







多模态预训练模型按照模型结构可以分为单流和双流两种结构。
- 单流是指图片和文本在embedding之后就融合在一起进入后续的transformer层。【先将信息fusion,然后再用一个model处理】
- 双流是指文本和图片单独享有自己的transformer层,只在最后做轻量的融合。【每个模态信息有自己的model,再最后做信息的的fusion】
现有的多模态预训练模型都跳不出这两种结构,更多的多模态预训练模型在预训练任务上下功夫、引入更多的预训练任务,设计统一的架构去训练所有的任务等等。除此之外,图片的embedding也有会不同的方式。
一、单流模型示例:
主要通过将不同模型的embedding信息通过加和(+)、拼接(cat)的方式将不同模态的信息拼在一起,然后输入到一个model中进行处理。
1、VisualBERT
论文标题:VisualBERT: A Simple and Performant Baseline for Vision and Language
论文链接:https://arxiv.org/abs/1908.03557
源码链接:https://github.com/uclanlp/visualbert
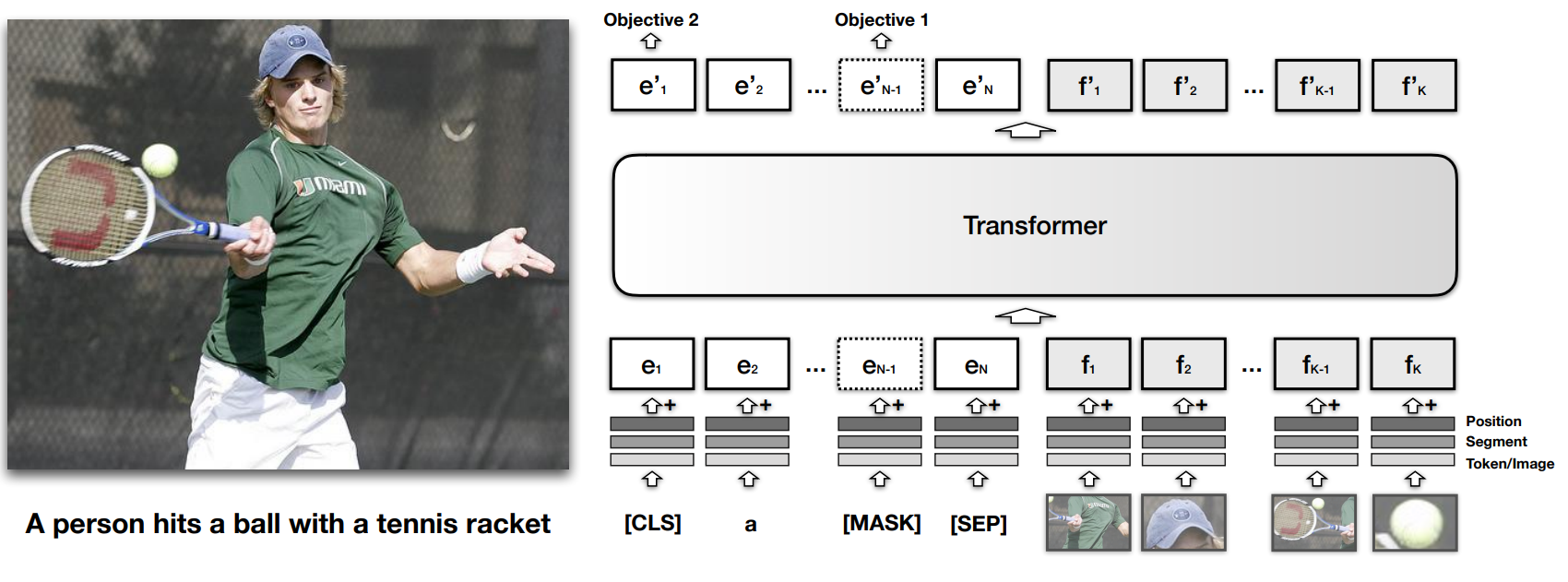
2、Unicoder-VL
论文标题:Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
论文链接:https://arxiv.org/abs/1908.06066
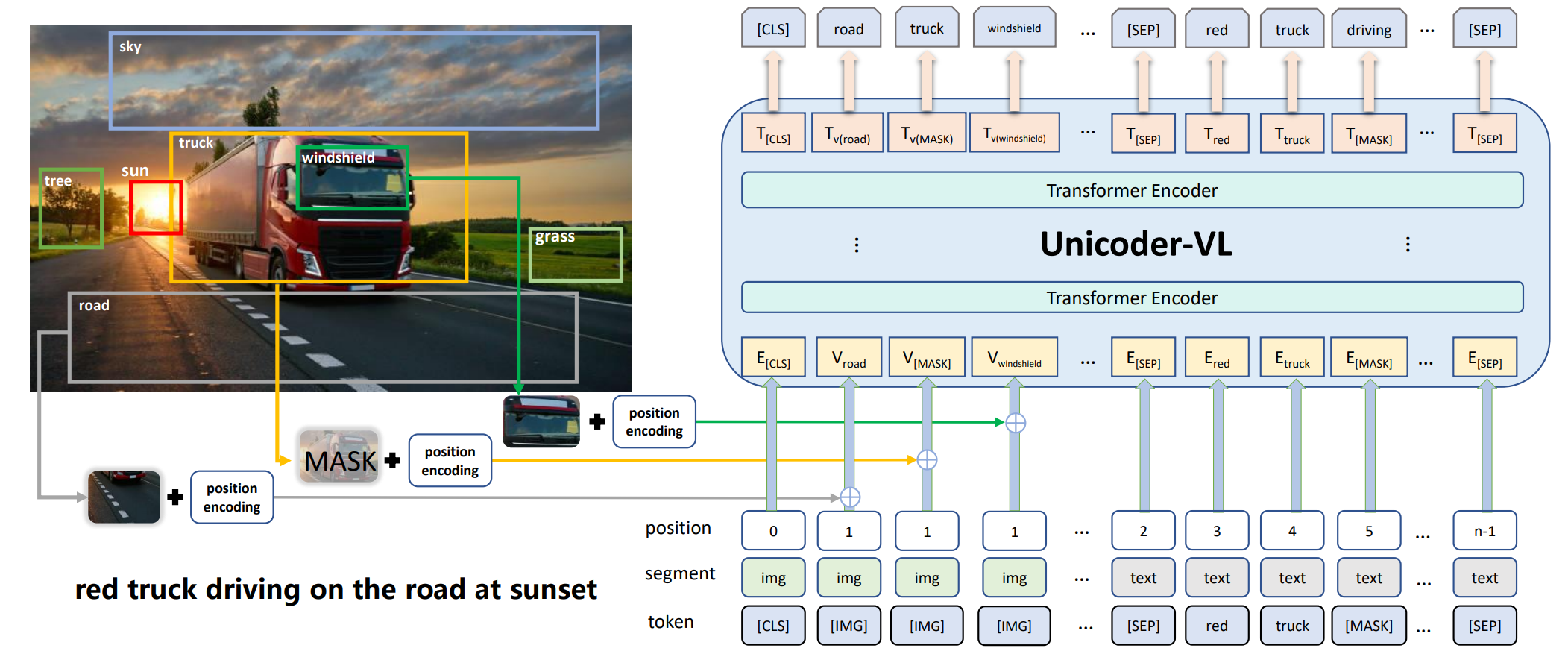
3、VL-BERT
论文标题:VL-BERT: Pre-training of Generic Visual-Linguistic Representations
论文链接:https://arxiv.org/abs/1908.08530
源码链接:https://github.com/jackroos/VL-BERT
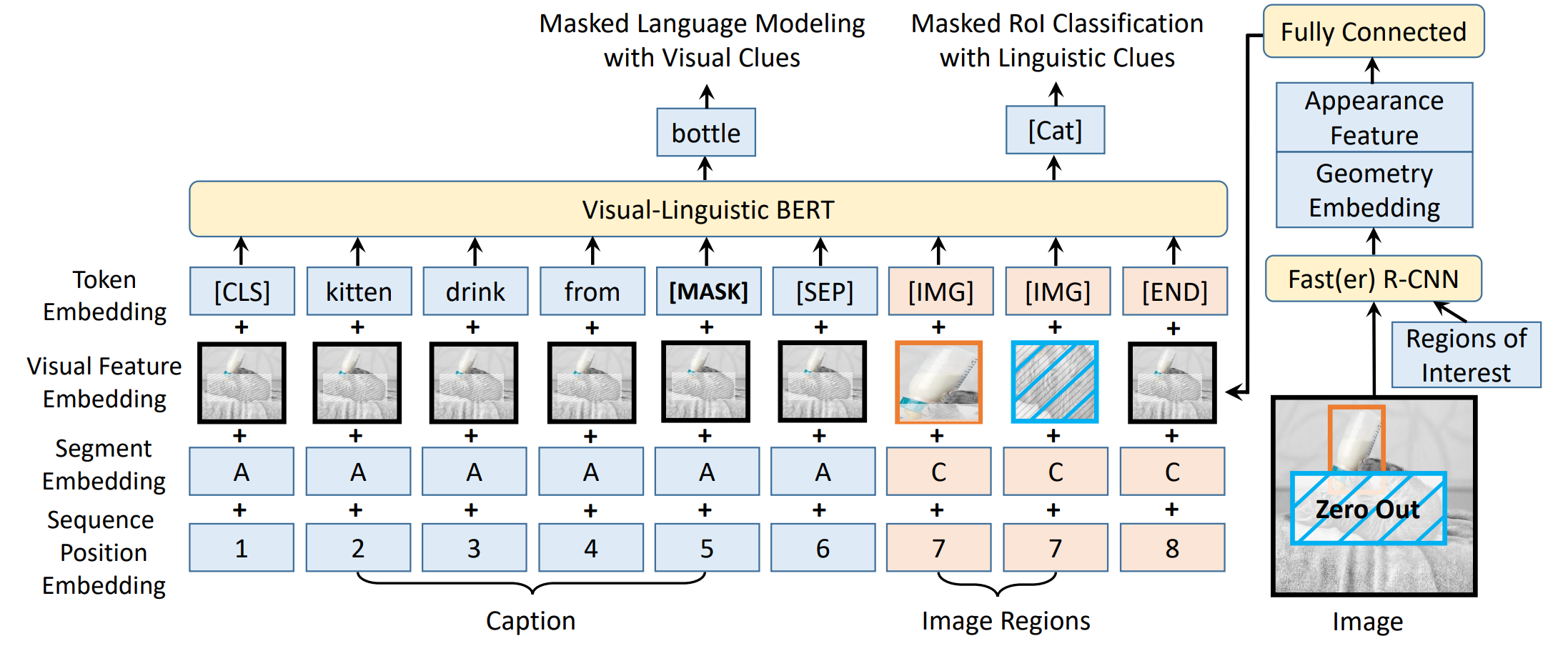
