







基于价值的强化学习算法是在给定的一个状态下, 计算采取每个动作的价值, 然后选择在所有状态下具有 最大期望奖励的行动。如果省略中间的步骤, 即直接根据当前的状态来选择动作, 也就引出了强化学习中的另 一种很重要的算法, 即策略梯度 (Policy Gradient,PG)。策略梯度方法有三个基本组成部分: 演员 (Actor)、环境 和奖励函数, 如下图所示, 演员可以采取各种可能的动作与环境交互, 在交互的过程中环境会依据当前环境状 态和演员的动作给出相应的奖励 (Reward),并修改自身状态。演员的目的就在于调整策略 (Policy),即根据环境 信息决定采取什么动作以最大化奖励。

演员与环境交互过程
上述过程可以形式化的表示为:设环境的状态为 st ,演员的策略函数 πθ 是从环境状态 st 到动作 at 的映射, 其中 θ 是策略函数 π 的参数;奖励函数 r(st , at ) 为从环境状态和演员动作到奖励值的映射。一次完整的交互过 程如下图所示, 环境初始状态为 s1 ,演员依据初始状态 s1 采取动作 a1 ,奖励函数依据 (s1 , a1 ) 给出奖励 r1 ,环 境接受动作 a1 的影响修改自身状态为 s2 ,如此不断重复这一过程直到交互结束。在这一交互过程中, 定义环境 状态 si 和演员动作 ai 组成的序列为轨迹 (Trajectory)。
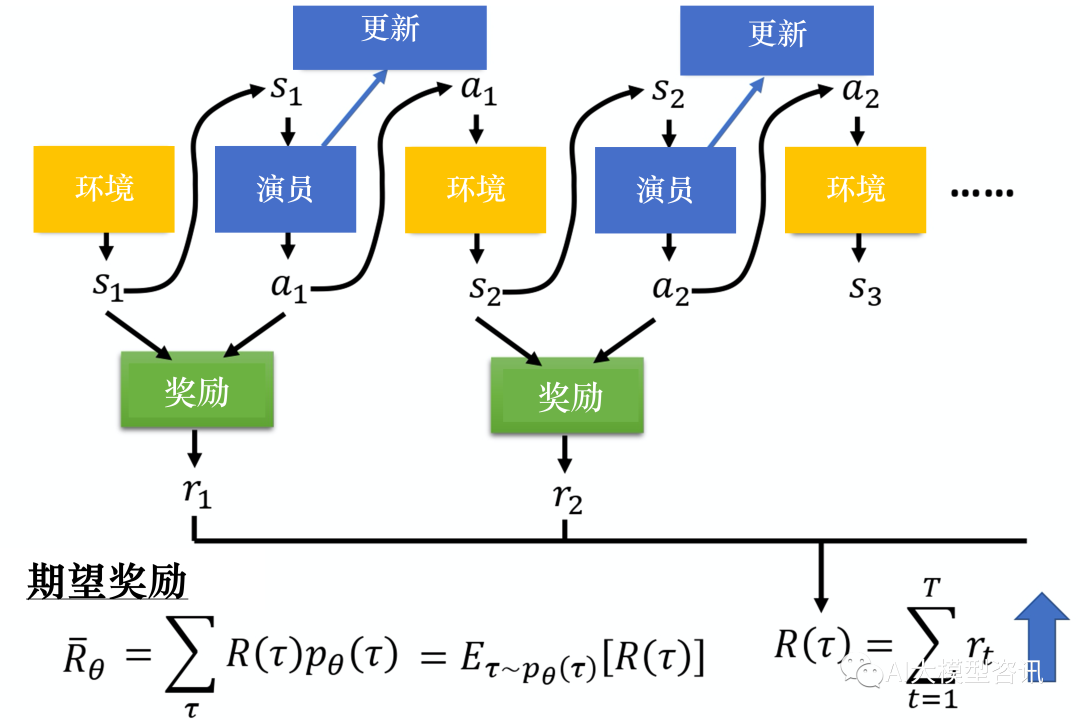
演员与环境交互过程形式化表示
策略梯度的目的是直接建模与优化 Policy。我们以一个射击游戏来示例上述形式化的表示过程, 如下图所 示:输入当前的状态,输出 action 的概率分布,依据概率分布选择下一个action。
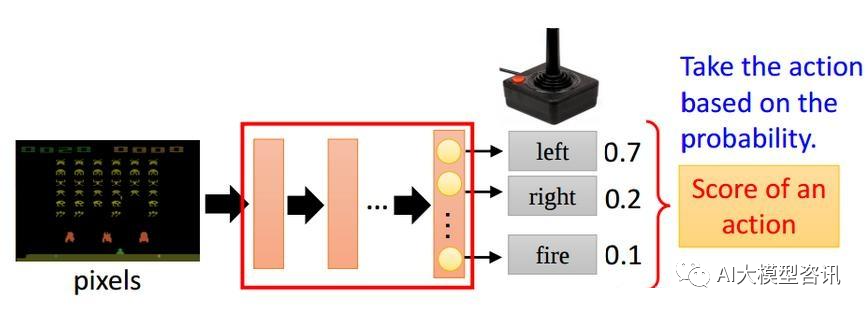
策略梯度直接输出选择某动作的概率示意图
