







摘要
GPT使用传统的fine-tuning无法在自然语言理解(Natural Language Understanding, NLU)任务上取得良好的效果。本文提出了一种新方法P-tuning(采用了可学习的连续prompt embedding),可以使得GPT的性能优于同等规模的BERT。同时,我们发现P-tuning也提升了BERT在小样本以及监督学习环境下的性能并且极大程度上降低了对prompt工程的需要。
介绍
根据训练的目标,预训练语言模型主要可以被分为三类:针对语言生成任务的单向语言模型,如GPT;针对NLU的双向语言模型,如BERT以及将两种范式相结合的混合语言模型,如XLNet和UniLM。长久以来,研究人员发现GPT范式的模型在fine-tuning后在NLU上的效果还是很差,因此他们认为GPT不适合NLU任务。
GPT-3的出现以及它通过手工设计prompt,在小样本学习以及零次学习中取得的优秀表现,暗示着大型的单一语言模型加上合适的手工prompt有可能使得GPT可以胜任NLU任务。然后手工设计表现好prompt非常困难并且需要大量的验证数据集。在许多情况下,prompt工程的有效可能是在测试集上过拟合导致的。除此之外,也很容易构建一个对抗prompt来破坏其结果。考虑到这些问题,最近的工作主要集中在自动搜寻离散的prompt,并且证明它们的有效性。然后,由于神经网络本身就是连续的,离散的prompt可能只是次优结果。
在这篇文章中,我们提出了一种全新的方法P-tuning,可以在连续空间中自动搜索prompt,从而弥补GPT在NLU任务中不足。P-tuning使用少数连续的自由参数作为prompt,并且将其当做预训练语言模型的输入。然后通过梯度下降的方式来优化连续prompt,用这种方法来代替离散prompt。
简单的P-tuning就可以给GPT在NLU任务上的性能带来巨大的提升。进一步的实验也证明了P-tuning同样适用于BERT。
本文的主要贡献是:
1)通过P-tuning,我们发现GPT可以在NLU任务上取得和BERT差不多甚至更优的效果,这可以加点程度上提升预训练语言模型的性能。这也表明GPT类架构在NLU任务上的潜力被低估了。
2) P-tuning在小样本和监督训练环境下,对GPT和BERT都有用。通过P-tuning,我们的方法取得了SOTA的性能。
动机
GPT-3以及DALL-E的巨大成功似乎暗示了巨型模型是提高机器智能的灵丹妙药。然后在这背后,有着不可忽视的挑战。
一个重要的点在于大模型的迁移能力很差。在那些百亿规模的模型上进行fine-tuning很难有效果。作为另一种解决策略,GPT-3和DALL-E使用手工设计的prompt来引导模型向下流任务的迁移。然而,手工设计的prompt进行搜索时,严重依赖于超大的验证集,并且其性能也非常不稳定。下图展示了一个例子,一个词的变化可以造成巨大的结果差异

为了应对这些挑战,近期的工作主要集中在通过挖掘训练语料库来自动搜索离散prompt,梯度搜索以及使用多种模型上,我们将这个问题转化为寻找可以被微分优化的连续prompt问题。
P-tuning