二、双流模型示例:
主要通过共注意力(co-attention)来将经过不同model的模态信息进行融合。或者交叉注意力(cross-attention)
1、ViLBERT
论文标题:ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
论文链接:https://arxiv.org/abs/1908.02265
源码链接:https://github.com/facebookresearch/vilbert-multi-task
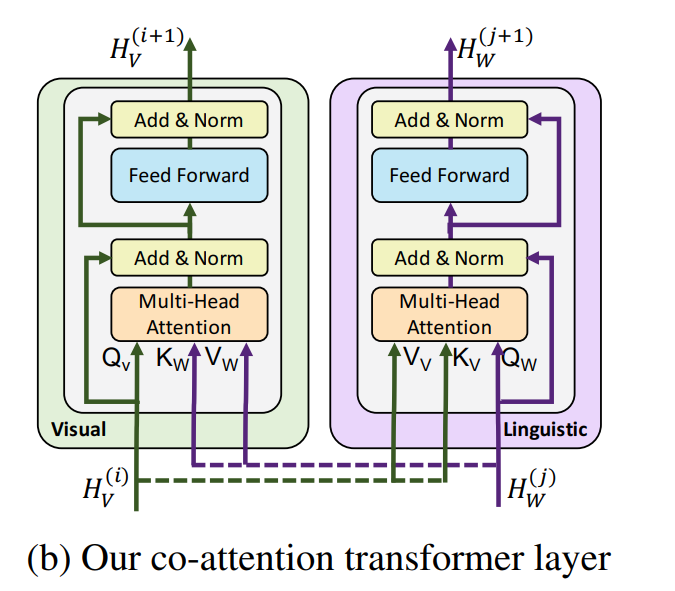
基于双流的 ViLBERT,在一开始并未直接对语言信息和图片信息进行融合,而是先各自经过 Transformer 的编码器进行编码。分流设计是基于这样一个假设,语言的理解本身比图像复杂,而且图像的输入本身就是经过 Faster-RCNN 提取的较高层次的特征,因此两者所需要的编码深度应该是不一样的。
