






1. 准备工作
本教程大部分来自于LangChain官网,运行本教程代码的前提条件:
- 能科学上网
- OPENAI账户里需要充值,因为调用OPENAI的API是付费的
(1). B站教程
(2). 几个API密钥获取方法
(1)OpenAI官网获取密钥:
OPENAI官网获取KEY
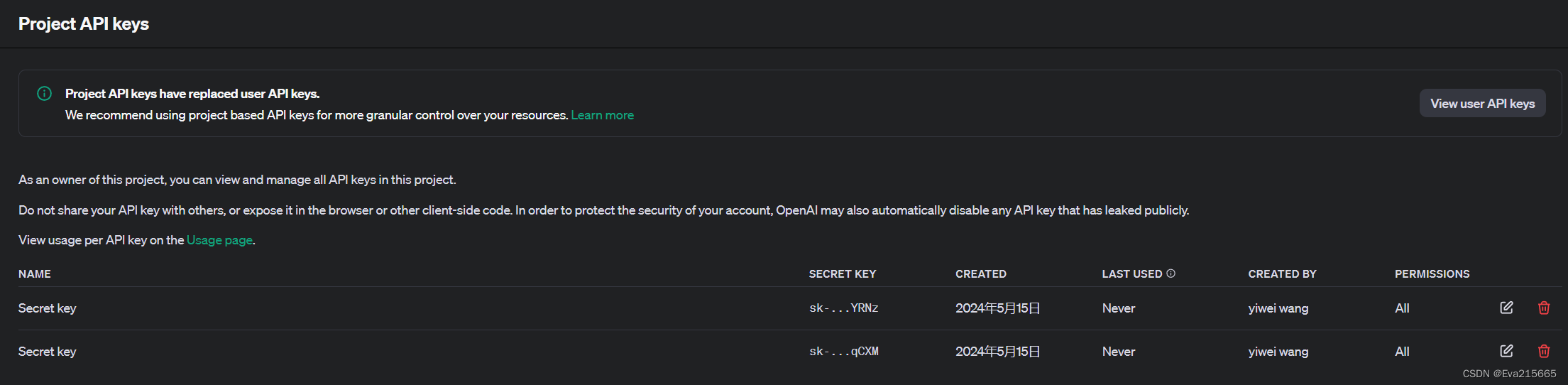
(2)LangChain API获取API_KEY
LangChain
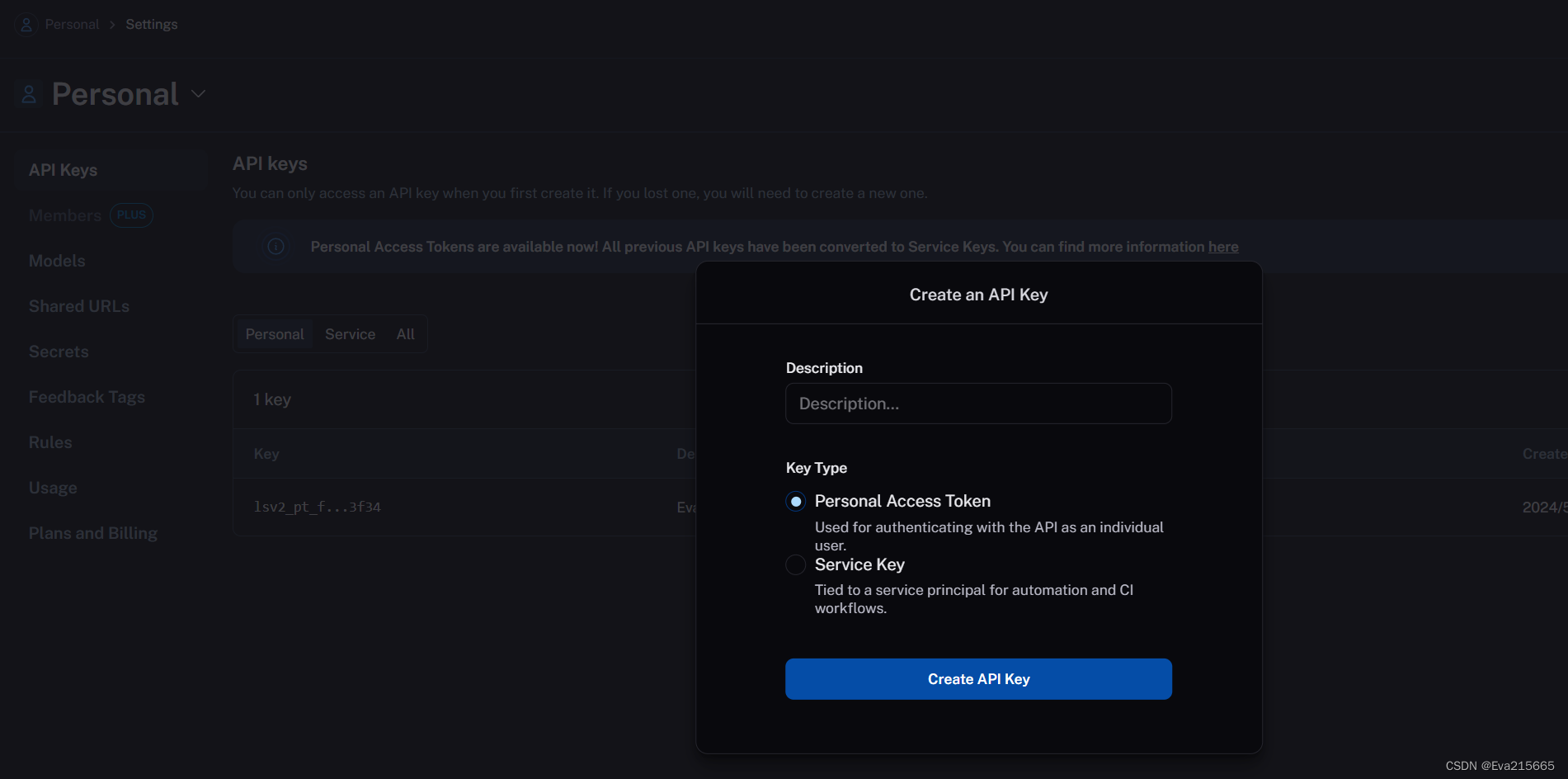
事先获取以上几个API的密钥,密钥获取以后,需要设置环境变量,这里采用的是终端设置:
- OPENAI_API_KEY
linux:
export OPENAI_API_KEY=xxxxxxxxxxxxxx
windows:
set OPENAI_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
- LANGCHAIN_API_KEY
下面这个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其实是LANGCHAIN_API_KEI
linux:
export TAVILY_API_KEY=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
windows:
set TAVILY_API_KEY=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
- SERPAPI_API_KEY
linux:
export SERPAPI_API_KEY=499bc8cbbd74f3cee704a689a2ff6895cdc109e592032b7bff0f4789eb6508cf
windows:
set SERPAPI_API_KEY=499bc8cbbd74f3cee704a689a2ff6895cdc109e592032b7bff0f4789eb6508cf
2 LangChain官网的示例
LangChain官网一直在更新,所以以下代码可能会有变动
import os
import sys
os.path.dirname(sys.executable)
os.environ['http_proxy'] = 'http://127.0.0.1:9300'
os.environ['https_proxy'] = 'http://127.0.0.1:9300'
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings
# Langchain共有140多个加载器
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
# 加载之后的数据放在 data 里面
data = loader.load()
index = VectorstoreIndexCreator().from_loaders([loader])
print(index.query("What is Task Decomposition?"))
# --------------step2 Split 分裂------------------------#
# 上万字符,LLM消耗不了,需要分裂
# RecursiveCharacterTextSplitter切分器
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
