






🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍖 参考原作者:K同学啊|接辅导、项目定制
🏡 我的环境:
语言环境:Python3.8
深度学习环境:Pytorch
需要分别进行:
一、前期准备
1.设置GPU
2.导入数据
3.划分数据集
二、构建简单的CNN网络
三、训练模型
1.设置超参数
2.编写训练函数
3.编写测试函数
4.正式训练
四、结果可视化
1.LOSS和ACCURACY图
2.指定图片进行预测
五、保存并加载模型
目标1.设置动态学习率
目标2.测试accuracy
整体代码:
import torch
import os,PIL,random,pathlib,warnings
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import torchvision,time
import torch.nn as nn
from torchsummary import summary
from torchvision.models import vgg16
num_class=2
def localDataset(data_dir):
data_dir=pathlib.Path(data_dir)
data_paths=list(data_dir.glob('*'))
classNames=[str(path).split('\\')[-1] for path in data_paths]
print("className:",classNames,'\n')
train_transforms=torchvision.transforms.Compose([
torchvision.transforms.Resize([224,224]),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225])
])
total_data=torchvision.datasets.ImageFolder(data_dir,transform=train_transforms)
print(total_data,'\n')
train_size=int(0.8*len(total_data))
test_size=len(total_data)-train_size
print("Train_size:",train_size,"Test_size",test_size,'\n')
train_data,test_data=torch.utils.data.random_split(total_data,[train_size,test_size])
return classNames,train_data,test_data
def displayData(imgs,root,show_flag):
plt.figure(figsize=(20,5))
for i,imgs in enumerate(imgs[:20]):
npimg=imgs.numpy().transpose(1,2,0)
plt.subplot(20,5,i+1)
plt.imshow(npimg,cmap=plt.cm.binary)
plt.axis('off')
plt.savefig(os.path.join(root,'DatasetDispaly.png'))
if show_flag:
plt.show()
else:
plt.close('all')
def loadData(train_ds,test_ds,batch_size,root='output',show_flag=False):
train_dl=torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True)
test_dl=torch.utils.data.DataLoader(test_ds,batch_size=batch_size)
for x,y in train_dl:
print("shape of x [N,C,H,W]:",x.shape)
print("shape of y:",y.shape)
break
imgs,labels=next(iter(train_dl))
print("Image shape:",imgs.shape,'\n')
if not os.path.exists(root) or not os.path.isdir(root):
os.mkdir(output)
displayData(imgs,root,show_flag=show_flag)
return train_dl,test_dl
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(3,12,kernel_size=5,padding=0),
nn.BatchNorm2d(12),
nn.ReLU()
)
self.conv2=nn.Sequential(
nn.Conv2d(12,12,kernel_size=5,padding=0),
nn.BatchNorm2d(12),
nn.ReLU()
)
self.pool3=nn.Sequential(
nn.MaxPool2d(2),
nn.Dropout(p=0.2)
)
self.conv4=nn.Sequential(
nn.Conv2d(12,24,kernel_size=5,padding=0),
nn.BatchNorm2d(24),
nn.ReLU()
)
self.conv5=nn.Sequential(
nn.Conv2d(24,24,kernel_size=5,padding=0),
nn.BatchNorm2d(24),
nn.ReLU()
)
self.pool6=nn.Sequential(
nn.MaxPool2d(2),
nn.Dropout(p=0.2)
)
self.conv7=nn.Sequential(
nn.Conv2d(24,48,kernel_size=5,padding=0),
nn.BatchNorm2d(48),
nn.ReLU()
)
self.conv8=nn.Sequential(
nn.Conv2d(48,48,kernel_size=5,padding=0),
nn.BatchNorm2d(48),
nn.ReLU()
)
self.pool9=nn.Sequential(
nn.MaxPool2d(2),
nn.Dropout(p=0.2)
)
self.fc=nn.Sequential(
nn.Linear(48*21*21,num_class)
)
def forward(self,x):
batch_size=x.size(0)
x=self.conv1(x)
x=self.conv2(x)
x=self.pool3(x)
x=self.conv4(x)
x=self.conv5(x)
x=self.pool6(x)
x=self.conv7(x)
