







数据并行是最常见的并行形式, 因为它很简单。在数据并行训练中, 数据集被分割成几个碎片, 每个碎片被 分配到一个设备上。这相当于沿批次(Batch) 维度对训练过程进行并行化。每个设备将持有一个完整的模型副 本, 并在分配的数据集碎片上进行训练。在反向传播之后, 模型的梯度将被全部减少, 以便在不同设备上的模 型参数能够保持同步。主要分为两个操作: 输入数据切分和模型参数同步。
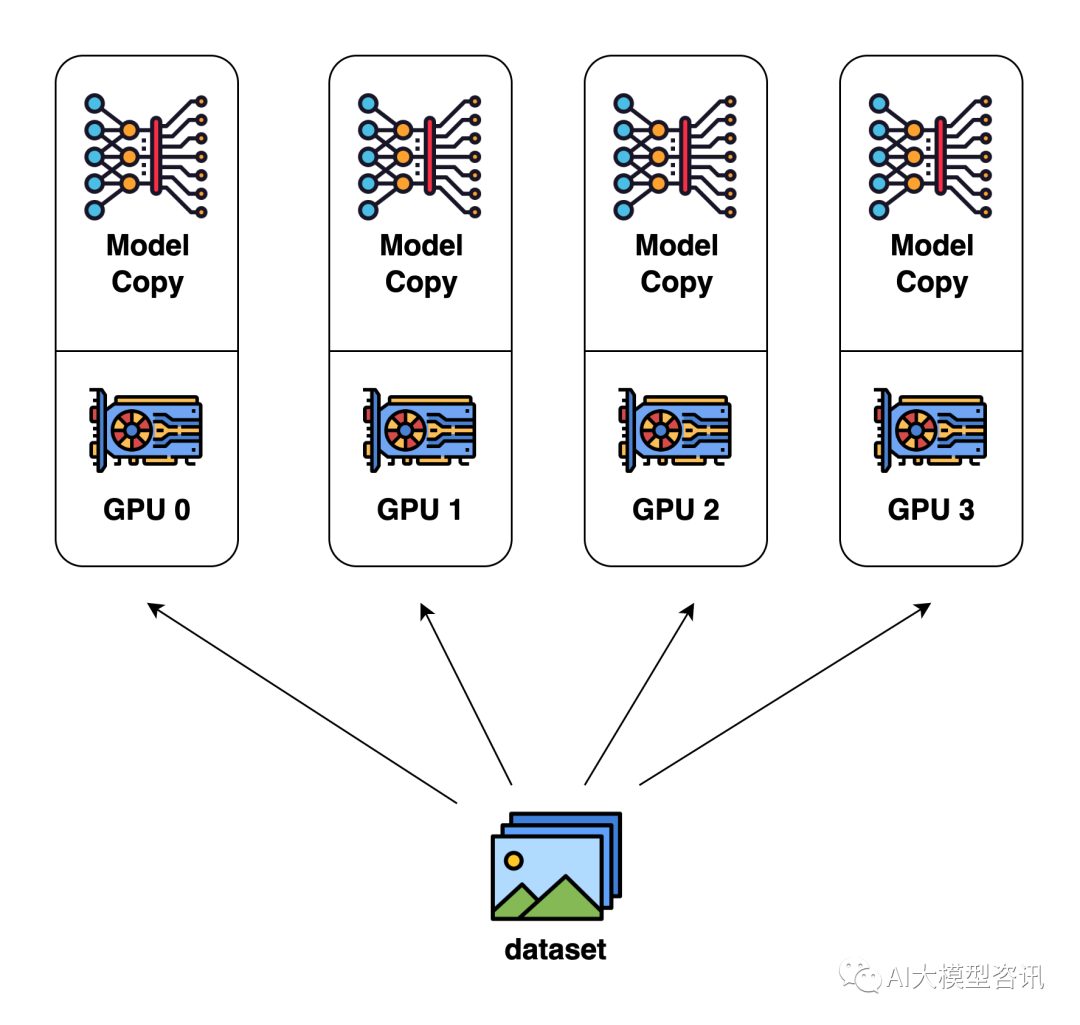
数据并行示例
输入数据切分
输入数据切分实现上比较简单,一般有两种常用的实现方式:
-
方式一:在每个训练 Epoch 开始前, 将整个训练数据集根据并行进程数划分, 每个进程只读取自身切分的 数据。
-
方式二:数据的读取仅由具体某个进程负责 (假设为 rank0)。rank0 在数据读取后同样根据并行进程数将数据切分成 多块,再将不同数据块发送到对应进程上。
目前主流训练框架数据并行训练中使用 Allreduce 同步通信操作来实现所有进程间梯度的同步, 这要求数据在各进程间的切分要做到尽量均匀,这个问题看起来很简单,但在实际实现中也要特别注意以下两点:
-
1. 要求所有进程每个训练 step 输入的 local batch size 大小相同。这是因为模型训练时需要的是所有样本对 应梯度的全局平均值。如果每个进程的 local batch size 不相同, 在计算梯度平均值时, 除了要在所有进程间 使用 Allreduce 同步梯度, 还需要要同步每个进程上 local batch size。当限制所有进程上的 local batch size 相 同时, 各进程可以先在本地计算本进程上梯度的 local 平均值, 然后对梯度在所有进程间做 Allreduce sum 同步, 同步后的梯度除以进程数得到的值就是梯度的全局平均值。这样实现可以减少对 local batch size 同 步的需求,提升训练速度。
-
2. 要保证所有进程上分配到相同的 batch 数量。因为 Allreduce 是同步通信操作, 需要所有进程同时开始并 同时结束一次通信过程。当有的进程的 batch 数量少于其它进程时, 该进程会因为没有新的数据 batch 而停 止训练, 但其他进程会继续进行下一 batch 的训练;当进入下一 batch 训练的进程执行到第一个 Allreduce 通信操作时, 会一直等待其他所有进程到达第一个 Allreduce 一起完成通信操作。