# print(len(all_splits))
# print(all_splits[0])
# --------------step3 Store 将切分以后的向量存储------------------------#
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 下面这一句消耗了OPENAI了OpenAIEmbeddings()的API,是付费的,需要OPENAI账户里有钱
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
# --------------step4 Retrieve 检索,向sqlite数据库提问------------------#
question = "What are the approaches to Task Decomposition?"
# 相关度检索
docs = vectorstore.similarity_search(question)
print(len(docs))
print(docs[0])
# --------------step5 Generate 生成,用大语言模型进行生成------------------#
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever())
print(qa_chain({"query": question}))
在终端运行后效果:

3. 以RAG的形式重构上述代码
示例来源于LangChain的官网Use cases->Q&A with RAG->Quickstart
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_chroma import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
import getpass
import os
from langchain_openai import ChatOpenAI
# 定义llm,使用的gpt3.5
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
# We’ll use a prompt for RAG that is checked into the LangChain prompt hub (here)
# 可以使用预定义的提示词模板
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 我们将使用LCEL Runnable 协议来定义链,使我们能够 - 以透明的方式将组件和函数连接在一起 - 在 LangSmith 中自动跟踪我们的链 - 开箱即用地进行流式传输、异步和批量调用
# rag_chain = (
# {"context": retriever | format_docs, "question": RunnablePassthrough()}
# | prompt
# | llm
# | StrOutputParser()
# )
# 也可以使用自定义的提示词模板
from langchain_core.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
custom_rag_prompt = PromptTemplate.from_template(template)
# 构造chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
for chunk in rag_chain.stream("What is Task Decomposition?"):
print(chunk, end="", flush=True)
# cleanup
# vectorstore.delete_collection()
在终端运行结果,很有礼貌的在最后一句加上了一个Thanks for asking!