当两种模态各自进行编码后,其输出会经过一个共注意力机制模块(图右侧所示)。该模块也是基于 Transformer 的结构,只是在自注意力机制中每个模块都用自己的 Query 去和另一模块的 Value 和 Key 计算注意力,由此来融合不同模块间的信息。
2、LXMERT
论文标题:LXMERT: Learning Cross-Modality Encoder Representations from Transformers
论文链接:https://arxiv.org/abs/1908.07490
源码链接:https://github.com/airsplay/lxmert
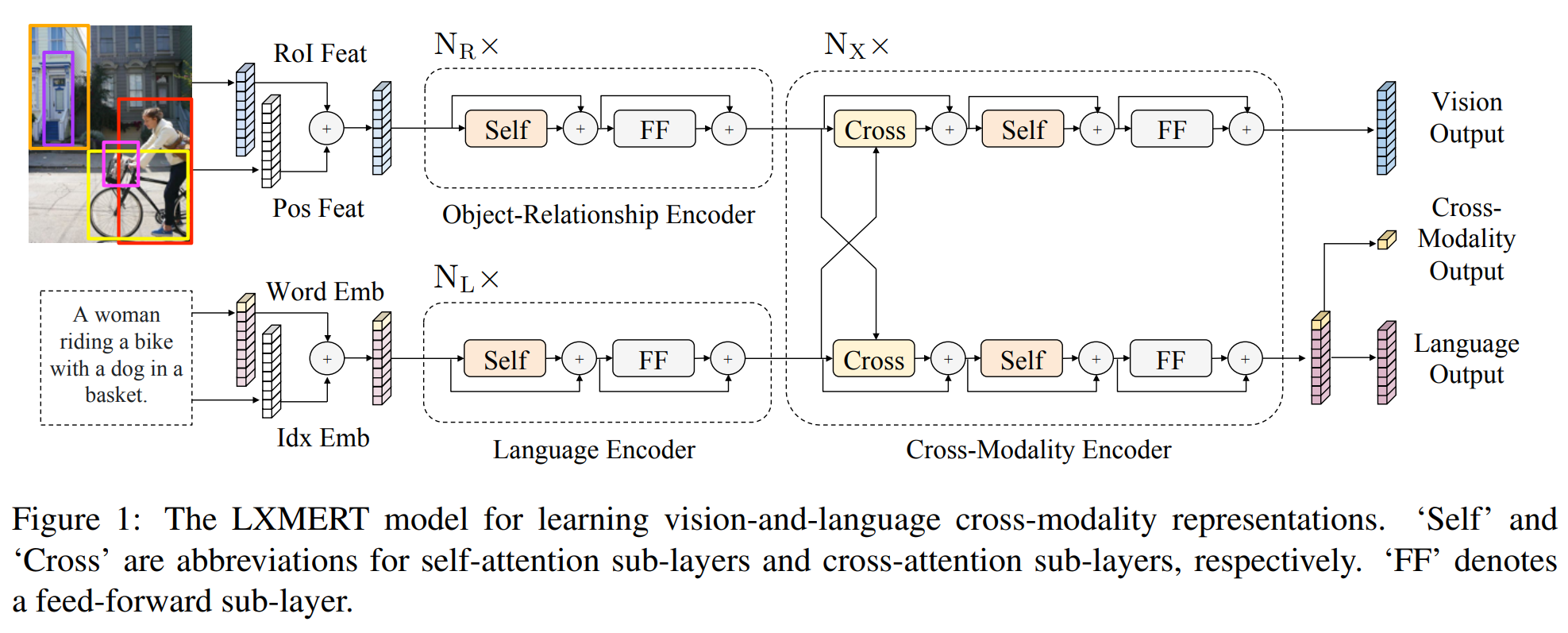
该模型与 ViLBERT 一样采用了双流模型。如图所示,语言与图像在一开始先各自经过独立的编码层进行编码,然后再经过一个模态交互编码层进行语言与图像在语义上的对齐和融合。
在交互编码层中,该模型同样的也是使用共注意力(co-attention)机制,即自注意力中的 query 来自一个模态,而 key 和 value 来自另一个模态。该编码层过后,图像与语言各自又经过一层自注意力层进一步提取高层特征。
