







文章提出了一种新任务——通过多模态大语言模型(MLLMs)将图像中的表情符号翻译为对应的文字(如成语、单词、或习语),以评估模型的视觉-语言理解能力。文章设计了一个高质量的基准数据集“Emoji2Idiom”,包括从网络和手动生成的数据集,用于支持这一任务。研究发现,现有的MLLMs在理解表情符号语义和推理文字含义方面存在显著不足。这项工作不仅提供了新的评测方法,还揭示了未来多模态模型需要改进的方向。
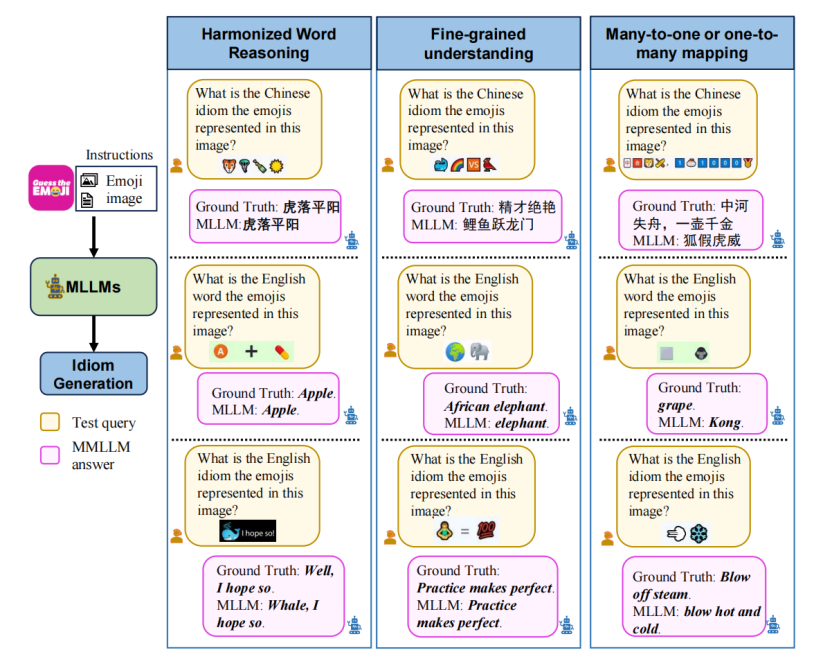
1 Emoji2Idiom书籍资料介绍
· 数据收集: 首先,从互联网和公开资源中获取与表情符号相关的原始数据,包括游戏截图、视频片段和网络数据库,同时通过文本生成相应的表情符号序列以扩充数据多样性。
· 自动数据清理: 利用算法进行初步数据过滤,删除重复、缺失或质量低下的样本,同时检测并剔除不符合伦理要求(如暴力、歧视性内容)的数据。
· 人工数据筛选: 由语言和图像专家进一步审核数据,确保表情符号与文本之间的语义关联清晰,并剔除语义模糊、不符合常规语言使用习惯或过于复杂的样本。
· 数据规范化: 对表情符号和文本配对进行标准化处理,避免过多重复映射,调整或替换频繁出现的谐音字符映射以提高数据多样性。
· 多语言覆盖: 设计任务包括表情符号到中文成语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









