







文章提出了一个新框架E5-V,用于实现通用多模态嵌入。与传统方法相比,E5-V通过多模态大语言模型(MLLMs),结合提示机制,将不同模态的信息投射到同一嵌入空间中。该方法采用单模态文本训练,大幅减少训练成本,同时表现出优越的多模态嵌入性能。在实验中,E5-V在文本-图像检索、图像组合检索等任务中超过了现有方法。此外,E5-V能够有效处理未见任务提示,展现了强大的零样本推理能力,为通用多模态嵌入模型的设计提供了新思路。
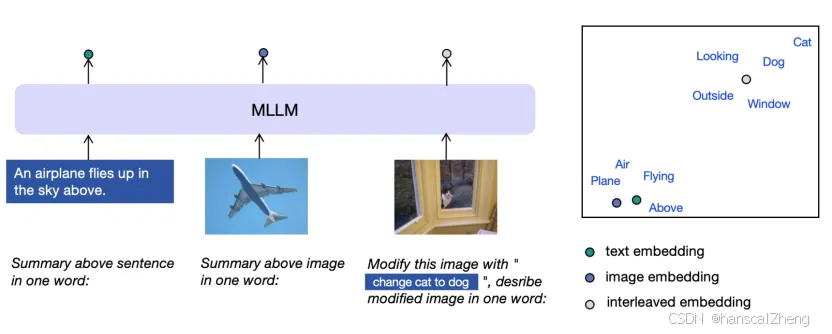
1 E5-V框架
· 多模态嵌入统一:
利用多模态大语言模型(MLLMs)通过提示机制,将不同模态(如图像和文本)的信息投射到同一嵌入空间中。
·使用特定格式的提示(如“总结上述内容为一个词”),消除不同模态之间的嵌入差距。
· 单模态训练策略:
·通过仅使用文本对进行对比学习训练,而非传统的多模态数据(如图文对)。
·移除训练过程中对视觉编码器和多模态投影器的依赖,从而简化训练流程并大幅降低训练成本。
· 基于提示的表征方法:
·设计特定的提示模板,用于明确指示模型如何提取和压缩多模态输入的语义信息。
·例如,图像或文本的语义内容通过提示压缩为单一嵌入表示。
· 嵌入生成流程:
·文本或图像输入通过提示映射到相应的嵌入向量空间。
·模型内部仅保留大语言模型部分作为核心&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