再重新问一个
rag_chain.invoke("What is Beijing?")
回答如下

4. 试一下LangChain的抽取结构化输出
以下示例来自LangChain官网的Use cases->Extracting structured output->Quickstart
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""Information about a person."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that:
# 1. Each field is an `optional` -- this allows the model to decline to extract it!
# 2. Each field has a `description` -- this description is used by the LLM.
# Having a good description can help improve extraction results.
name: Optional[str] = Field(default=None, description="The name of the person")
hair_color: Optional[str] = Field(
default=None, description="The color of the peron's hair if known"
)
height_in_meters: Optional[str] = Field(
default=None, description="Height measured in meters"
)
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Define a custom prompt to provide instructions and any additional context.
# 1) You can add examples into the prompt template to improve extraction quality
# 2) Introduce additional parameters to take context into account (e.g., include metadata
# about the document from which the text was extracted.)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert extraction algorithm. "
"Only extract relevant information from the text. "
"If you do not know the value of an attribute asked to extract, "
"return null for the attribute's value.",
),
# Please see the how-to about improving performance with
# reference examples.
# MessagesPlaceholder('examples'),
("human", "{text}"),
]
)
# from langchain_mistralai import ChatMistralAI
# llm = ChatMistralAI(model="mistral-large-latest", temperature=0)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
runnable = prompt | llm.with_structured_output(schema=Person)
text = "Alan Smith is 6 feet tall and has blond hair."
print(runnable.invoke({"text": text}))
在终端运行时报错:
File "D:\Code\LangChain\envLangChain\lib\site-packages\httpx\_transports\default.py", line 86, in map_httpcore_exceptions
raise mapped_exc(message) from exc
httpx.LocalProtocolError: Illegal header value b'Bearer '
搜了一下,百度给出以下答案
httpx.LocalProtocolError: Illegal header value b’Bearer ’
错误解释:
httpx.LocalProtocolError: Illegal header value b’Bearer ’ 表示你在使用 httpx 库发送 HTTP 请求时,试图设置一个 HTTP 头部的值为 Bearer ,但这个值是非法的。HTTP 规范不允许在头部字段中有空格,并且 Bearer 后面应该有一个访问令牌。
解决方法:
确保在设置 Authorization 头部时,提供完整的 Bearer 认证令牌。例如,如果你的访问令牌是 your_token,则应该设置为 Authorization: Bearer your_token。
代码示例:
import httpx
# 假设你有一个访问令牌
token = "your_token"
headers = {
