







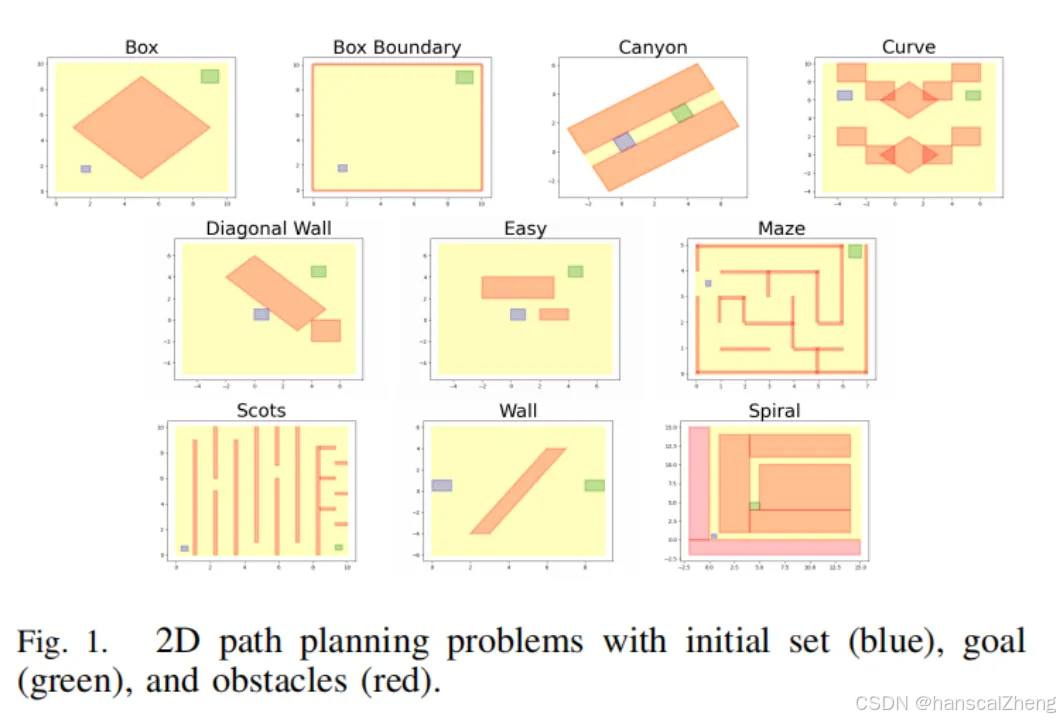
文章研究了如何通过整合求解器生成的反馈(如碰撞提示、自由空间提示等)来提升大型语言模型(LLMs)在解决经典机器人路径规划任务中的表现。作者提出了四种提示策略,并评估了三种不同LLMs的性能。实验结果表明,求解器生成的反馈能够显著提高LLMs解决中等难度问题的能力,但在面对复杂的多障碍问题时,LLMs的表现仍然有限。此外,作者还分析了不同提示策略的效果,发现图像提示对性能提升没有明显帮助,而微调可以改善某些问题的解。
1 封闭循环提示框架
该框架的初始提示为LLM提供路径规划问题的基本信息,包括初始位置、目标位置、障碍物等。初始提示还包括一些指导性说明,例如如何输出解答,并提供一个示例路径规划问题及其解决方案。
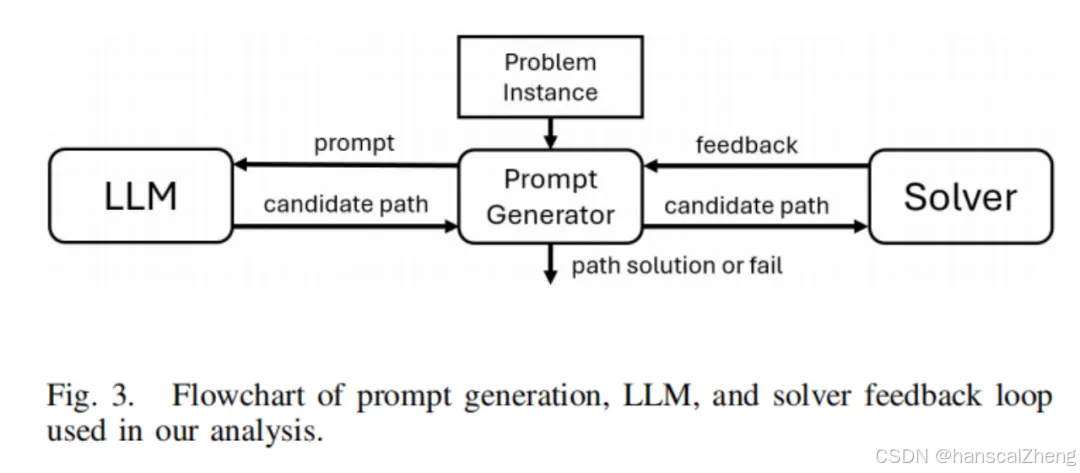
反馈循环
LLM生成初步的路径解答后,框架会对其进行验证,通常使用求解器(如SMT求解器)来检测解答中的错误。检测结果以反馈的形式返回给LLM,指出解答中的问题,如路径碰撞或无效段。框架依靠求解器生成四种不同类型的反馈:
-
碰撞提示:告知LLM路径在哪些地方与障碍物相交。
-
