







目前,国内外多模态模型的发展呈现出两条主要路径:
1. 语言为核心的多模态融合:
例如,Gemini 模型主要以语言为核心,在此基础上整合感知层面的音频、视频和图像。这类模型通常采用多模态 Transformer 架构,旨在通过统一的语言模型处理多种模态数据,提升模型的推理和理解能力。
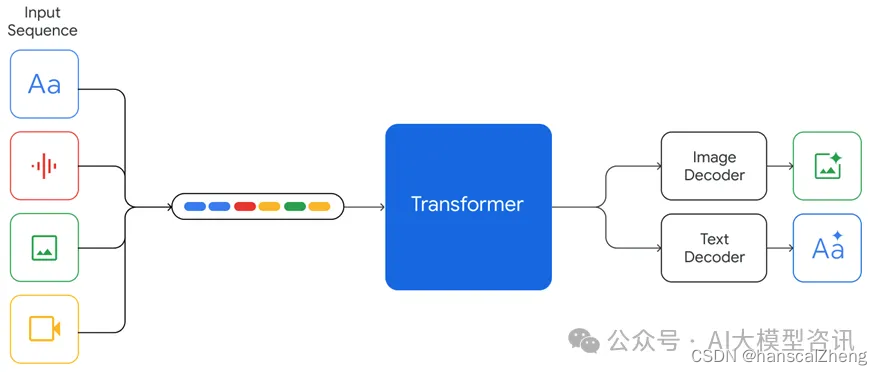
这类多模态模型支持以文本、图像、音频和视频的交错序列作为输入(在输入序列中用不同颜色的标记表示),它可以输出交错的图像和文本响应。然后把几种模态数据联合起来从从头训练,包括文本、图片、音频、视频等,遵循 next token prediction 的模式,所有模态的数据先变成 token,然后图片、视频等平面数据转换成 32*32 (举例)tokens,最后变成一维线性输入,让模型预测 next token,这样就把不同模态在预训练阶段统一起来。
2. 视频生成和渲染为主的多模态生成:
例如,Sora 模型以视频生成和渲染为主,目标是生成主体一致、画面高清逼真的视频。这条路径的技术架构以 DiT(Diffusion Transformer)为主,专注于视觉效果的高质量生成。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









