






为了深入讲解 Jetson AGX Orin 系列的技术规格,我会从每个模块的特点和应用入手,不仅解释它们的作用和参数,还会详细讨论在实际项目中如何应用、选型,以及可能的设计思路。
第一章:AI 性能——如何为智能设备选择最优计算能力
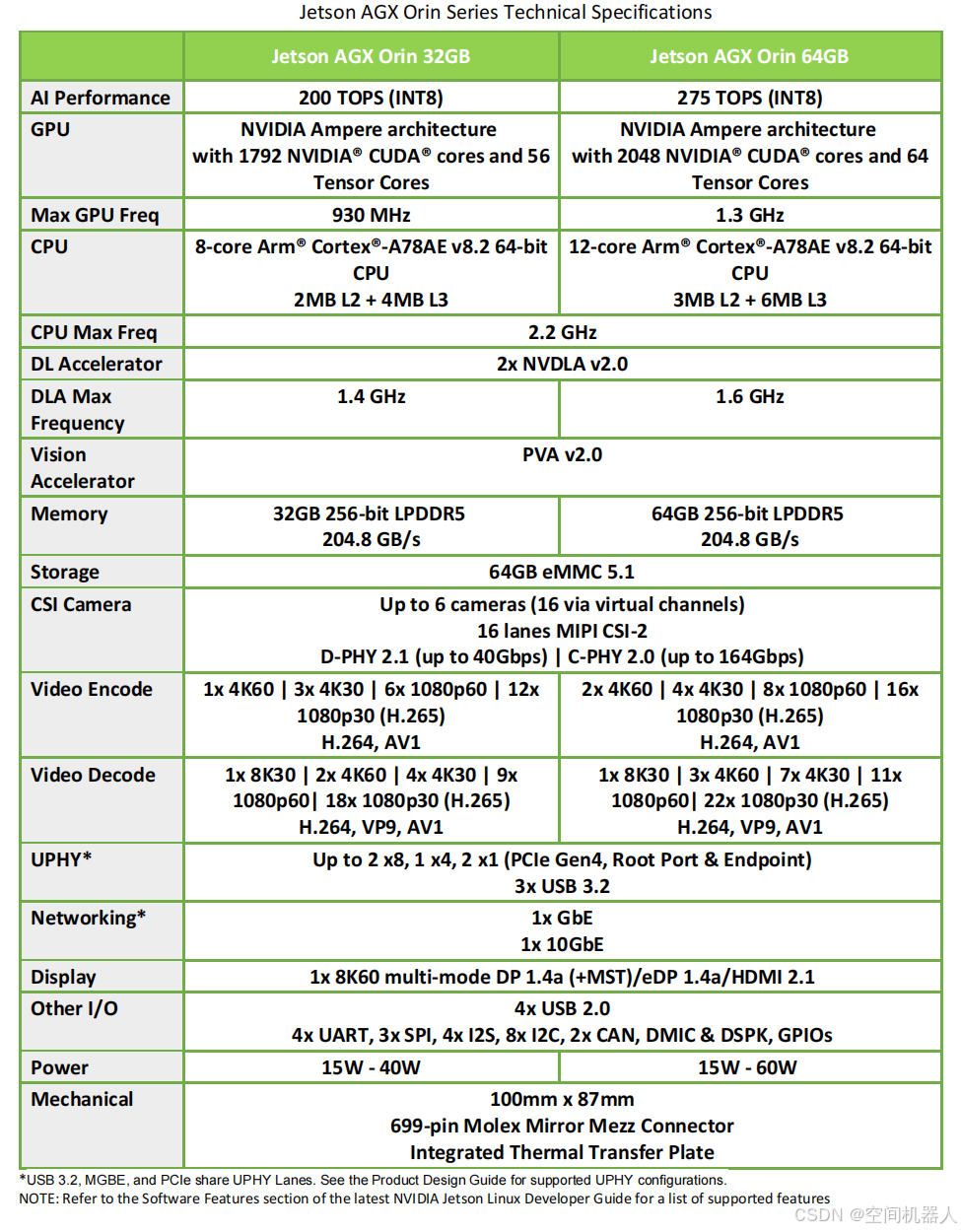
在 AI 性能方面,Jetson AGX Orin 提供了 200 TOPS(INT8)和 275 TOPS(INT8)两种配置。这里的 TOPS(Tera Operations Per Second)简单来说就是“每秒处理的计算量”。如果把设备比作一个工厂,那么 TOPS 就像是工厂的生产能力:数值越高,能处理的数据量越大、越快。
参数解析:
32GB 版本可以达到 200 TOPS,而 64GB 版本的峰值达到了 275 TOPS。假设我们在开发一个自动驾驶系统,AI 性能就决定了系统识别和处理周围环境的速度。在城市街道中,车辆、行人、红绿灯的信息瞬息万变,高 TOPS 能帮助车辆实时处理这些信息,避免延迟造成的安全风险。
选型建议:
如果你的项目是用于简单的图像分类,比如检测静态物体或只处理少量数据,32GB 版本的 200 TOPS 就足够了;但如果你需要更复杂的计算能力,比如实时处理多条车道上的动态物体、实时进行目标跟踪,那就要选择 64GB 版本的 275 TOPS,以保证系统足够流畅和安全。
应用案例:
在智能安防中,高 AI 性能可以支持多路视频流实时分析,及时发现异常行为。如果安装在银行或交通枢纽,每秒数百亿次的计算能力可以实时检测出异常行为,比如可疑人员的行踪、非法闯入,甚至是特定人脸的识别。这种高性能计算,可以让系统在毫秒内做出反应,极大地提升安全性。
第二章:GPU 架构——深度学习的核心加速器
Jetson AGX Orin 的 GPU 采用了 NVIDIA 的 Ampere 架构,内含大量 CUDA 核心和 Tensor 核心。可以把 GPU 看作一个工厂中的多条生产线,CUDA 核心负责一般计算,而 Tensor 核心就像流水线上的专用机器,特别擅长处理矩阵运算。
参数详解:
32GB 版本包含 1792 个 CUDA 核心和 56 个 Tensor 核心,而 64GB 版本则包含 2048 个 CUDA 核心和 64 个 Tensor 核心。这些核心的数量影响 GPU 的并行计算能力。如果 GPU 是一支团队,那每个核心就像团队的成员,人数越多,任务完成得越快。
实际应用:
比如,我们在做一个智能零售的项目,希望用摄像头监控商场内的顾客行为。这个应用需要大量计算来分析每一位顾客的活动,识别商品被拿取或放回的动作。拥有更多的 CUDA 和 Tensor 核心,可以在不影响流畅性的情况下,实时处理多路视频流并进行行为分析。
设计思路:
选择 64GB 版本的 GPU,会为高并发需求提供更强的支持。如果需要的是大量实时视频流分析的应用,64GB 的 2048 个 CUDA 核心无疑是更好的选择,可以让计算资源更加丰富。而如果只是简单的图像识别,可以考虑 32GB 版本,节省成本。