机器先观察画面, 然后做出了一个 action, 向 right 移动, 这个 action 的奖励是 r1 = 0,然后机器又观察 画面, 做出了射击的动作, 然后观察画面, 发现有外星人被击落, 然后获得 reward r2 = 5。经过很多轮 (s,a,r), 游戏结束了。从游戏开始到游戏结束被称为一个 episode,将每一个 episode 的 reward 相加就能得到累积奖励: R = ∑r_t。希望通过训练更好的 acrtor 使得 R 可以尽可能的大。把每一个episode 的所有 s 和 a 的序列放在 一起,就是 Trajectory τ = s1 , a1 , s2 , a2 , ..., sT , aT ,通过以上知道 π 在参数为 θ 的情况下, τ 发生的概率:
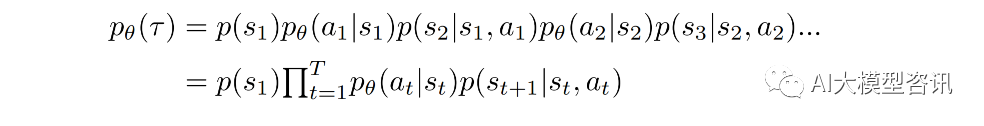
其中, p(s1 ) 是初始状态 s1 发生的概率, pθ (at |st ) 为给定状态 st 策略函数采取动作 at 的概率, p(st+1|st , at ) 为 给定当前状态 st 和动作 at ,环境转移到状态 st+1 的概率。
给定轨迹 τ ,累计奖励为 R = ∑r_t。累计奖励为称为回报 (Return)。希望演员在交互过程中回报总是尽 可能多, 但是回报并非是一个标量值, 因为演员采取哪一个动作以及环境转移到哪一个状态均以概率形式发生, 因此轨迹 τ 和对应回报 R(τ) 均为随机变量,只能计算回报的期望, 得到了概率之后,利用根据采样得到的回报 值可以计算出数学期望:
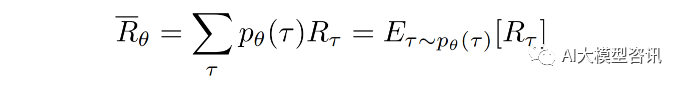
给定一条轨迹, 回报总是固定的, 因此只能调整策略函数参数 θ 使得高回报的轨迹发生概率尽可能大, 而 低回报的轨迹发生概率尽可能小。为了优化参数 θ,可以使用梯度上升方法,优化 θ 使得期望回报 Rθ 最大化。
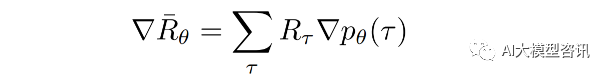
观察上式可以注意到, 只有 ∇pθ (τ ) 与 θ 有关。考虑到 pθ (τ ) 是多个概率值的连乘, 难以进 行梯度优化,因此将 ∇pθ (τ ) 转化为 ∇ log pθ (τ ) 的形式使之易于计算。可以得到如下等式:
![]()
根据 ∇pθ (τ ) = p(θ)∇ log pθ (τ ),带入公式 可得:
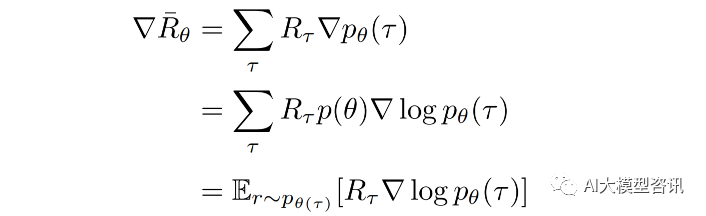
将上式基础上,带入 ∇ log pθ (τ ),可以继续推导得到:
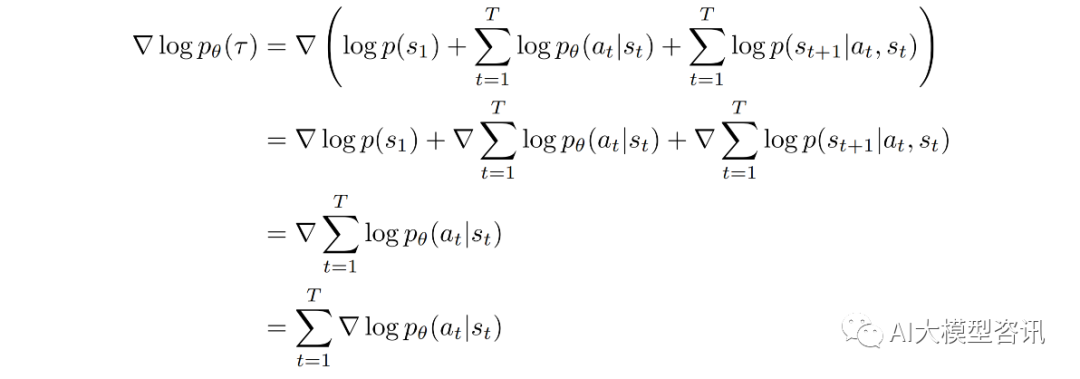
这里是对策略函数参数 θ 求梯度, 而 p(s1 ) 和 p(st+1|st , at ) 由环境决定, 与策略函数参数 θ 无关, 因此这两 项的梯度为 0。将上式带入公式进行推导, 由于期望无法直接计算, 因此在实践中, 通常是从概率分布 pθ (τ )中采样 N 条轨迹近似计算期望:
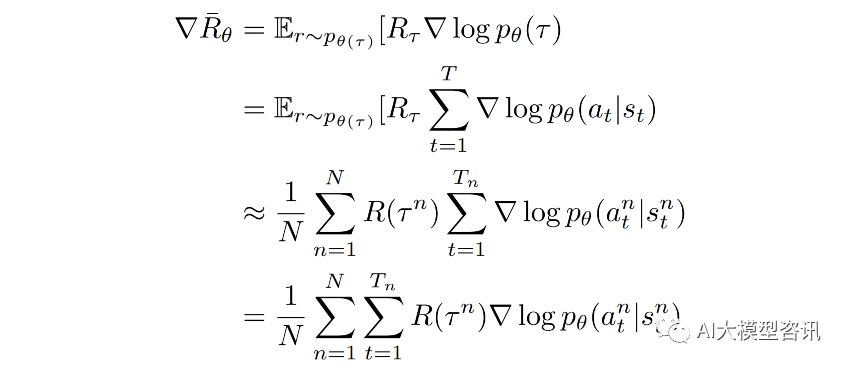
直观来看, 上式中的 R(τ^n ) 指示 p_θ (a^n |s^n ) 的调整方向和大小。当 R(τ^n ) 为正, 说明给定 s^n_t状态下, 动作 a^n_t能够获得正回报, 因此梯度上升会使得概率 p_θ (a^n |s^n ) 增大, 即策略更有可能在s^n_t状态下采取动作 a^n_t;反之 则说明动作会受到惩罚, 相应地策略会减少在s^n_t状态下采取动作 a^n_t的概率。使用学习率为 η 的梯度上升方法 优化策略参数 θ,使之能够获得更高的回报:
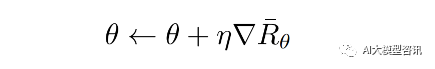
在实际实验中, 让 actor 去和environment 做互动, 产生左边的数据。左边的方框是做采样, 获得很多 (s,a) 的 pair (代表在 s 下采取 a ,得到 R(τ ),这里 state 是随机性的, 相同的 state 不见得会有相同的 action。然后将 这些数据送入训练过程中计算梯度, 即 ∇logpθ (atn|stn),然后取梯度, 乘以权重。基于这个 reward 去更新模型的 参数 θ,用更新的模型再来获取数据,之后再更新模型,如此循环反复。具体过程如下图所示。