在这一节中,我们主要展示了P-tuning的实现。和离散prompt类似,P-tuning只对输入采取非侵入式的修改。然而,P-tuning用微分输出embedding取代了预训练语言模型的输入embedding
结构
给定一个预训练语言模型 M \mathcal{M} M,通过 M \mathcal{M} M中的embedding层 e \textbf{e} e,一系列离散输入token x 1 : n = { x 0 , x 1 , . . . , x n } \textbf{x}_{1:n}=\{x_0, x_1, ..., x_n\} x1:n={x0,x1,...,xn}将被映射成输入embedding { e ( x 0 ) , e ( x 1 ) , e ( x n ) , } \{\textbf{e}(x_0), \textbf{e}(x_1), \textbf{e}(x_n),\} {e(x0),e(x1),e(xn),}。在针对 x \textbf{x} x的特定场景中,我们经常使用一组目标token y \textbf{y} y的输出embedding进行下游任务的处理。比如,在预训练中, x \textbf{x} x指未被遮挡的token, y y y指[MASK]的部分,在句子分类中, x \textbf{x} x指的是句子token, y \textbf{y} y指的是[CLS]。
prompt
p
\textbf{p}
p的作用是组织内容
x
\textbf{x}
x,目标
y
\textbf{y}
y以及它自身构成一个模板
T
T
T。举例说来,在一个预测一个国家的首都任务中,一个模板可能是“英国的首都是[MASK]”(如下图所示),在这里,“…的首都是”是prompt,“英国”是组织内容
x
\textbf{x}
x,“[MASK]”是目标。prompt非常灵活,我们甚至可以将它们插入到
x
\textbf{x}
x或者
y
\textbf{y}
y中。
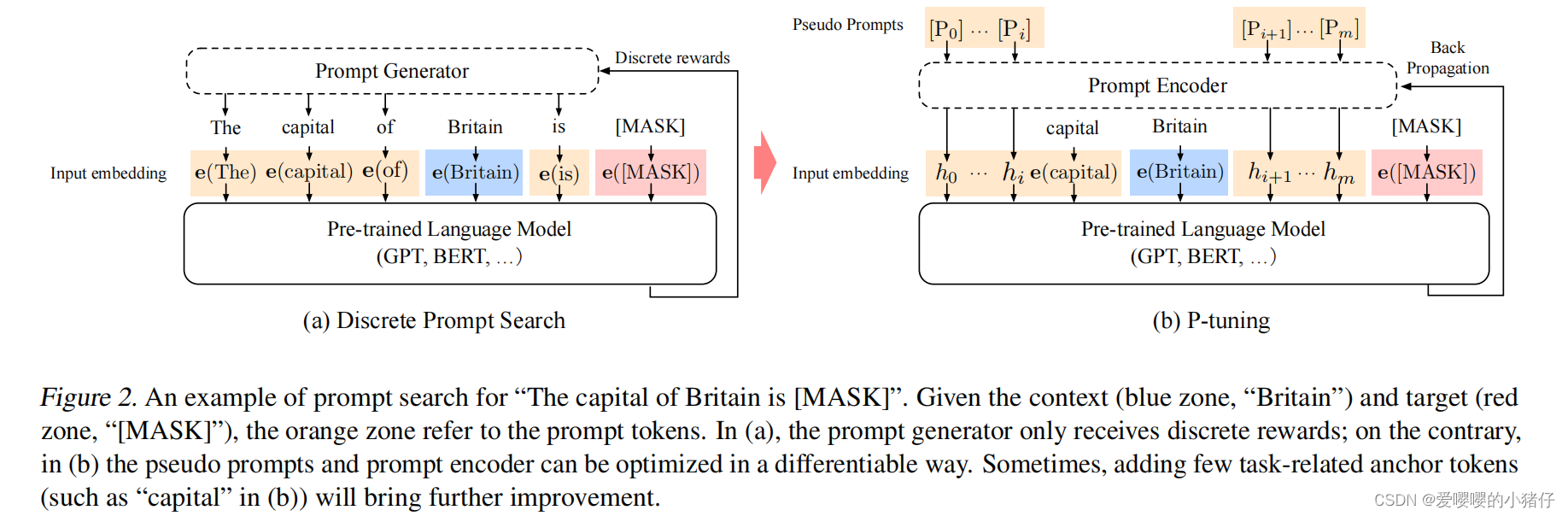
记语言模型
M
\mathcal{M}
M的词汇为
V
\mathcal{V}
V,[
P
i
P_i
Pi]代表模板
T
T
T中的第
i
i
i个prompt。给定一个模板
T
=
{
[
P
0
:
i
]
,
x
,
P
[
i
+
1
:
m
]
,
y
}
T=\{[P_{0:i}], \textbf{x},P[_{i+1:m}], \textbf{y}\}
T={[P0:i],x,P[i+1:m],y},离散的prompt需要
[
P
i
]
∈
V
[P_i]\in\mathcal{V}
[Pi]∈V,并且将
T
T
T映射到:
{
e
(
[
P
0
:
i
]
)
,
e
(
x
)
,
e
(
[
P
i
+
1
:
m
]
)
,
e
(
y
)
}
\{\textbf{e}([P_{0:i}]), \textbf{e}(x), \textbf{e}([P_{i+1:m}]), \textbf{e}(y)\}
{e([P0:i]),e(x),e([Pi+1:m]),e(y)}
相反的,P-tuning将
[
P
i
]
[P_i]
[Pi]当做假token并且将模板映射到
{
h
0
,
.
