







 本文介绍了OCR文本扫描项目实战,通过opencv-python进行图像预处理,包括轮廓检测、透视变换,结合pytesseract进行文本识别。文章详细讲解了图像处理的每一步骤,包括图像resize、Canny边缘检测、轮廓检测、透视变换,以及最终的文本识别。
本文介绍了OCR文本扫描项目实战,通过opencv-python进行图像预处理,包括轮廓检测、透视变换,结合pytesseract进行文本识别。文章详细讲解了图像处理的每一步骤,包括图像resize、Canny边缘检测、轮廓检测、透视变换,以及最终的文本识别。
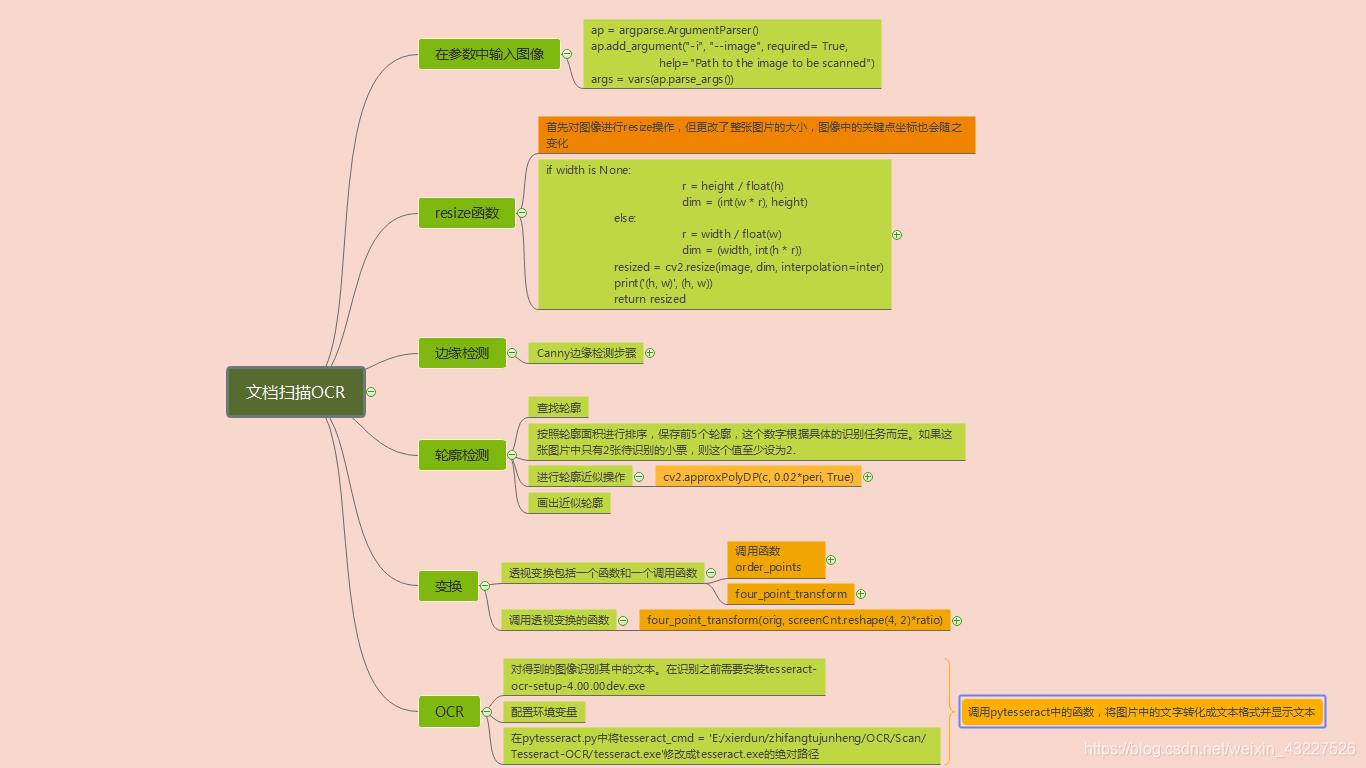
OCR文本扫描项目实战(图像预处理,调用pytesseract.image_to_string()完成文本识别)
本项目和源代码来自唐宇迪opencv项目实战
本文是一篇OCR文本扫描项目实战的学习笔记。在opencv-python环境下对图像进行轮廓检测、透视变换等处理。调用pytesseract模块实现文本扫描。
恳请批评指正
OCR文本识别
什么是OCR,百度里的定义是:
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
简单说来,打印在纸上的“hello word”,将它以一张图片的形式输入到计算机中,计算机经过一系列的处理,识别出“hello word”,转化成了可以复制的文本格式就更好啦O(∩_∩)O。
OCR应用方面广泛,常见的比如翻译软件中的拍照翻译。
项目概述
本项目分为两部分:
1 对输入图像进行一系列预处理
2 对处理后的图像进行文本扫描并输出识别的结果
实现的流程图如图所示:
输入一张包含文字信息的的图片
处理后的结果如图所示:

进行OCR文本识别的输出结果为:

文末附代码
算法步骤
1 设置参数
在参数中输入图片的相对路径,将图片传入。
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required= True,
help="Path to the image to be scanned")
args = vars(ap.parse_args())
参数修改为图片的相对路径:
–image images/hello.jpg
2 图片预处理操作
resize 操作
resize函数的作用是按照原图像相同长宽比,当给定长(height)或者宽(width)时将原图resize成与原图像同比例的大小。
至于这一步为什么要进行resize操作,我分析有两点原因。
1 实验使用的图像多为手机拍摄的图片,图片大小至少为3500*4000,在imshow(),在屏幕显示并不能像是完整的图像,不利于观察。
2 用原图直接调用pytesseract image_to_string时可能返回值为空(我没明白)
该函数的返回值是resize后的图片;参数是原图像和指定的变换后的width或height值。
接着对图像进一步操作
Canny边缘检测步骤
参考一篇写canny边缘检测的博客
1.使用高斯滤波器以平滑图像滤除噪声
2.计算图像中每个像素点的强度和方向
3.应用非极大值抑制(Non-maximum suppression,NMS)来消除边缘检测带来的杂散响应。
4.应用双阈值检测(Double-Threshold)来确定真实的和潜在的边缘
5.通过抑制孤立的弱边缘最终完成边缘检测。
Canny边缘检测之前需要先降噪----高斯滤波
GaussianBlur(src,ksize,sigmaX [,dst [,sigmaY [,borderType]]])-> dst
第一个参数是输入图像,可以是Mat类型,图像深度为CV_8U、CV_16U、CV_16S、CV_32F、CV_64F。
第二个参数是输出图像,与输入图像有相同的类型和尺寸。
Size ksize: 高斯内核大小,这个尺寸与前面两个滤波kernel尺寸不同,ksize.width和ksize.height可以不相同但是这两个值必须为正奇数,如果这两个值为0,他们的值将由sigma计算。
double sigmaX: 高斯核函数在X方向上的标准偏差
double sigmaY: 高斯核函数在Y方向上的标准偏差,如果sigmaY是0,则函数会自动将sigmaY的值设置为与sigmaX相同的值,如果sigmaX和sigmaY都是0,这两个值将由ksize.width和ksize.height计算而来。
Canny边缘检测函数
canny = cv2.Canny(gauss, 75, 200)
第一个参数时输入的图像,第二个参数是MinVal,第三个参数是MaxVal。
如果该点的梯度大于MaxVal, 则将该点处理为边界。如果该点的梯度大于MinVal且小于MaxVal,则抗癌电视都与边界相连,如果相连则将该点处理为边界,否则不是边界。如果该点小于MinVal则该点不是边界。
轮廓检测
查找轮廓,轮廓检测使用的模型是RETR_LIST,检测所有轮廓, 并将其保存在一条链表中
cv2.findContours(img, mode, methord)
下表列出了轮廓检测的模型mode
| MODE | 注释 |
|---|---|
| RETR_EXTERNAL | 只检测最外面的轮廓 |
| RETR_LIST | 检索所有轮廓,并将其保存到一条链表中 |
| RETR_CCOMP | 检索所有轮廓,并将他们组织为两层 ,顶层是各部分的外界边界,第二层是空洞的边界 |
| RETR_TREE | 检测所有轮廓,并重构嵌套轮廓的整个层次 |
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
检测到所有轮廓后根据轮廓面积大小对轮廓进行排序,并保留前五个,画出这按照面积排序的前五个轮廓(在绘制轮廓之前别忘了复制原图像,否则显示原图形也会被更改。)
轮廓近似
定义一个循环,遍历轮廓,完成轮廓近似的操作。
peri = cv2.arcLength(c, True)
先计算出轮廓的周长,然后以轮廓周长乘以一个百分比作为轮廓近似的精度。
approx = cv2.approxPolyDP(c, 0.02*peri, True)
True表示轮廓是封闭的
而轮廓近似的返回值是能够包含图像的点的集合。既然是逐个点确定,又包含了整个图像,那一定是从最大的轮廓开始。当返回值的长度为4,即返回点的个数为4时,说明确定的就是能将最外面的最大轮廓包围的四边形的四个顶点。显示图像如图所示:

透视变换
透视变换(Perspective Transformation)是将成像投影到一个新的视平面(Viewing Plane)
自定义函数 order_points()
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
程序中定义了两个函数,order_point函数用一种方法来分辨这四个定位点分别对应于四边形的那个顶点,简单说就是给四个点起名字。
左下(bl), 右下(br), 右上(tr), 左上(tl),并将四个点按顺势者或逆时针依次存放。从那个点开始存放不重要,关键是要通过这四个点的坐标关系确定每一个点分别对应(四边形)的哪一个顶点。简单说来就是给每一个点起了一个代号,方便使用它,后面有用。
第二个函数 four_point_transform(image, pts)进行透视变换了。首先调用函数order_point,使用这四个起好名字的点。根据几个关系利用公式 s = ((x2-x1)2 +(y2-y1)2 )1/2 。因为四个点确定的近似轮廓不一定是矩形,所以分别取长和宽最大长度,
自定义函数 def four_point_transform()
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