该模型的输出有三个部分,一个语言端的输出,一个图像端的输出,一个多模态的输出。该模型在与训练时使用了四个任务:语言掩码任务,图像掩码任务(该任务有两部分,第一部分为预测被掩图像物体类别,第二部分为 ROI 特征回归任务该任务使用 L2 损失函数,语言图像匹配任务和图像问答任务。
3、CLIP
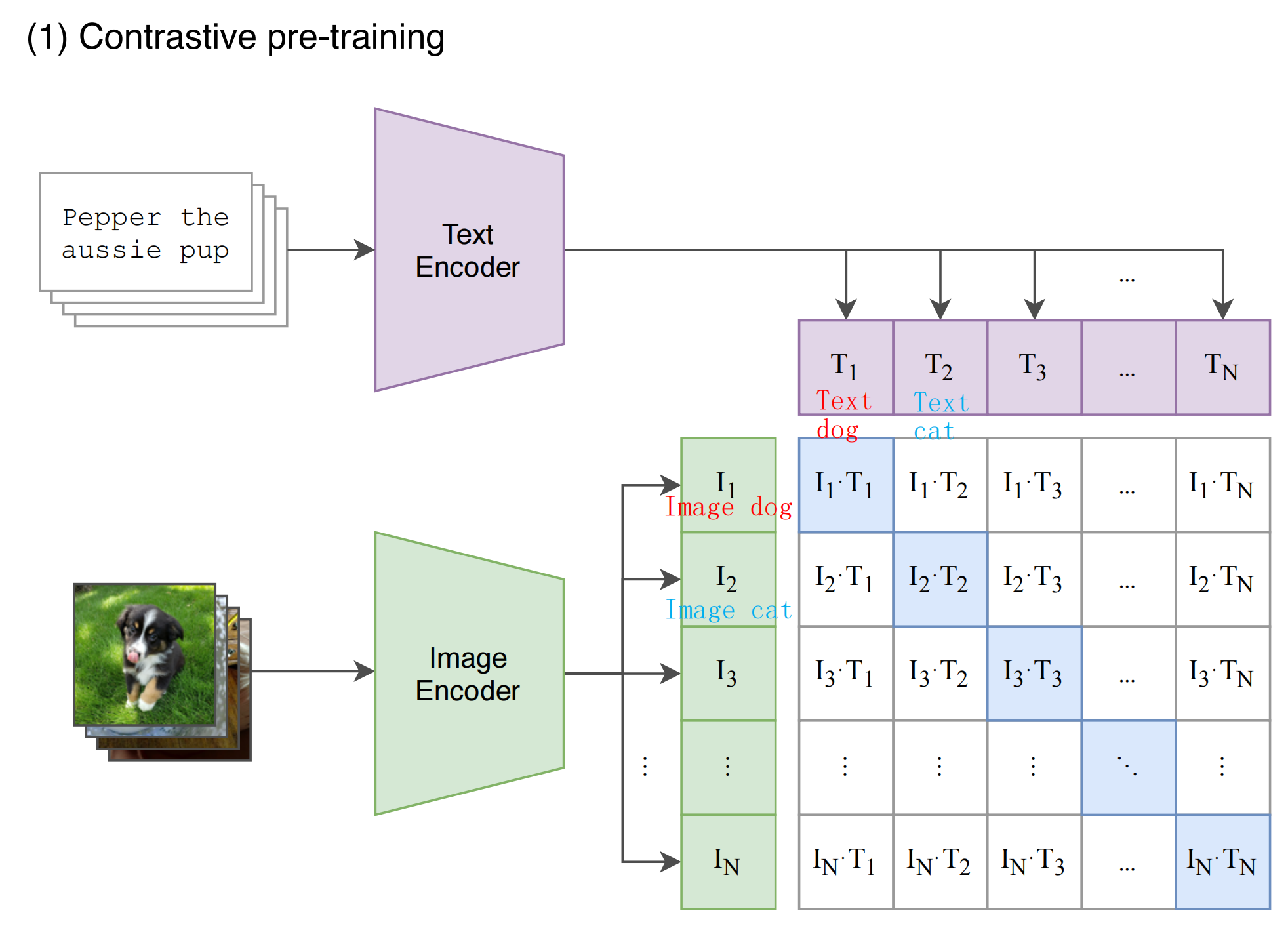
图像编码器(Image Encoder)->图像特征
文本编码器(Text Encoder)->文本特征
计算“图像特征”和“文本特征”的余弦相似度
对角线的是正样本(蓝色),其余是负样本(白色)
CLIP是双流模型,语言和图像分别经过自己的Encoder,然后用对比学习计算它们之间的距离。



















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