"Authorization": f"Bearer {token}" # 确保这里不包含任何空格
}
url = "http://example.com"
try:
async with httpx.AsyncClient() as client:
response = await client.get(url, headers=headers)
print(response.status_code)
print(response.text)
except httpx.LocalProtocolError as e:
print(f"Error: {e}")
于是按照上面的提示,找到default.py文件,将其416行和427行的空格删掉
运行后又报以下错误,搜了一下,应该是需要API_KEY
httpx.HTTPStatusError: Error response 401 while fetching https://api.mistral.ai/v1/chat/completions: Bearer token not found
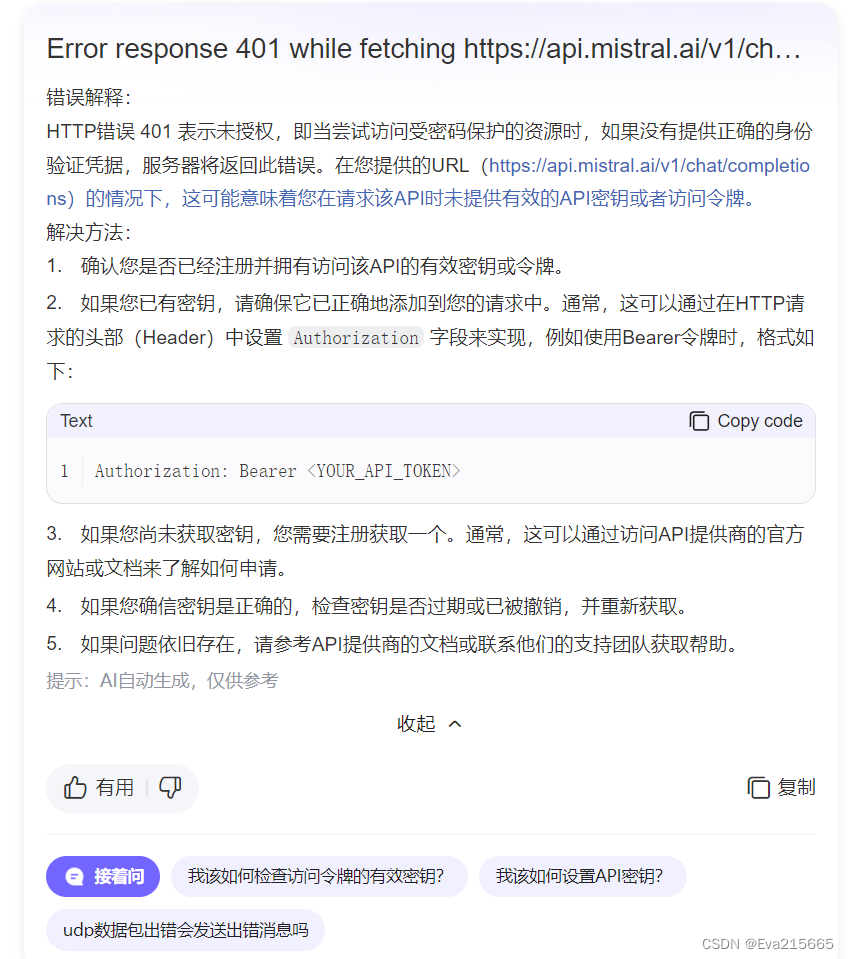
偷懒先没有去找MistralAI的KEY了,直接把MistralAI模型换成OPENAI的试试:
注释掉了这两行
# from langchain_mistralai import ChatMistralAI
# llm = ChatMistralAI(model="mistral-large-latest", temperature=0)
换成以下两行
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
就text = "Alan Smith is 6 feet tall and has blond hair."这个简单的抽取任务来说,抽取效果还不错!
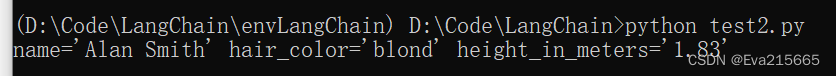
5. 使用Agent+LLM组合的形式多次调用工具并呈现解决问题的思考过程
以下示例来自LangChain官网Use cases->Tool use and agents->Quickstart
# -------------------Step1 创建自定义的工具---------------------------
# 首先需要创建一个调用的工具。对于此示例,我们将从函数创建自定义工具。有关创建自定义工具的更多信息,请参阅本指南
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
# print(multiply.name)
# print(multiply.description)
# print(multiply.args)
# 非agent的方式试一下
multiply.invoke({"first_int": 4, "second_int": 5})
# 使用bind_tools将工具的定义作为对llm的每次调用的一部分传入,以便llm可以在适当的时候调用该工具
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# 将自定义的工具multiply传入llm
llm_with_tools = llm.bind_tools([multiply])
msg = llm_with_tools.invoke("whats 5 times forty two")
msg.tool_calls
# -----------------------Invoking the tool-------------------------------
from operator import itemgetter
chain=llm_with_tools | (lambda x: x.tool_calls[0]["args"]) | multiply
# print(chain.invoke("What's four times 23"))
# -------------------------------关于Agent---------------------------------
'''
上述的问题在于,当我们知道用户输入所需的工具的特定顺序时,链就足够了。但大多数情况下,llm使用某个工具(比如本例中的乘法),
是取决于用户问了什么,即用户输入。在这些情况下,我们希望让llm本身去决定使用工具的次数和顺序,Agent能够
帮助我们实现。
LangChain提供了很多针对不同用例进行优化的内置代理
我们将使用tool calling agent,这通常是最可靠的类型,也是大多数用例推荐的类型
'''
from langchain import hub
from langchain.agents import AgentExecutor, create_tool_calling_agent
# 使用langchain预定义的prompt
# Get the prompt to use - can be replaced with any prompt that includes variables "agent_scratchpad" and "input"!
prompt = hub.pull("hwchase17/openai-tools-agent")
prompt.pretty_print()
# Agent可以方便的使用各种工具
@tool
def add(first_int: int, second_int: int)->int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base:int, exponent:int)->int:
"Exponentiate the base to the exponent power."
