







本文提出了一种新的离线强化学习算法——通过监督微调(Q-SFT)进行Q学习。该方法通过将Q值作为概率进行学习,将Q学习问题转化为一个修改版的监督微调问题。不同于传统的Q学习,Q-SFT不需要重新初始化模型的权重或添加新的预测值头,而是直接利用预训练语言模型(LLM)或视觉语言模型(VLM)的输出概率来优化。通过这种方式,Q-SFT能在多回合任务中有效学习,并能保留从大规模预训练中获得的知识,避免了传统Q学习方法的稳定性问题。在多个语言生成和机器人控制任务上,Q-SFT在表现上优于现有的监督微调和其他价值基础的强化学习方法。
1 Q-SFT算法
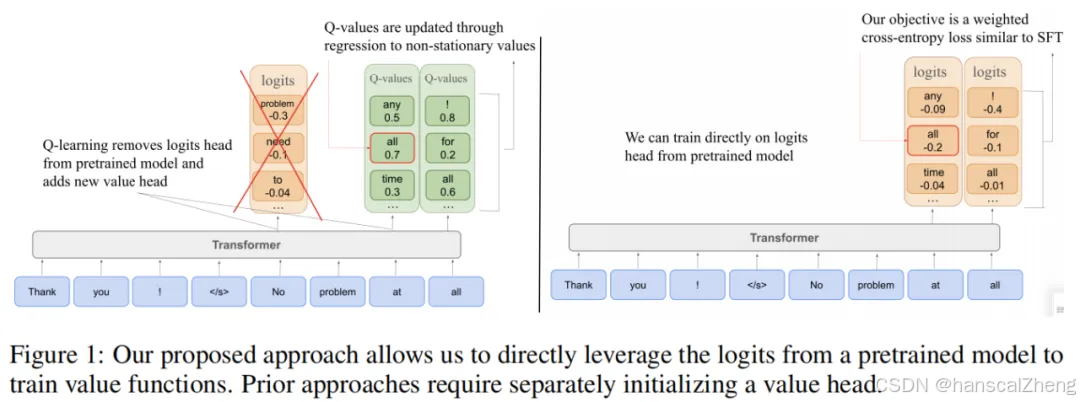
Q-SFT通过将Q学习问题转化为一个修改版的监督微调(SFT)问题,使得Q值的学习能够直接通过模型的输出概率来进行优化。这种方法通过减少传统Q学习中可能存在的不稳定性,提升了在多回合任务中的训练效率,并且能够有效利用预训练的知识来进行优化。
·模型初始化:在Q-SFT中,预训练的智能体模型(如LLM或VLM)不需要重新初始化权重,而是直接利用其预训练阶段学到的概率输出。
·监督微调:与传统Q学习不同,Q-SFT在进行微调时,通过加权交叉熵损失函数,使得智能体在优化过程中学习到的概率值能够近似于目标Q值,而不是通过回归方法来逼近Q值。
·避免重新初始化:Q-SFT避免了传统Q学习方法中需要新增Q值预测头部并重新初始化权重的步骤,从而更好地利用了预训练模型的潜力。
2 结语
本文提出了一种新的离线强化学习算法Q-SFT,通过将Q值学习转化为监督微调问题,从而有效地在多回合任务中微调预训练的智能体模型,提升其在语言生成和机器人控制等任务中的表现。
论文题目: Q-SFT: Q-Learning for Language Models via Supervised Fine-Tuning
论文链接: https://arxiv.org/abs/2411.05193
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









