







Re-ranking Person Re-identification with k-reciprocal Encoding
基础假设:
if a gallery image is similar to the probe in the k-reciprocal nearest neighbors, it is more likely to be a true match.
如果 probe 以及它在gallery里搜索出来的candidate对象 ,的k个nearest相似,那么这一candidate成为true match的可能性更大一些。
1.Introduction
一般来讲,reID可以当做一个检索问题来处理。具体这篇可见
 Top:The query and its 10-nearest neighbors, where P1-P4 are positives, N1-N6 are negatives.
Top:The query and its 10-nearest neighbors, where P1-P4 are positives, N1-N6 are negatives.
Bottom:Each two columns shows 10-nearest neighbors of the corresponding person.
Blue and green box correspond to the probe and positives, respectively. We can observe that the probe person and positive persons are 10-nearest neighbors reciprocally. 由图可见,probe和positive互为10阶-最近邻。
大多数基于re-rank的work,一个基本的假设是,如果一个返回的图像在探测器k-最近的邻居中排名,它很可能是一个真正的匹配,可以用于后续的re-rank。
然而,现实可能偏离理想情况:错误匹配很可能包括在probe的k个最近邻中。例如,在图1中,P1、P2、P3和P4是4个查询图probe的真实匹配,但是它们并不是都包括在top-4中。我们观察到一些错误匹配(N1-N6)获得高排名。这样,直接使用top-k的图像可能在re-ranking系统中引入噪声并损害最终结果。
在文献中,k-reciprocal nearest neighbor[15,35]是解决上述问题的有效方法,即被错误匹配影响的top-k图像。当两幅图像称为k-阶近邻时,任取一幅图像作为探针时,两幅图像中另一幅都排在前k位。因此,k- 阶近邻作为一个更严格的规则,判断两个图像是否匹配。图1可见,probe和true matched images都互为近邻。这一结论用在初始排名列表中来确定true matches,能改进re-rank的结果。
作者方法分三步:
1.将加权k阶邻居集编码成向量,形成k阶特征。然后两幅图像之间的Jaccard距离可以通过它们的k-阶特征来计算。
2.为了获得更鲁棒的k-阶特征,我们开发了一个本地查询扩展方法( local query expansion approach )来进一步提高reid性能。
3.最终距离计算为原始距离和Jaccard距离的加权总和。
随后用于获取重新排序的列表,如图2所示。

图2为人员重新识别提出的重新排序框架。给出一个probe p和一个图库,分别提取每个人的外观特征和k-倒数特征。然后计算每对探测人和gallery人的原始距离d和Jaccard距离dJ。最后的距离dd计算为d和dJ的组合,用来获得建议的排名列表。
3. Proposed Approach
3.1 Problem Definition
给定查询图像p和 gallery set(包含N幅图像,G = {gi | i = 1, 2, …N }),p和gi之间的原始距离可以用马氏距离(Mahalanobis distance)衡量,

其中,xp个xgi分别代表查询图p和检测集gallery中gi的外观特征,M是半正定矩阵。我们可以根据这个距离对p和G排序,距离从小到大排列:
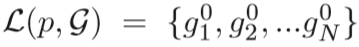 其中,
其中,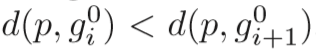
我们的目标是对这个初始排序列表重新排序,使得更多的正样本出现在列表的前段。
3.2 k-reciprocal Nearest Neighbors
首先,定义k-nearest neighbors(k-nn),即排序列表的前k个样本:
|…|代表N(p,k)数量,然后定义 k-reciprocal nearest neighbors (k-rnn),即,满足gi和p均在对方的前k邻近排序里面的 gi 的集合:

由先前的描述分析可知,与k-nearest neighbors相比,k-reciprocal nearest neighbors邻近与probe p更具相关性。 然而,由于不同的光照、姿势、视角和遮挡,正例可能会在k-nearest之外,也就不在k-reciprocal nearest neighbors里面。为解决这一问题,对每一个R(p,k)我们添加了 1/2k-reciprocal nearest neighbors,来增强其鲁棒性:

上式的意思是,对于原本的集合R(p,k)中的每一个样本q,找到它们的k-rnn集合R(q,k/2),对于重合样本数达到一定条件的,则将其**并入R(p,k).**通过这种方式,将原本不在R(p,k)集合中的正样本重新带回来。文中给了一个例子来说明这一过程,如下图所示:

3.3 Jaccard Distance
此部分,重计算probe p和gallery gi的距离。基于:若两张图片相似,他们的k-rnn就会有 重叠部分,重复图像越多,两张图片越相似。通过Jaccard Distance度量他们k-rnn 集合的相似度:

|…|表示集合中样本的数量,虽然这一方法可以度量两张图片的相似度,但是仍有一些显见的缺点:
(1)计算两个集合的交集和并集十分耗时,尤其是Jaccard Distance要计算所有图片对。 一个可选办法是**将邻近集编码成一个等效但更简单的向量,**极大的减少计算复杂度。
(2)所有的邻近集样本在计算距离时都是一样的权重,这样得到一个简单但是不具备区分性的邻近集。实际上,**距离更接近probe的更可能是正样本。*因此,在原始的距离基础上重新计算权重,给更近的样本分配更大的权重是合理的。
(3)在衡量两个人之间的相似度时,仅仅考虑上下文信息就会造成相当大的障碍,因为 不可避免的差异 使得区分足够的上下文信息变得困难。因此,合并原始距离和Jaccard距离对于鲁棒距离非常重要。
通过k-rnn解决上述前两个问题 ,把k-rnn集合编码成向量Vp=[Vp,g1 ,Vp,g2 ,…, Vp,gN],由一个二进制指示函数初定义:

这样,k-rnn集合可以看做一个N维向量,向量中每项表示对应的图像是否包含在R(p,k)中。然而,这一函数仍然是每个邻近样本权重一致。因此,我们根据probe 与其邻居之间的 原始距离重新分配权重, 用高斯核函数来重新定义两两之间的距离:

这样权重就hard to soft,越邻近权重越大,越远权重越小。(由 d(p,gi) 到 Vp,gi )这样,交集和并集中的样本数可以计算为:

其中,min和max对两个输入向量进行基于元素的最小化和最大化操作。min/max = 相似最远的情况/相似取最近的情况 。||…||是指L1正则化,相加求和。这样更新Jaccard距离:

由等式(5)到(10),实际上是将集合比较问题转化为纯粹的向量计算,实践起来更简单。
3.4 local query expansion
由于来自同一个类的图像可能具有相似的特性,我们使用probe的k-rnn近邻来实现 本地查询扩展。本地查询扩展定义为:

对每个Vp向量,看作是他的k-rnn集合的性凉的平均。
因此,k-倒数特征Vp由 probe p的k近邻扩展。注意,我们在probe p和库gis上都实现了这个查询扩展。由于k近邻中存在噪声,我们将本地查询展开中使用的N(p,k)的大小限制为较小的值。为了区分式7和式11中使用的R(gi,k)和N(p,k)的大小,我们将前者分别表示为k1,后者表示为k2,其中k1 > k2.
3.5 Final Distance
在本节中,我们将重点讨论式5的第三个缺点。现有的重排序方法大多忽略了原距离在重排序中的重要性,我们将原距离和Jaccard距离联合起来对初始排序列表进行修正,最终的距离dd定义为:

其中aaa∈[0,1]表示惩罚因子,当aaa=0时,惩罚距离probe p较远的gallery,只考虑k倒数距离。反之,当aaa = 1时,只考虑初始距离。aaa的效果将在第4节中讨论。最后,按最终距离的升序排序,得到修正后的排序表L*(p,G)。
3.6 实验分析
在该方法中,大部分计算量都集中在对所有gallery对的成对距离计算上。假设gallery集的大小为:N,距离度量所需的计算复杂度为:O(N^ 2), 排序过程分别为:O(N^ 2logN)。但在实际应用中,我们可以离线计算成对距离,提前得到gallery的排名列表。因此,给定一个新的probe p,我们只需要用O(N)计算复杂度计算出p和gallery之间的成对距离,并用O(NlogN)计算复杂度对所有的最终距离进行排序。
4 Experiments
4.2 Datasets and Settings

评价指标:
我们使用两个评估指标来评估所有数据集上的reid方法的性能。首先是累积匹配特性(CMC)。将reid作为一个排序问题,我们报告了rank-1处的累积匹配精度。另一个是将reid作为对象检索问题考虑的平均平均精度(mAP),如[50]所述。
特征表示:
local maximal occurence(LOMO)特征用于表示人的外貌[24]。它对于视角和光照 变化是鲁棒的。此外,还利用了[54]中提出的id判别嵌入(IDE)特性。针对CaffeNet[19]和ResNet-50[14]等分类模型,对IDE萃取器进行了有效的训练。它为每个图像生成1,024-dim(或2,048-dim)向量,这在大规模的reid数据集中是有效的。为了便于描述,我们将CaffeNet和ResNet-50上的IDE分别缩写为IDE ©和IDE ®。我们使用这两个方法作为reid框架的基线.
实验分析
The baseline methods are LOMO [24] and IDE [54] trained on CaffeNet。关于k1,k2,aaa设置对实验效果的影响。


实验效果精彩表现:

参考link















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