第三章:CPU 性能——核心数与频率的选择
Jetson AGX Orin 32GB 和 64GB 两个版本在 CPU 上也有所不同。32GB 版本采用了 8 核心的 Arm Cortex-A78AE CPU,而 64GB 版本则配备了更强大的 12 核心 CPU。核心数越多,设备的多任务处理能力越强。
参数解析:
32GB 版本的 CPU 最大频率为 2.2GHz,64GB 版本则更高。这意味着在处理复杂运算和同时运行多个程序时,64GB 版本的响应速度会更快。
应用场景:
例如,我们要做一个无人机控制系统,需要在实时接收数据、处理路径规划、避障等任务中来回切换。这种高频多核 CPU 就非常合适,可以让无人机在应对复杂环境时更加敏捷。
设计思路:
选择 64GB 版本的 12 核 CPU 可以确保设备在执行多任务时不会发生卡顿。如果只是单任务的应用,比如数据采集,8 核 CPU 可能已经足够,但多核和高频率总能为系统增加灵活性,使其在复杂情况下依旧流畅运行。
第四章:深度学习加速器(DL Accelerator)——专为 AI 任务设计的加速单元
在 Jetson AGX Orin 上,每个版本都配备了 2x NVDLA(NVIDIA Deep Learning Accelerator)v2 加速器。NVDLA 是专门为深度学习推理优化的硬件模块,像是一个专职的深度学习“工人”。
参数解析:
32GB 版本的 NVDLA 最大频率为 1.4GHz,而 64GB 版本提高到了 1.6GHz。这意味着在处理特定 AI 推理任务(如物体检测、语音识别)时,64GB 版本的速度更快。
应用案例:
假如我们在开发一个语音助手设备,NVDLA 的加速性能可以让设备快速响应用户语音指令。尤其在处理大规模语音数据或复杂的神经网络模型时,这种专用加速器比通用 CPU 更高效。
设计思路:
对于需要大量 AI 推理计算的场景,64GB 版本的 NVDLA 加速器更适合,可以保证设备在处理复杂的神经网络时有更好的性能表现。
第五章:存储和内存——数据处理的速度与容量
Jetson AGX Orin 32GB 配备了 32GB 的 LPDDR5 内存,而 64GB 版本配备 64GB LPDDR5 内存。更大的内存意味着可以存储和处理更多数据,也能支持更大规模的模型。
参数详解:
内存带宽达到了 204.8 GB/s,这是一个极高的数值,可以让系统在处理数据密集型任务时非常流畅。比如在自动驾驶中,车辆要实时处理来自多路摄像头、雷达和传感器的数据,大带宽可以确保不会发生数据瓶颈。
应用案例:
在医学图像分析中,通常需要处理高清CT扫描等数据,内存越大,可以一次性处理更多图像,也能加速整个计算流程。
选型建议:
对于一般应用,32GB 内存已经非常充足。但如果是需要大量数据缓存的场景,64GB 内存将带来更强的数据处理能力。
结论
在这几个模块的设计过程中,Jetson AGX Orin 系列提供了多种强大的选项。选择合适的配置取决于项目的具体需求和性能要求。


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











