









1.前言

深度神经网络的架构如上图,这里是一个网页版的在线绘图工具,是比较实用【传送门】
下面,文章将一步一步解密神秘的神经网络
2.数据
2.1 常见的神经网络数据集
2.1.1 MNIST手写数字数据集
下载网址:http://yann.lecun.com/exdb/mnist/index.html
2.1.2 CIFAR-10,CIFAR-100
【传送门】
以MNIST数据集为例,它是最常见的图像数据,有28*28=784个像素点组成。比如这样:

2.2 数据说明
用0表示全白,1表示全黑,其余值介于[0,1]之间。
- 第一层的数据输入:784维的向量
- 最后一层的输出:0-9的10个类别数据
- 隐藏层:暂定
3.目标
建议一个基于神经网络的分类模型,通过识别图片,判断数字是几。
假设我们建立的神经网络如下:

4.正向传播
正向传播,顾名思义就是从输入端计算到输出端。
下面我们手算神经网路
X
=
[
0.1
,
0.2
,
0.4
]
,
y
=
1
X=[0.1,0.2,0.4],y=1
X=[0.1,0.2,0.4],y=1

手算的正向传播。Z是输入激活与权重想成并相加的结果, 预测值y是Z与权重的积。通常要计算的任何输出,都需要激活与权重相乘。
y
p
r
e
d
i
c
t
=
x
1
∗
w
1
+
x
2
∗
w
2
+
x
3
∗
w
3
y_{predict} = x_1*w_1+x_2*w_2+x_3*w_3
ypredict=x1∗w1+x2∗w2+x3∗w3
5.BIAS偏置
偏置实际上是对神经元激活状态的控制。
y
p
r
e
d
i
c
t
=
Σ
i
=
1
n
x
i
∗
w
i
+
b
y_{predict}= \Sigma^{n}_{i=1}x_i*w_i+b
ypredict=Σi=1nxi∗wi+b
6.激活函数
6.1 常见的激活函数
6.1.1 Sigmoid函数
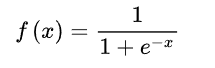

6.1.2 Tanh函数
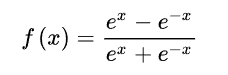
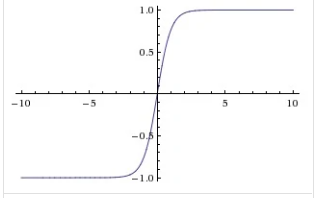
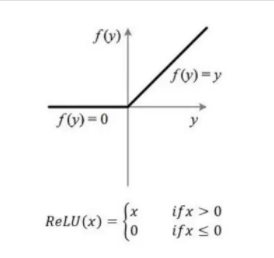
6.1.3 ReLU函数
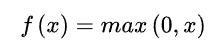
6.2 功能
加如激活函数,使得原来的线性组合模型,在非线性激活函数的作用下,可以逼近任何一个函数。
7.计算损失
损失就是真实值与预测值之间的误差,结合4.1计算的结果,我们计算误差为:
l
o
s
s
=
1
−
0.7
=
0.3
loss=1-0.7=0.3
loss=1−0.7=0.3
7.1 常见的误差形式
7.1.1 绝对误差
l
o
s
s
=
∣
y
t
r
u
e
−
y
p
r
e
d
i
c
t
∣
loss=|y_{true}-y_{predict}|
loss=∣ytrue−ypredict∣
不加绝对值,误差会因为有正有负而抵消一部分。
7.1.2 平均值误差
l
o
s
s
=
1
N
Σ
(
y
t
r
u
e
−
y
p
r
e
d
i
c
t
)
2
loss=\frac{1}{N} \Sigma(y_{true}-y_{predict})^{2}
loss=N1Σ(ytrue−ypredict)2
加平方的原因也如此。
8.反向传播
正向传播反着算!!!
因为我们虽然无法改变输入,但是我们可以调整权重。反向传播的目的,就是通过改变权重值,从而使得获得更小的误差,逐渐的趋近真实值。
9.梯度下降
就是求导,求最小值。
这里的最小值,就是使得损失最小。梯度下降的解释,请参照我以前的博客,不做过多的介绍和解释。
10.学习率
古有俗语:还没学会趴,你就要假装飞!
神经网络的学习率也是如此,当我们的模型开始进行迭代的时候,在确切的说是在梯度下降的时候,每一次迭代【增加、减少】多少的权重????
学习率过快过慢都会对模型产生影响。
11.权重调整
w e i g h t n e w = w e i g h t o l d − η ∗ ∇ l ∇ w e i g h t o l d weight_{new}=weight_{old}-\eta* \frac{\nabla l}{\nabla weight_{old}} weightnew=weightold−η∗∇weightold∇l
12.DROP OUT
为了便面模型的过拟合,使用drop out 层。一句话讲:每次计算不比全部运用这些神经元,随机的选取神经元来迭代计算,从而解决模型的过拟合!!
















 1122
1122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











