专属于X_k的均值和方差了,也就知道p(Z|X_k)的分布长什么样了。
-
从p(Z|X_k)这个专属分布中采样Z_k出来,然后经过生成器X ̂_k = g(Z_k),现在我们就可以放心地最小化D(X ̂_k, X_k)^2(这个表示某种距离)。
(二)分布标准化
-
生成器X ̂_k = g(Z_k)希望重构X,也就是最小化D(X ̂_k, X_k)^2,但重构的过程受噪声(即方差)的影响。此时模型为了使重构的好,就会想办法让方差为0,但方差为0的话,就是一个定值(即均值)了,失去了随机性,没有随机性就不再是一个变分了,就退化成了一个autoencoder。
我们的解决方法是,使所有的p(Z|X)都接近于标准正态
分布N(0, 1),这就防止了噪声(σ_k)^2为零。 -
那怎么让所有的p(Z|X)都接近于标准正态
分布N(0, 1)呢?最直观的方法就是在生成器的重构误差中加入额外的loss。我们使用KL(N(μ, σ^2) || N(0, 1))作为额外的loss,计算结构为:
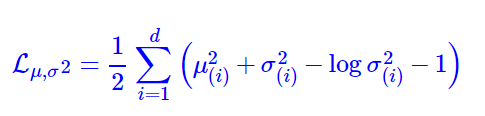
该式子的推导如下:

网络结构:

(三)重参数技巧
- 我们从p(Z|X_k)中采样一个Z_k出来,尽管我们知道p(Z|X_k)是正态分布,但是均值方差都是靠模型算出来的。我们要优化均值方差的模型时,由于“采样”这个操作是不可导的,而采样的结果是可导的。故我们利用

故,从 N(μ, σ^2) 中采样一个Z就相当于从 N(0, 1) 中采样一个ε,然后让Z = μ + ε × σ。

于是我们将从 N(μ, σ^2)中采样变成了从N(0, 1) 中采样,然后通过参数变换得到从中 N(μ, σ^2) 采样的结果。
这样,我们就可以用 “采样” 的结果而不是 “采样” 这个操作做梯度下降了。
四、第四阶段
(一)目标
搞明白下面变种一、变种二的GAN原理
{y_i}:真实数据集
{z_i}:另一个数据集
变种一:把真实的数据集和另一个数据集一起输入生成器
变种二:只把真实数据输入生成器
要搞清楚其中的数学推理,搞清楚为什么直接把{y_i}输入到生成器中不会让生成器退化成 encoder?这期中是做了什么样的变换?
















 4946
4946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









