







在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
混淆矩阵要表达的含义:
每一行之和表示该类别的真实样本数量,每一列之和表示被预测为该类别的样本数量。

True Positive(TP):真正类。样本的真实类别是正类,并且模型识别的结果也是正类。
False Negative(FN):假负类。样本的真实类别是正类,但是模型将其识别为负类。
False Positive(FP):假正类。样本的真实类别是负类,但是模型将其识别为正类。
True Negative(TN):真负类。样本的真实类别是负类,并且模型将其识别为负类。
样例总数 = TP + FP + TN + FN
该矩阵可用于易于理解的二类分类问题,但通过向混淆矩阵添加更多行和列,可轻松应用于具有3个或更多类值的问题。
主对角线上的元素代表每个类别正确分类的数量,所以一般直接看主对角线上的值就行了
代码实现:
pip install scikit-learn matplotlib
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 生成一些示例的真实标签和预测标签
true_labels = [1, 0, 1, 1, 0, 1, 0, 0]
predicted_labels = [1, 0, 0, 1, 0, 1, 0, 1]
# 使用scikit-learn计算混淆矩阵
cm = confusion_matrix(true_labels, predicted_labels)
# 使用seaborn绘制混淆矩阵的热力图
sns.heatmap(cm, annot=True, cmap="Blues", fmt='g')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
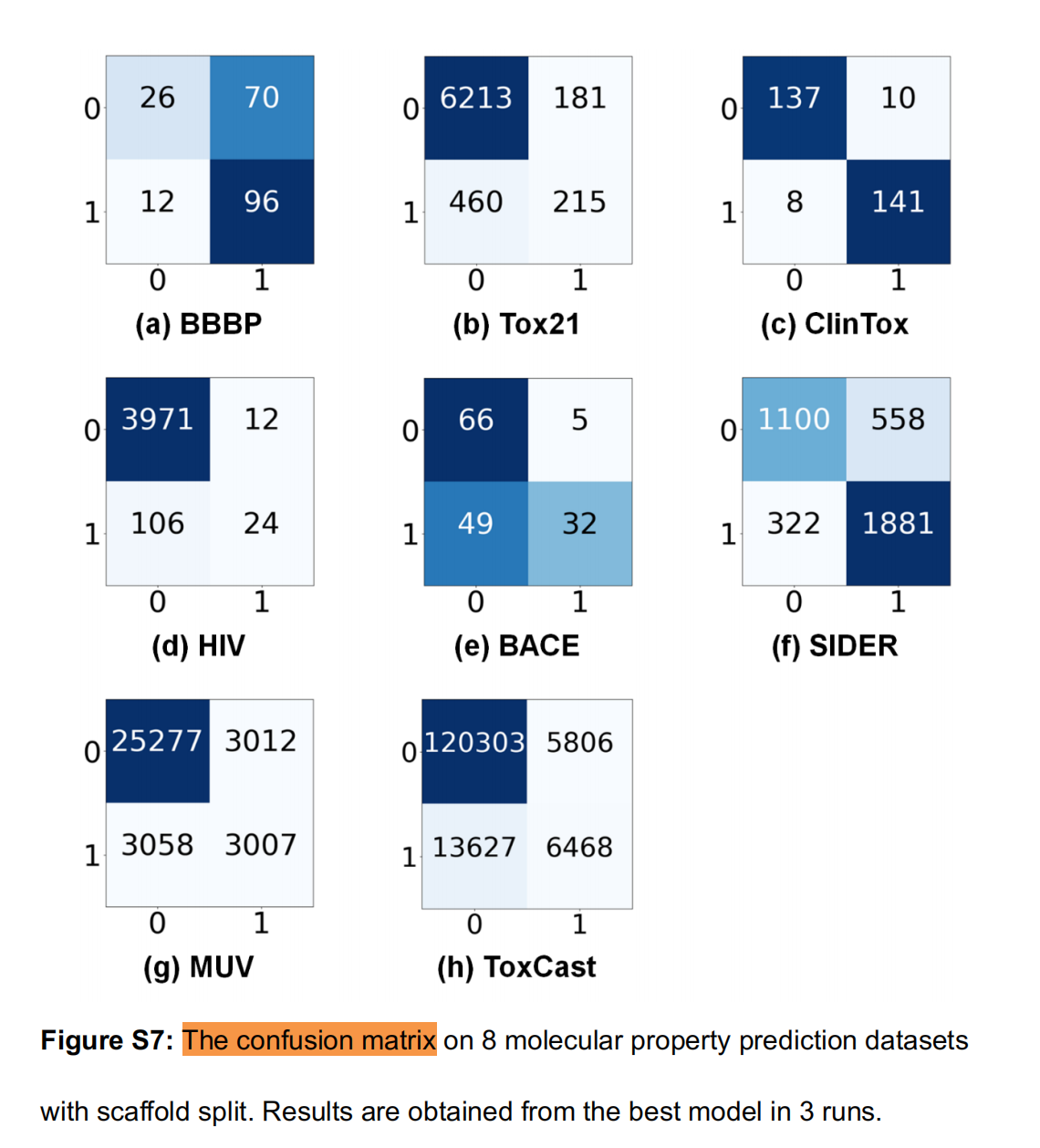
实例:
imagemol的二分类混淆矩阵



















 5350
5350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