但因为缺少 batch 的进程, 已经停止训练不会执行这次 allreduce 操作, 导致其它进程将会一直等待, 呈现挂死态。数据并行中batch 数量在进程的均匀切分通常是由 data loader 来保障的, 如果训练数据集样本数无法整除数据并行进程数, 那么有一种策略是部分拿到多余样本的进程可以通过抛弃最后一个 batch 来保证所有进程 batch 数量的一 致。
模型参数同步
数据并行实现的关键问题在于如何保证训练过程中每个进程上模型的参数相同。因为训练过程的每一个 step 都会更新模型参数, 每个进程处理不同的数据会得到不同的 Loss。由 Loss 计算反向梯度并更新模型参数后, 如 何保证进程间模型参数正确同步, 是数据并行需要解决的最主要问题。根据下面中的梯度更新公式, 只要保证 以下两点就能解决这个问题:
-
每个进程上模型的初始化参数相同;保证每个进程模型参数初始相同有两种常用的实现方法:方法一:所 有进程在参数初始时使用相同的随机种子并以相同的顺序初始化所有参数。方法二:通过个具体进程初始 化全部模型参数,之后由该进程向其他所有进程广播模型参数。
-
每个进程上每次更新的梯度相同。梯度同步的数据并行训练就可以进一步拆解为如下三个部分:1. 前向计 算; 2. 反向计算;3. 参数更新。
1. 前向计算 每个进程根据自身得到的输入数据独立前向计算, 因为输入数据不同每个进程会得到不同的 Loss。一般情况下各进程前向计算是独立的, 不涉及同步问题。但使用批归一化(Batch Normalization) 技术的场景下有 新的挑战。
批归一化通过对输入 tensor 在 batch size 维度做归一化来提升训练过程的数值稳定性。但是数据并行训练中 global batch size 被切分到不同的进程之上, 每个进程上只有部分的输入数据, 这样批归一化在计算输入tensor batch 维度的平均值 (Mean) 和方差 (Variance) 时仅使用了部分的 batch 而非 global batch,会导致部分对 batch size 比较敏感的模型的精度下降。
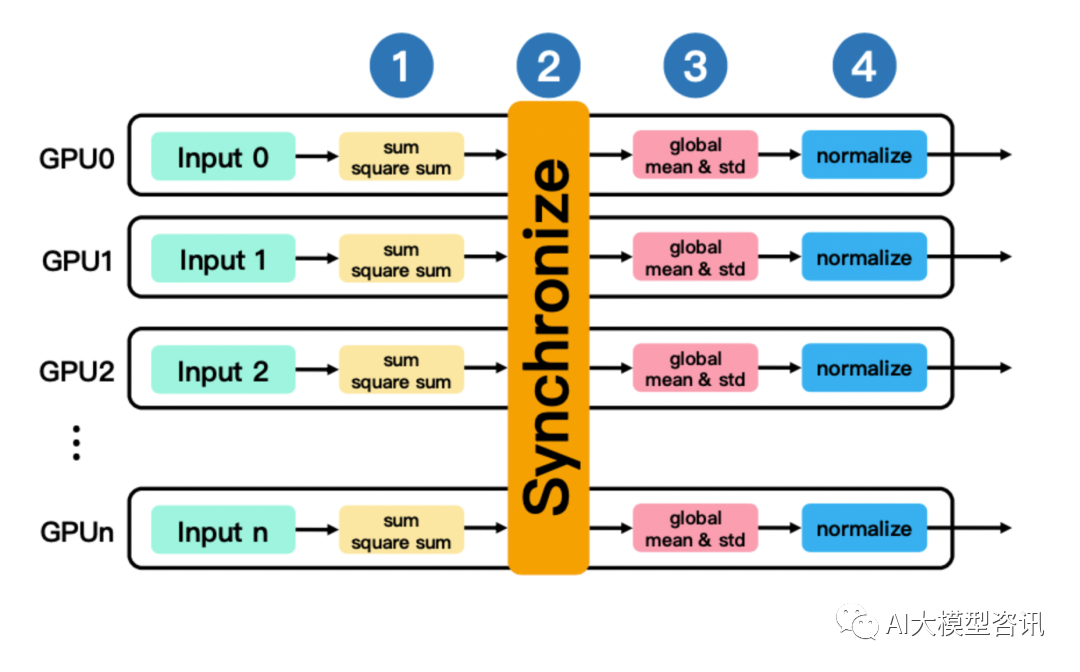
批归一化同步示例
这类模型在数据并行训练中可以使用 SyncBatchNorm 策略来保证模型精度, 该策略在模型训练前向 BN 层 计算 mean 和 variance 时加入额外的同步通信, 使用所有数据并行进程上的 tensors 而非自身进程上的 tensor 来 计算 tensor batch 维度的 mean 和 variance。具体过程如上图所示:
-
每个进程根据自己部分的数据计算 batch 维度上的 local sum 和 local square sum 值。
-
在所有卡间同步得到 global sum 和 global square sum。
-
使用 global sum 和 global square sum 计算 global mean 和 global standard deviation。
-
最后使用 global 的 mean 和 standard deviation 对 batch data 进行归一化。
语言类模型中主要使用的 Layer Normalization,是在单个数据而非批数据的维度输入 tensor 计算 mean 和 variance,数据并行并不会影响其计算逻辑,不需要像 Batch Normalization 一样做专门的调整。
2. 反向计算 每个进程根据自身的前向计算独立进行反向计算, 因为每个进程上的 Loss 不同, 每个进程上在反向中会计算出不同的梯度。这时一个关键的操作是要在后续的更新步骤之前, 对所有进程上的梯度进行同步, 保 证后续更新步骤中每个进程使用相同的全局梯度更新模型参数。
这一个梯度同步过程是用一个 Allreduce sum 同步通信操作实现的, 对梯度使用 Allreduce sum 操作后每个进 程上得到的梯度是相同的, 这时候的梯度值等于所有进程上梯度对应位置相加的和, 然后每个进程用 Allreduce 后的梯度和除以数据并行中的进程数,这样得到的梯度是同步之前所有进程上梯度的平均值。如下图所示。
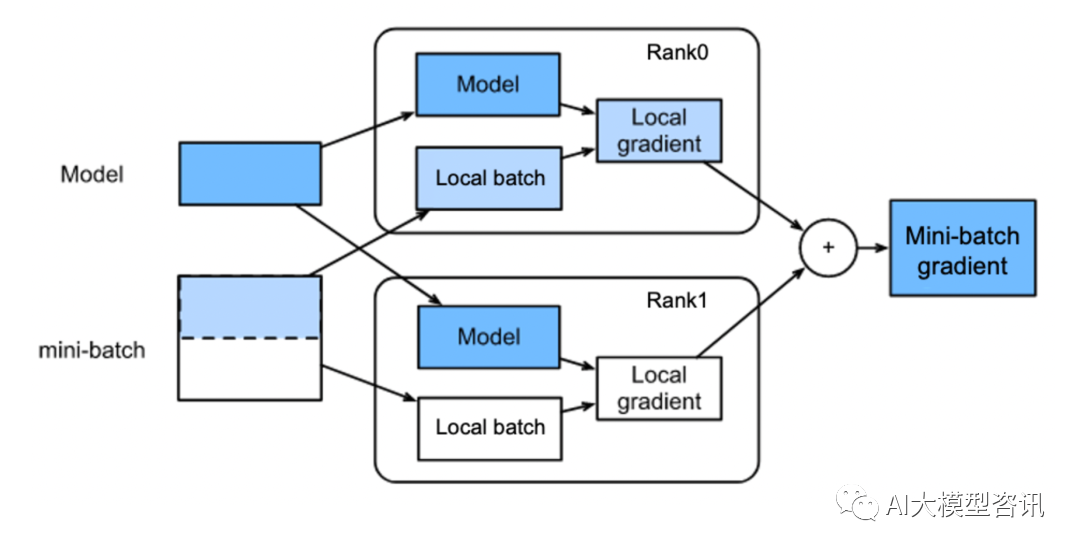
反向梯度同步示例
3. 参数更新 每个进程经过上述步骤后得到相同全局梯度, 然后各自独立地完成参数更新。因为更新前模型各 进程间的参数是相同的,更新中所使用的梯度也是相同的,所以更新后各进程上的参数也是相同的。
上述是主流框架中数据并行的实现过程。和单卡训练相比, 最主要的区别在于反向计算中的梯度需要在所 有进程中进行同步,保证每个进程上最终得到的是所有进程上梯度的平均值。
ps: 欢迎扫码关注公众号^_^.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









