







 本文介绍了PyTorch中Variable(现已更改为Tensor)的requires_grad属性及其作用,当设置为True时,会记录计算图以进行反向传播。另外,介绍了在0.4版本后移除的volatile属性,现在可以使用with torch.no_grad()来关闭梯度计算,提高推断速度并节省显存。在不需要反向传播的场景下,这个特性非常有用。
本文介绍了PyTorch中Variable(现已更改为Tensor)的requires_grad属性及其作用,当设置为True时,会记录计算图以进行反向传播。另外,介绍了在0.4版本后移除的volatile属性,现在可以使用with torch.no_grad()来关闭梯度计算,提高推断速度并节省显存。在不需要反向传播的场景下,这个特性非常有用。
区别:
| 显存 | 计算图贡献 | 用途 | |
| with torch.no_grad() | 低显存占用 | 该链路不会对计算图的产生贡献 | 用于推理过程中 |
| requires_grad ==False | 高显存占用 | 该链路会对计算图的产生贡献 | 用于推理过程中,有时候也用于训练 |
一、with torch.no_grad()
影响:导致主模型不会根据这个链路向上更新参数(该链路中的模型不会对计算图产生贡献),with torch.no_grad()里面的模型的参数也不会更新
在这个下面进行运算得到的tensor没有grad_fn,也就是它不带梯度(因为没有上一级的函数),因此loss无法从这些tensor向上传递,产生这些tensor的网络的参数将不会更新。下面这种情况一般使用with torch.no_grad():
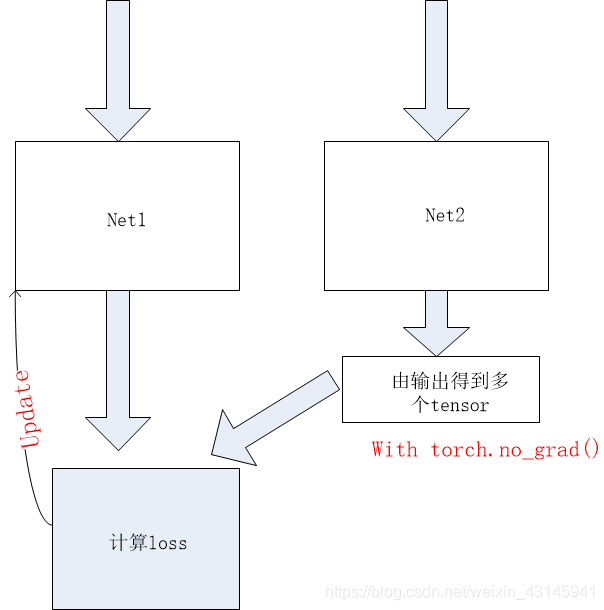
这里我们只是使用了net2的输出来计算loss,而不想让loss去更新net2的网络参数,于是使用with torch.no_grad(),这样loss就被阻断了在loss.backward过程中,而net1却正常计算网络参数梯度。
二、.requires_grad ==False
影响:导致主模型会根据这个链路向上更新参数(保证了该链路中该模型对计算图产生贡献),requires_grad ==False里面的模型的参数不会更新
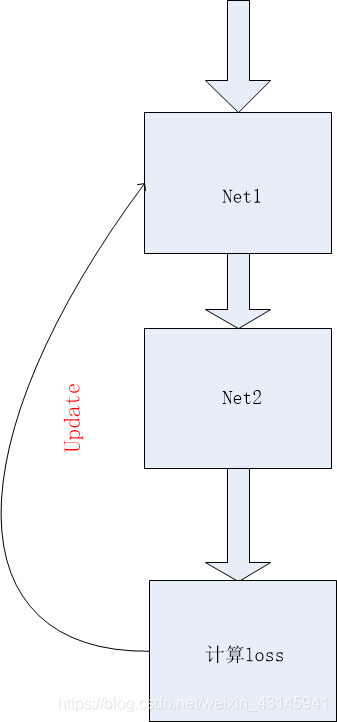
这里我们只想通过loss更新net1,net2不想更新,还能通过with torch.no_grad()实现吗?答案是否定的,一旦使用就阻断了loss流动,那怎么办?如下:
for p in net2.parameters():
p.requires_grad = False这样不在去计算net2的网络权重w的梯度,而只是使用它的值去计算net1的梯度。
怎么看模型的requires_grad 是不是False?
只需要将vae改为你的模型名称即可:
1、一键查看是否所有的参数不需要梯度:
# 检查 VAE 模型中所有参数的 requires_grad 状态
all_frozen = all(param.requires_grad == False for param in vae.parameters())
if all_frozen:
print("All parameters in VAE are frozen (requires_grad is False).")
else:
print("Some parameters in VAE require gradients (requires_grad is True).")
2、具体查看哪些参数需要梯度:
# 检查 VAE 的参数是否需要梯度
for name, param in vae.named_parameters():
print(f"Parameter: {name}, requires_grad: {param.requires_grad}")
什么时候该用with torch.no_grad()?什么时候该用.requires_grad ==False?_loss中的变量是不是都需要requires grad-CSDN博客



















 49
49

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