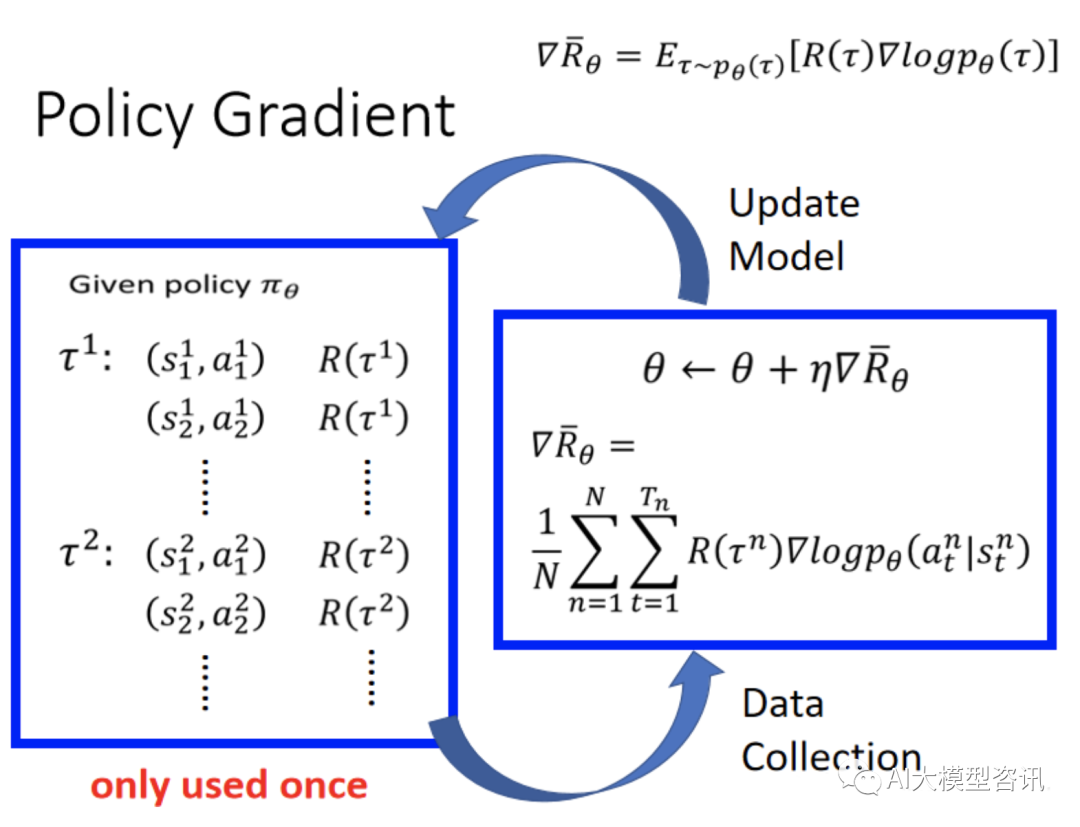
策略梯度数据收集和模型更新示意图
策略梯度通过观测信息选出一个行为直接进行反向传播, 利用 reward 奖励直接对选择行为的可能性进行增 强和减弱, 好的行为会被增加下一次被选中的概率, 不好的行为会被减弱下次被选中的概率。策略梯度有些不 足:
-
采样效率低, PG 采用蒙特卡洛采样方式, 每次基于当前的策略对环境采样一个 episode 数据, 然后基于这 些数据更新策略, 这个过程中数据仅仅被利用了一次就扔掉了, 相比于 DQN 等离线学习算法, PG 这种更 新方式是对数据的极大浪费。PG 算法只有一个 agent,他与环境互动, 然后学习更新, 这个过程中的policy 都是同一个。因此, 当我们更新参数之后, 之前计算的策略的所有概率就都不对了, 这时候就需要重新去采 样。之前采样出来的数据都不能用了, 换句话说, 过程中的数据都只能用一次。这就造成了 policy gradient 会花很多时间在采样数据上,因为所有的数据都只能更新一次,更新一次之后就要重新采样。
-
训练不稳定, 在强化学习中当前的动作选择会影响到将来的情况, 不像监督学习的训练样本是相互独立的, 如果某一批次的样本不好导致模型训练的很差, 只要其他的训练数据没问题最终也能得到一个好的结果。 但是在 PG 中, 对于某次策略更新的太大或者太小, 就会得到一个不好的 Policy,一个不好的和环境交互 就会得到一个不好的数据, 用这些不好的数据更新的策略很大概率也是不好的。所以训练过程中会忽然进入一个很差的状态。
因此, 有了 近端策略优化算法 (Proximal Policy Optimization,PPO) 算法的改进原因。希望可以用一个旧策略收集到的数据来训练新策略,这意味着可以重复 利用这些数据来更新策略多次, 效率上可以提升很多。下一节再介绍PPO算法。
ps:欢迎扫码关注公众号^_^.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