return base**exponent
# 将自己定义的三个tool放在一起
tools = [multiply, add, exponentiate]
# Construct the tool calling agent
agent = create_tool_calling_agent(llm, tools, prompt)
# Create an agent executor by passing in the agent and tools
# 创建一个代理执行器,把代理和工具传给它
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# With an agent, we can ask questions that require arbitrarily-many uses of our tools:
# 使用代理,我们可以提出需要任意多次使用我们的工具的问题:
# text="input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result"
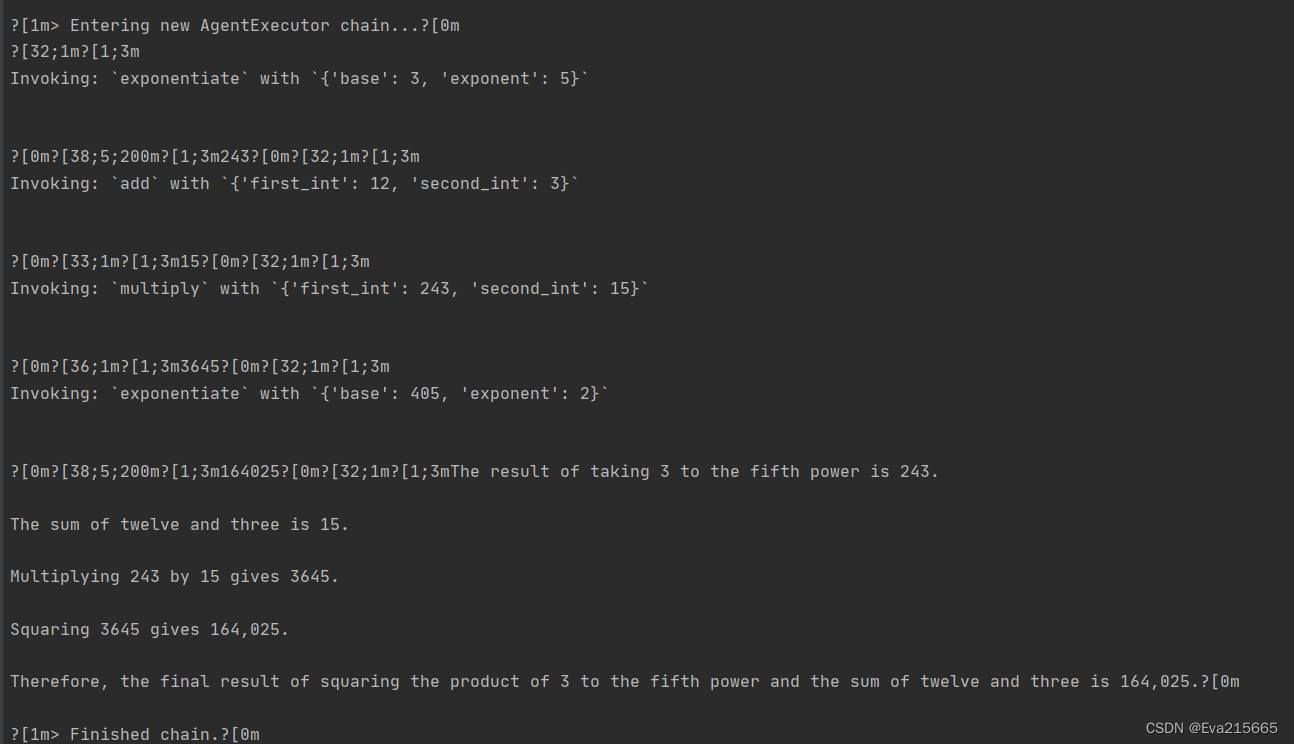
agent_executor.invoke(
{
"input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result"
}
)
终端的运行结果,可以看出,用户提问取3的五次方,乘以12和3的总和,然后将整个结果平方这个问题时,Agent将这个过程每一步的思考与实施结果呈现出来。
6. 让LLM在多种工具之间进行选择
以下示例来自Use cases->Tool use and agents->Choosing between multiple tools
使用一个工具和使用多个工具之间的主要区别在于,我们无法确定模型将预先调用哪个工具,
因此我们无法像在快速入门中那样将特定工具硬编码到我们的链中。
相反,我们将添加call_tools, 一个RunnableLambda,它通过工具调用获取输出 AI 消息并路由到正确的工具。
# 回想一下我们已经有了一个multiply工具
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
# 现在我们可以向其中添加一个exponentiateandadd工具:
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
'''
使用一个工具和使用多个工具之间的主要区别在于,我们无法确定模型将预先调用哪个工具,
因此我们无法像在快速入门中那样将特定工具硬编码到我们的链中。
相反,我们将添加call_tools, 一个RunnableLambda,它通过工具调用获取输出 AI 消息并路由到正确的工具。
'''
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
from operator import itemgetter
from typing import Dict, List, Union
from langchain_core.messages import AIMessage
from langchain_core.runnables import (
Runnable,
RunnableLambda,
RunnableMap,
RunnablePassthrough,
)
tools = [multiply, exponentiate, add]
llm_with_tools = llm.bind_tools(tools)
tool_map = {tool.name: tool for tool in tools}
def call_tools(msg: AIMessage) -> Runnable:
"""Simple sequential tool calling helper."""