x=self.conv8(x)
x=self.pool9(x)
x=x.view(batch_size,-1)
x=self.fc(x)
return x
class Model_vgg16(nn.Module):
def __init__(self):
super(Model_vgg16, self).__init__()
self.sequ1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1), # 64*224*224
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1), # 64*224*224
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), # 64*112*112
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1), # 128*112*112
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1), # 128*112*112
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), # 128*56*56
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1), # 256*56*56
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1), # 256*56*56
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1), # 256*56*56
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), # 256*28*28
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1), # 512*28*28
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1), # 512*28*28
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1), # 512*28*28
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), # 512*14*14
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1), # 512*14*14
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1), # 512*14*14
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1), # 512*14*14
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) # 512*7*7
)
self.pool2 = nn.AdaptiveAvgPool2d(output_size=(7, 7)) # 512*7*7
self.sequ3 = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=25088, out_features=4096, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=4096, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=17,bias=True),
nn.Linear(17,2)
)
def forward(self, x):
x = self.sequ1(x)
x = self.pool2(x)
x=self.sequ3(x)
return x
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
#print("Bottleneck")
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class Model_K(nn.Module):
def __init__(self):
super(Model_K, self).__init__()
# 卷积模块
self.Conv = Conv(3, 32, 3, 2)
# C3模块1
self.C3_1 = C3(32, 64, 1, 2)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=802816, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=2)
)
def forward(self, x):
x = self.Conv(x)
x = self.C3_1(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def train(train_dl,model,loss_fn,opt):
size=len(train_dl.dataset)
num_batches=len(train_dl)
train_acc,train_loss=0,0
for x,y in train_dl:
x,y=x.to(device),y.to(device)
pre=model(x)
loss=loss_fn(pre,y)
opt.zero_grad()
loss.backward()
opt.step()
train_acc +=(pre.argmax(1)==y).type(torch.float).sum().item()
train_loss +=loss.item()
train_acc/=size
train_loss/=num_batches
return train_acc,train_loss
def test(test_dl,model,loss_fn):
size=len(test_dl.dataset)
num_batches=len(test_dl)
test_acc,test_loss=0,0
with torch.no_grad():
for x, y in test_dl:
x, y = x.to(device), y.to(device)
pre = model(x)
loss = loss_fn(pre, y)
test_acc += (pre.argmax(1) == y).type(torch.float).sum().item()
test_loss += loss.item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