.
.
,
h
i
,
e
(
x
)
,
h
i
+
1
,
.
.
.
,
h
m
,
e
(
y
)
}
\{h_0,...,h_i, \textbf{e}(x), h_{i+1},...,h_m, \textbf{e}(y)\}
{h0,...,hi,e(x),hi+1,...,hm,e(y)}
这里
h
i
(
0
⩽
i
<
m
)
h_i(0\leqslant i <m)
hi(0⩽i<m)是可训练的embedding张量。这使得我们可以找到超越
M
\mathcal{M}
M和原始词汇表
V
\mathcal{V}
V表达能力的连续prompt。最终,通过下游的损失函数
L
\mathcal{L}
L,我们可以微分优化
h
i
h_i
hi:
h
^
0
:
m
=
a
r
g
m
i
n
h
L
(
M
(
x
,
y
)
)
\hat{h}_{0:m}=\underset{h}{argmin}\mathcal{L}(\mathcal{M(\textbf{x},\textbf{y})})
h^0:m=hargminL(M(x,y))
优化
尽管训练连续prompt的想法是很直接的,它面临两个优化的挑战
1)离散:
M
\mathcal{M}
M的原始单词embedding
e
e
e在经过预训练之后已经非常离散了。如果对
h
h
h使用随机分布初始化,然后使用随机梯度下降(SGD)进行优化,这样模型的参数只能在小邻域内变化,优化器很容易陷入局部最优
2)关联:我们相信prompt embedding
h
i
h_i
hi的值应该彼此关联而不是独立,我们需要某种机制建立prompt embedding之间的联系。
鉴于这些挑战,在P-tuning中,我们使用prompt编码器将
h
i
h_i