tool_map = {tool.name: tool for tool in tools}
tool_calls = msg.tool_calls.copy()
for tool_call in tool_calls:
tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"])
return tool_calls
chain = llm_with_tools | call_tools
# 试一下,可以看到,llm会根据不同的问题,选择调用不同的工具
print(chain.invoke("What's 23 times 7"))
print(chain.invoke("add a million plus a billion"))
print(chain.invoke("cube thirty-seven"))
在终端结果如图,可以看到,llm会根据不同的问题,选择调用不同的工具

7. 使用不支持工具调用的模型
本节主题是,使用不支持工具调用的模型,我们将构建一个不依赖于任何特殊模型 API。
示例来自Use cases->Tool use and agents->Using models that don't support tool calling添加链接描述
# 本节主题是:使用不支持工具调用的模型,我们将构建一个不依赖于任何特殊模型 API
# ----------step1 创建一个工具-------------------------
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
# ----------step2 创建我们的提示-------------------------
'''
我们需要编写一个提示,指定模型可以访问的工具、这些工具的参数以及模型所需的输出格式。
在本例中,我们将指示它输出以下形式的 JSON blob {"name": "...", "arguments": {...}}。
'''
from langchain.tools.render import render_text_description
rendered_tools = render_text_description([multiply])
rendered_tools
from langchain_core.prompts import ChatPromptTemplate
system_prompt = f"""You are an assistant that has access to the following set of tools. Here are the names and descriptions for each tool:
{rendered_tools}
Given the user input, return the name and input of the tool to use. Return your response as a JSON blob with 'name' and 'arguments' keys."""
prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("user", "{input}")]
)
# ----------step3 使用JsonOutputParser将模型输出解析为JSON-------------------------
from langchain_core.output_parsers import JsonOutputParser
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = prompt | model | JsonOutputParser()
print(chain.invoke({"input": "what's thirteen times 4"}))
# ----------------------------step3 调用该工具------------------------------------
# 我们可以通过向该工具传递llm生成的“参数”来调用该工具作为“链”的一部分
# 上述chain.invoke以后,根据我们预先定义的prompt,输出为:{'name': 'multiply', 'arguments': {'first_int': 13, 'second_int': 4}}
# 可以看出,llm已经决定了对于用户提出的问题,将调用multiply这个工具,并且也解析出了参数为13和4
# 下一步,可以通过向multiply工具传递llm解析出的“参数”来调用该工具作为“链”的一部分
from operator import itemgetter
chain = prompt | model | JsonOutputParser() | itemgetter("arguments") | multiply
print(chain.invoke({"input": "what's thirteen times 4"})) # 这样以后,模型就直接输出了结果52
# ----------------------------------multiply从多种工具调用------------------------------------
# 假设我们有很多个工具,希望链能够从中进行选择
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
# 通过函数调用,我们可以这样做
# 如果我们想运行模型选择的工具,我们可以使用基于llm输出返回工具的函数来执行此操作
# 具体来说,函数将返回它自己的子链,该子链获取模型输出的“参数”不分并将其传递给所选工具
tools = [add, exponentiate, multiply]
def tool_chain(model_output):
tool_map = {tool.name: tool for tool in tools}
chosen_tool = tool_map[model_output["name"]]
return itemgetter("arguments") | chosen_tool
rendered_tools = render_text_description(tools)
system_prompt = f"""you are an assistant that has access to the following set of tools. Here are the names and
description for each tool:
{rendered_tools}
Given the user input, return the name and input of the tool to use.
Return your response as a JSON blob with 'name' and 'arguments' keys.
"""
prompt = ChatPromptTemplate.from_messages([("system", system_prompt), ("user", "{input}")])
print(chain.invoke({"input": "what's 3 plus 1132"}))
# -----------------------------返回工具 | 输入----------------------------------------------
# 不仅返回工具输出,而且返回工具输入也很有帮助。我们可以通过RunnablePassthrough.assign工具输出使用 LCEL 轻松完成此操作。
# 这将获取 RunnablePassrthrough 组件(假设是字典)的任何输入,并为其添加一个键,同时仍然传递当前输入中的所有内容
from langchain_core.runnables import RunnablePassthrough
chain = (prompt | model | JsonOutputParser() | RunnablePassthrough.assign(output=tool_chain))
# 试一下
print(chain.invoke({"input":"waht's 3 times 1132"}))
在终端的运行效果,最后一行,输出了llm选用的tool,即multiply,输出了解析出的两个参数即3和1132,输出了结果即3396

8. 人在环,人机交互,加入人的干预
有些工具我们不信任模型能够自行执行。在这种情况下,我们可以做的一件事是在调用工具之前要求人工批准。
下面的示例来自Use cases->Tool use and agents->Human-in-the-loop
# 有些工具我们不信任模型能够自行执行。在这种情况下,我们可以做的一件事是在调用工具之前要求人工批准。
# import getpass
# import os
# os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# | echo: false
# | outout: false
# from langchain_anthropic import ChatAnthropic
# llm = ChatAnthropic(model="claude-3-sonnet-20240229", temperature=0)
from operator import itemgetter
from typing import Dict, List
from langchain_core.messages import AIMessage
from langchain_core.runnables import Runnable, RunnablePassthrough
from langchain_core.tools import tool
@tool
def count_emails(last_n_days: int) -> int:
"""Multiply two integers together."""
