







文章研究如何从多模态生物学观测数据中进行因果表示学习。文章指出,目前的机器学习模型在分析这些数据时缺乏可解释性和理论保证。作者提出了一种灵活的非参数模型,允许在不同模态之间存在因果关系,并通过理论分析证明了对潜在因果变量的识别能力。通过实验,展示了该方法在数值、合成数据以及真实数据(如人类表型数据)上的有效性,发现的因果关系与医学研究一致。这一框架对多模态数据的分析和生物系统机制的理解具有重要意义,尽管仍面临一些实际限制,如需要预知每个模态中的潜在变量数量。
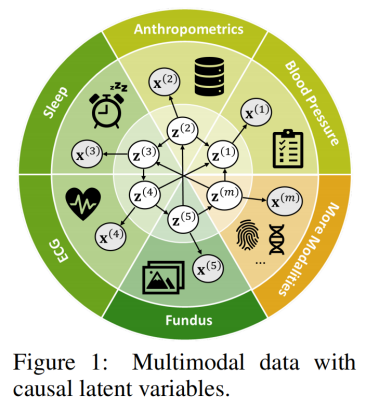
1 多模态生物学数据的因果学习表示框架
两个假设:
非参数潜在分布假设:通过允许潜在因果变量的分布非参数化建模,避免了传统方法中对分布形式的严格限制,增强了模型的灵活性和适用性。
稀疏因果关系假设:引入稀疏因果关系假设,假定不同模态之间的因果连接较少,从而降低模型复杂度并符合实际生物系统的稀疏性特征。
表示学习步骤:
子空间识别:首先,在各模态的观测数据中识别潜在变量的子空间,确保这些子空间保留跨模态的因果信息。
组件级别因果变量识别:进一步细化子空间,识别具体的因果变量组件,捕获更详细的因果机制和潜在变量间的关系。
编码解码器框架:通过单模态编码器提取潜在变量和模态特定变量,再用解码器重构观测数据,确保因果信息的保留和数据的重现。
条件独立性约束:利用KL散度最小化引入独立性约束,确保潜在变量之间的因果关系不被模态特定信息混淆。
稀疏正则化:在学习因果图的邻接矩阵时加入稀疏正则化,优化生成的因果图结构,增强模型的解释性和通用性。
在数值、合成和真实数据上验证框架,通过发现与医学研究一致的因果关系,证明其在生物学数据分析中的实用性和有效性。
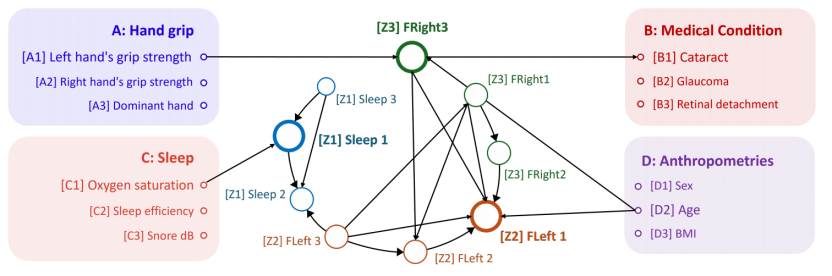
2 结语
文章提出了一种理论和实践结合的框架,用于从多模态生物学数据中识别潜在因果变量,以提升数据解释性和应用可靠性。
论文题目:Causal Representation Learning from Multimodal Biological Observations
论文链接:https://arxiv.org/pdf/2411.06518
PS: 欢迎大家扫码关注公众号^_^,我们一起在AI的世界中探索前行,期待共同进步!

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