hi建模为一个序列,编码器由一个非常精简的神经网络构成,可以解决离散和关联的问题。在实践中,我们选择一个双向的LSTM,使用一个ReLU作为激活层的两层MLP来鼓励离散。从形式上说来,语言模型
M
\mathcal{M}
M的真实输入embedding
h
i
′
h_i'
hi′变为
h
i
′
=
M
L
P
(
[
h
i
→
:
h
i
←
]
)
=
M
L
P
(
[
L
S
T
M
(
h
0
:
i
)
:
L
S
T
M
(
h
i
:
m
)
]
)
h_i'=MLP([\mathop{h_i}\limits ^{\rightarrow}:\mathop{h_i}\limits ^{\leftarrow}])=MLP([LSTM(h_{0:i}):LSTM(h_{i:m})])
hi′=MLP([hi→:hi←])=MLP([LSTM(h0:i):LSTM(hi:m)])
虽然LSTM的使用确实给连续prompt的训练带来了额外的参数计算,LSTM比预训练模型的参数小了几个数量级。此外,在推理过程中,我么只需要输出embedding
h
h
h,所以可以丢掉LSTM。
除此之外,我们也发现在SuperGLue benchmark中,加入一些anchor token有助于NLU任务。
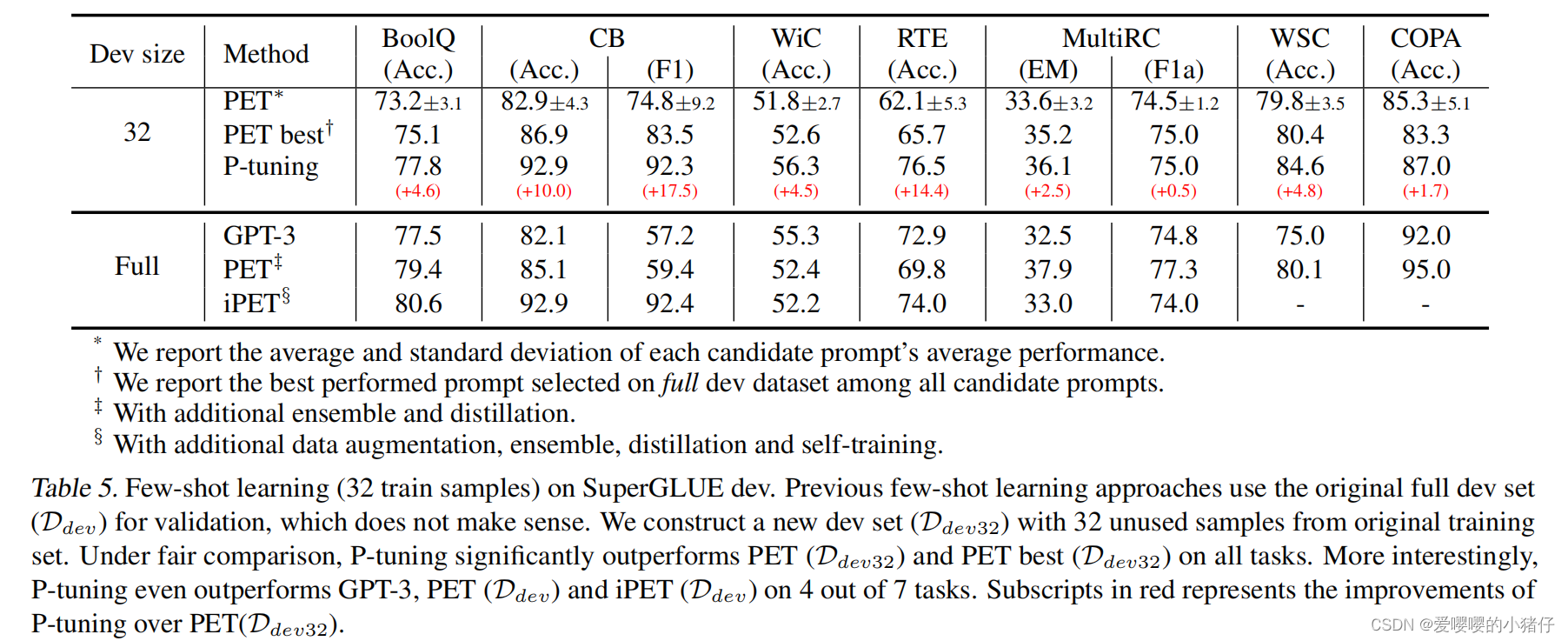
实验
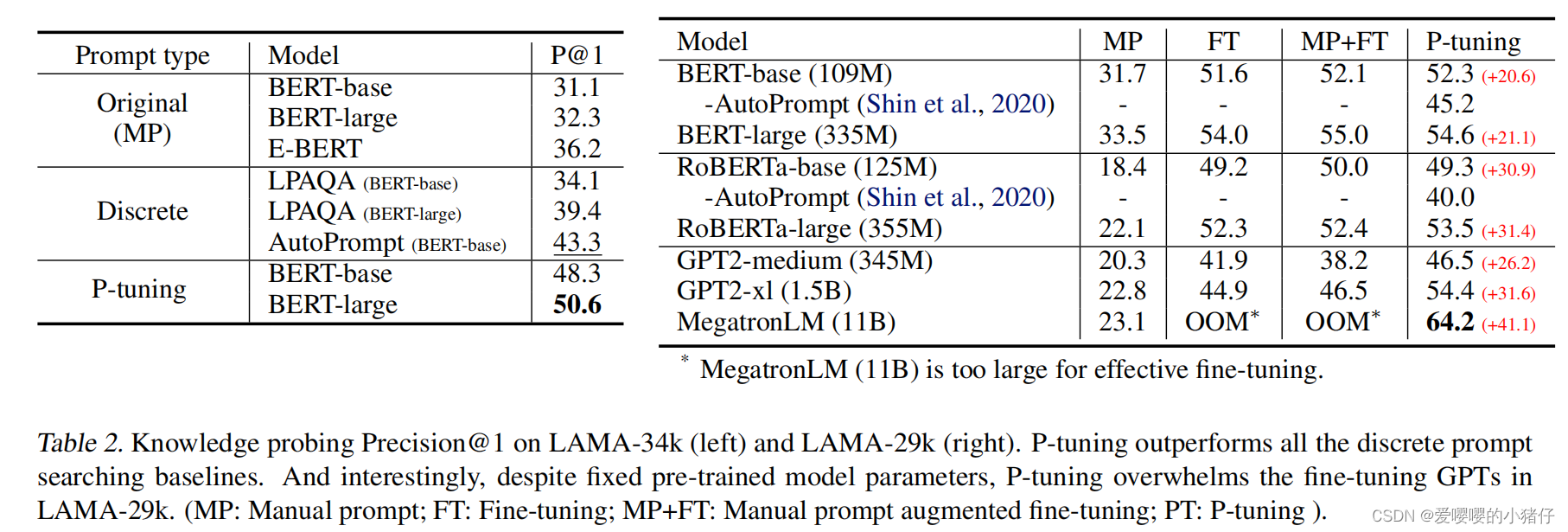
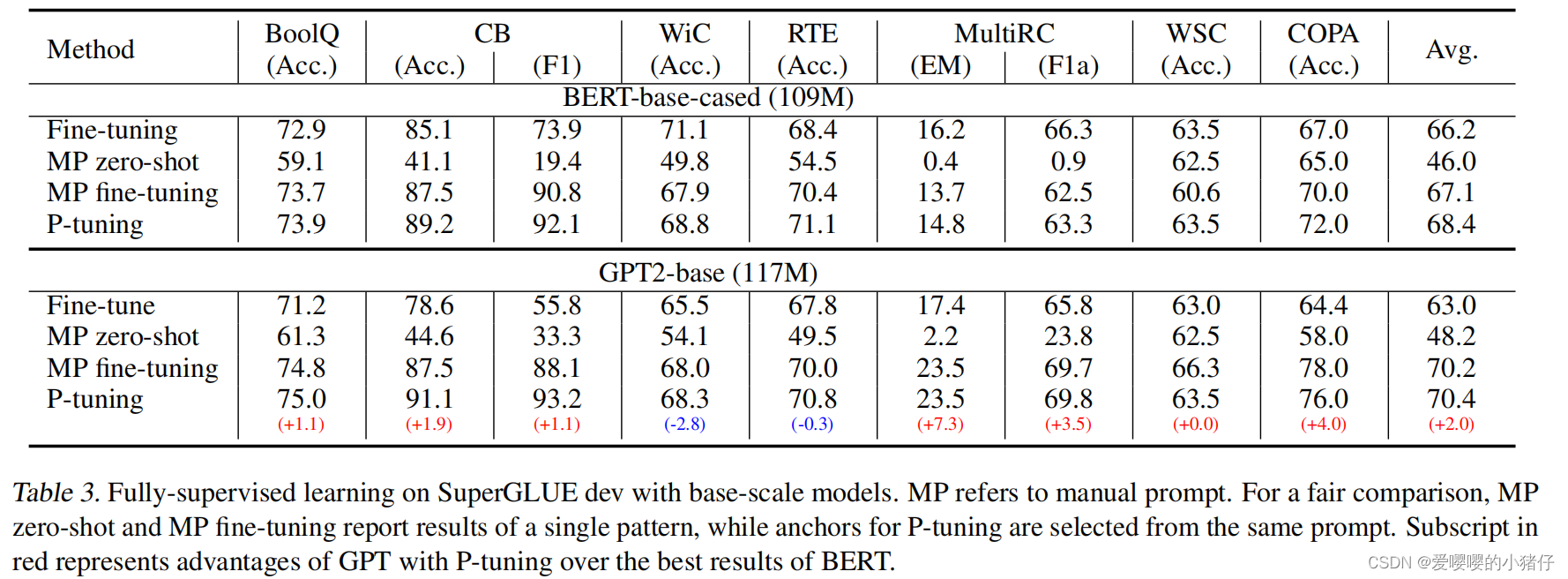
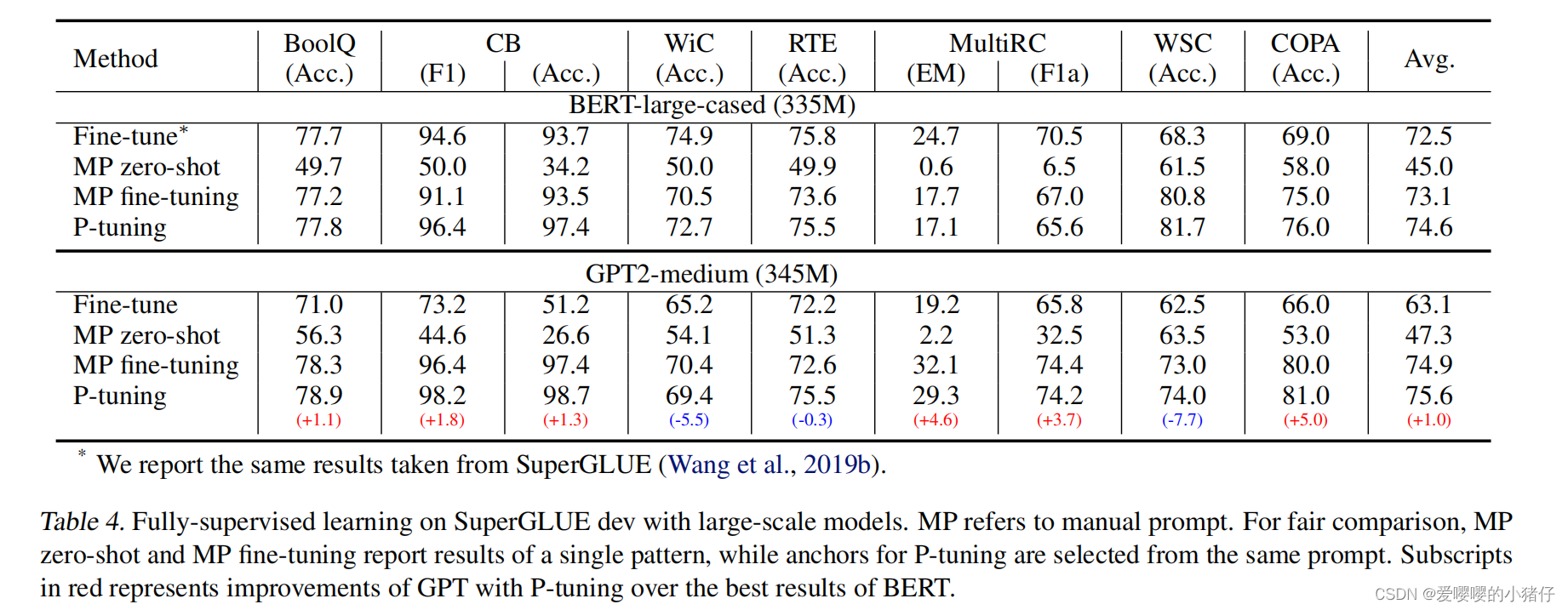















 5213
5213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