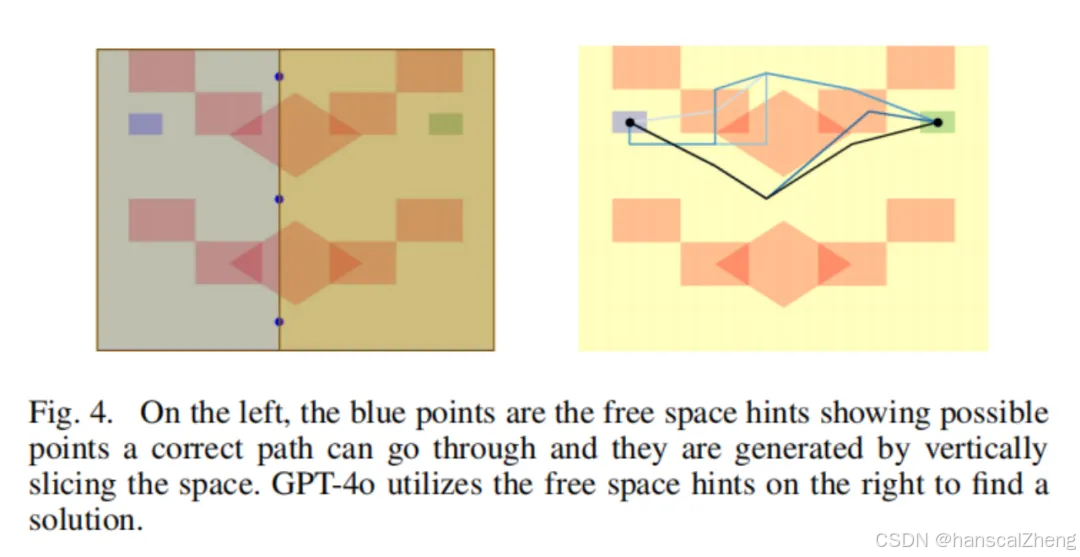
自由空间提示:为LLM提供路径可以安全通过的区域或替代路线的建议。
-
正确前缀提示:确认LLM生成的路径中哪些部分是有效的,鼓励它在这些基础上继续探索。
-
图像提示:向LLM提供路径规划问题的可视化图像(例如障碍物和路径的布局)。
多轮迭代
反馈被提供给LLM后,模型会基于提示重新生成路径解答。该过程会重复多轮,直到LLM找到正确的解答或超过预定的迭代次数。
微调与优化
在多次提示循环中,LLM的表现可以通过微调进一步优化。微调涉及对模型进行特定领域的数据训练,以提高其在特定任务(如路径规划)中的表现。
2 结语
文章探讨了通过结合求解器生成的反馈(如碰撞提示、自由空间提示等),如何提升大型语言模型(LLMs)在路径规划问题中的表现。实验表明,这种反馈能帮助模型解决中等难度问题,但对更复杂的问题仍然效果有限。
论文题目: Can LLMs plan paths with extra hints from solvers?
论文链接: https://arxiv.org/abs/2410.05045
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