return last_n_days * 2
@tool
def send_email(message: str, recipient: str) -> str:
"Add two integers."
return f"Successfully sent email to {recipient}."
tools = [count_emails, send_email]
llm_with_tools = llm.bind_tools(tools)
def call_tools(msg: AIMessage) -> List[Dict]:
"""Simple sequential tool calling helper."""
tool_map = {tool.name: tool for tool in tools}
tool_calls = msg.tool_calls.copy()
for tool_call in tool_calls:
tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"])
return tool_calls
chain = llm_with_tools | call_tools
print(chain.invoke("how many emails did i get in the last 5 days?"))
# 可以向我们的 tool_chain 函数添加一个简单的人工批准步骤:
import json
def human_approval(msg: AIMessage) -> Runnable:
tool_strs = "\n\n".join(
json.dumps(tool_call, indent=2) for tool_call in msg.tool_calls
)
input_msg = (
f"Do you approve of the following tool invocations\n\n{tool_strs}\n\n"
"Anything except 'Y'/'Yes' (case-insensitive) will be treated as a no."
)
resp = input(input_msg)
if resp.lower() not in ("yes", "y"):
raise ValueError(f"Tool invocations not approved:\n\n{tool_strs}")
return msg
chain = llm_with_tools | human_approval | call_tools
# 加入了人工交互环节,需要人按下确定按钮
print(chain.invoke("how many emails did i get in the last 5 days?"))
print(chain.invoke("Send sally@gmail.com an email saying 'What's up homie'"))
9. Few-shot prompt template 少样本提示模板
构建一个小的提示词模板,如下
examples = [
{'input': '海盗', 'output': '船'},
{'input': '飞行员', 'output': '飞机'},
{'input': '驾驶员', 'output': '汽车'},
{'input': '鸟', 'output': '鸟巢'},
{'input': '医生', 'output': '手术台'},
{'input': '苏轼','output':'北宋'},
{'input': '辛弃疾', 'output': '抗金'}
]
用上述这个微小型的提示词模板,调用gpt3.5,代码如下。
LangChain官网上FewShotPromptTemplateAPI文档(https://api.python.langchain.com/en/latest/prompts/langchain_core.prompts.few_shot.FewShotPromptTemplate.html)
import os
from langchain.prompts import PromptTemplate, FewShotPromptTemplate
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
from langchain_chroma import Chroma
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0.9)
# 构造一个很小的提示模板
examples = [
{'input': '海盗', 'output': '船'},
{'input': '飞行员', 'output': '飞机'},
{'input': '驾驶员', 'output': '汽车'},
{'input': '鸟', 'output': '鸟巢'},
{'input': '医生', 'output': '手术台'},
{'input': '苏轼','output':'北宋'},
{'input': '辛弃疾', 'output': '抗金'}
]
example_prompt = PromptTemplate(
input_variables=["input", "output"], template="输入: {input}\n输出:{output}")
# print(example_prompt)
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 可供选择的示例列表
examples,
# 用于生成用于测量语义相似性的嵌入的模型
OpenAIEmbeddings(),
# 用于存储嵌入和进行相似性搜索的vectorstores类
Chroma,
# 这次生成的示例次数
k=2
)
# print(example_selector)
similar_prompt = FewShotPromptTemplate(
# 有助于选择示例对象
example_selector=example_selector,
# 提示词
example_prompt=example_prompt,
# 添加提示词顶部和底部的自定义项
prefix = '根据下面示例,写出输出',
suffix='输入:{noun}\n输出:',
#提示词接收的输入
input_variables = ['noun'],
)
# print(similar_prompt)
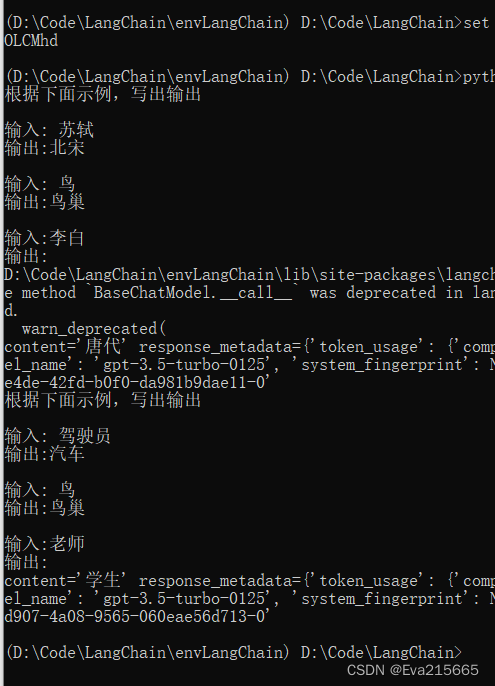
# 试一下,输入'李白'
final_prompt = similar_prompt.format(noun='李白')
print(final_prompt)
response = llm([HumanMessage(content=final_prompt)])
print(response)