def displayResult(train_acc,test_acc,train_loss,test_loss,start_epoch,epochs,output):
epochs_range=range(start_epoch,epochs)
plt.figure(figsize=(20,5))
plt.subplot(1,2,1)
plt.plot(epochs_range,train_acc,label="Train_acc")
plt.plot(epochs_range,test_acc,label="Tesy_acc")
plt.legend(loc="lower right")
plt.title("train and test Acc")
plt.subplot(1,2,2)
plt.plot(epochs_range,train_loss,label="Train_loss")
plt.plot(epochs_range,test_loss,label="Test_loss")
plt.legend(loc="upper right")
plt.title("Train and Test Loss")
if not os.path.exists(output) or not os.path.isdir(output):
os.mkdir(output)
plt.savefig(os.path.join(output,"Accuracyloss.png"))
plt.show()
def predict(model, img_path,classeNames):
img = Image.open(img_path)
train_transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
torchvision.transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
torchvision.transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
img = train_transforms(img)
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
img = img.to(device).unsqueeze(0)
output = model(img)
# print(output.argmax(1))
_, indices = torch.max(output, 1)
percentage = torch.nn.functional.softmax(output, dim=1)[0] * 100
perc = percentage[int(indices)].item()
result = classeNames[indices]
print('predicted:', result, perc)
def save_file(output,model,epoche='best'):
saveFile=os.path.join(output,'epoch'+str(epoche)+'.pkl')
torch.save(model.state_dict(),saveFile)
if __name__=="__main__":
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("Using Device is {}".format(device))
data_dir="./data"
output='./output_vgg'
num_classes,train_ds,test_ds=localDataset(data_dir)
batch_size=64
train_dl,test_dl=loadData(train_ds,test_ds,batch_size=batch_size,root=output,show_flag=True)
epoches=100
start_epoch=0
train_acc=[]
train_loss=[]
test_acc=[]
test_loss=[]
best_acc=0.0
#model=Model().to(device)
model=Model_K().to(device)
summary(model,(3,224,224))
loss_fn=nn.CrossEntropyLoss()
learn_rate=1e-3
opt=torch.optim.SGD(model.parameters(),lr=learn_rate)
print("---Starting train---")
for epoche in range(start_epoch,epoches):
model.train()
epoch_train_acc,epoch_train_loss=train(train_dl,model,loss_fn,opt)
model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,model,loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
if(epoch_test_acc>best_acc):
best_acc=epoch_test_acc
save_file(output, model)
template=('Epoch:{:2d}/{:2d},train_acc:{:.1f}%,train_loss:{:.3f},test_acc{:.1f}%,test_loss{:.3f},best_acc:{:.1f}%')
print(time.strftime('[%Y-%m-%d %H:%M:%S)]'),template.format(epoche+1,epoches,epoch_train_acc*100,epoch_train_loss,epoch_test_acc*100,epoch_test_loss,best_acc*100))
print("Done")
displayResult(train_acc,test_acc,train_loss,test_loss,start_epoch,epoches,output)
imgs_path='./data/Monkeypox/M01_01_06.jpg'
predict(model,imgs_path,classeNames=num_classes)
# save_file(output,model,epoches)
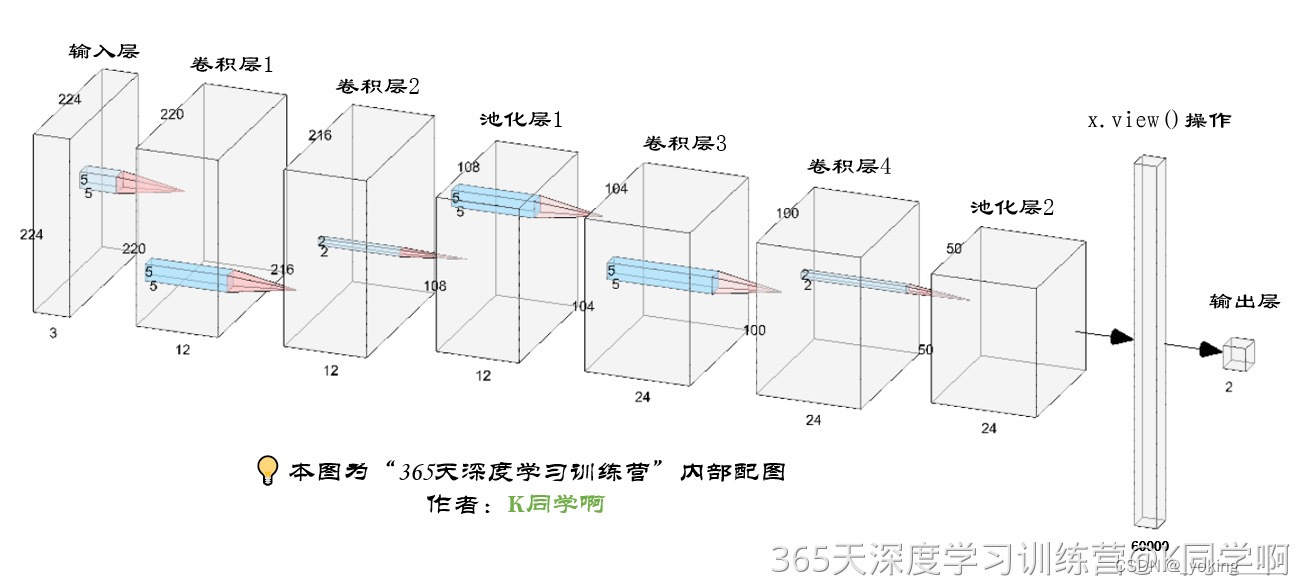
模型图:
运行简短截图:

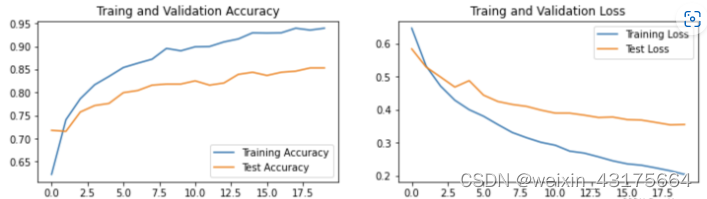
学习总结:
调整模型参数和设置不同的动态学习率都会影响运行的结果。















 3265
3265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