# 再试一个,输入'老师'
final_prompt = similar_prompt.format(noun='老师')
response = llm([HumanMessage(content=final_prompt)])
print(final_prompt)
print(response)
测试了两个用例,用户输入李白,输出唐代,输入老师,输出学生
10. 用不同的相似度构造器实现Fewshot
用FewShotPromptTemplate构造提示词模板时,有一个重要的参数example_selector需要传入,example_selector可以用来衡量Fewshot时examples与llm已有知识之间相似度的一个工具。Langchain提供了3种衡量相似度的工具:Select by length,Select by maximal marginal relevance (MMR),Select by n-gram overlap
"""
Select by maxim marginal relevance (MMR)
https://python.langchain.com/v0.1/docs/modules/model_io/prompts/example_selectors/ngram_overlap/
"""
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import (
MaxMarginalRelevanceExampleSelector,
SemanticSimilarityExampleSelector
)
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
Chroma,
k=2
)
mmr_prompt = FewShotPromptTemplate(
example_selector = example_selector,
example_prompt = example_prompt,
prefix = "Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
print(mmr_prompt.format(adjective = "worried"))
"""
select by n-gram overlap
https://python.langchain.com/v0.1/docs/modules/model_io/prompts/example_selectors/ngram_overlap/
"""
"""
NGramOverlapExampleSelector根据 ngram 重叠分数,选择并排序与输入最相似的示例。ngram 重叠分数是介于 0.0 和 1.0 之间的浮点数(含)。
选择器允许设置阈值分数。 ngram 重叠分数小于或等于阈值的示例被排除。默认情况下,阈值设置为 -1.0,因此不会排除任何示例,
只会对它们重新排序。将阈值设置为 0.0 将排除与输入没有 ngram 重叠的示例。
"""
from langchain_community.example_selectors.ngram_overlap import (
NGramOverlapExampleSelector,
)
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# 用PromptTemplate构造器构造一个例子
PromptTemplate(
input_variables = ["input", "output"],
template = "输入:{input}\n输出{output}"
)
# Examples of a fictional translation task.
# 一个简单的翻译任务
examples = [
{"input": "See Spot run.", "output": "Ver correr a Spot."},
{"input": "My dog barks.", "output": "Mi perro ladra."},
{"input": "Spot can run.", "output": "Spot puede correr."},
]
NGramOverlapExampleSelector(
# 可选择的示例
examples=examples,
example_prompt=example_prompt,
# selector停止时的阈值,默认是-1.0
threshold = -1.0,
# For negative threshold:
# Selector sorts examples by ngram overlap score, and excludes none.
# For threshold greater than 1.0:
# Selector excludes all examples, and returns an empty list.
# For threshold equal to 0.0:
# Selector sorts examples by ngram overlap score,
# and excludes those with no ngram overlap with input.
)
dynamic_prompt = FewShotPromptTemplate(
# 提供exampleSelector而不是examples
example_selector = example_selector,
example_prompt = example_prompt,
prefix = "把输入翻译成西班牙语/法语",
suffix = "输入:{sentence}\n输出:",
input_variables = ["sentence"], # 输入参数叫做sentence
)
# 打印一下看构造是否成功
print(dynamic_prompt.format(sentence="I love you"))
# 可以给NGramOverlapExampleSelector新加examples
new_example = {"input": "Spot plays fetch.", "output": "Spot juega a buscar."}
example_selector.add_example(new_example)
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0.9)
final_prompt = dynamic_prompt.format(sentence="I love you")
message = HumanMessage(content=final_prompt)
print(llm([message]).content)


















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









