









微调BERT
自然语言推断任务设计了一个基于注意力的结构。现在,我们通过微调BERT来重新审视这项任务。自然语言推断是一个序列级别的文本对分类问题,而微调BERT只需要一个额外的基于多层感知机的架构,如下图中所示。
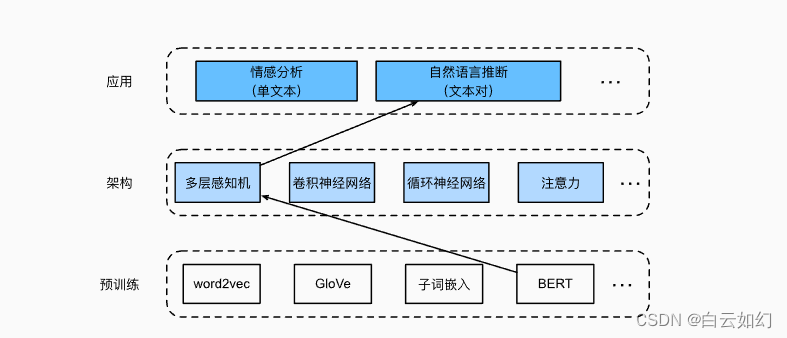
本节将下载一个预训练好的小版本的BERT,然后对其进行微调,以便在SNLI数据集上进行自然语言推断。
import json
import multiprocessing
import os
from mxnet import gluon, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()加载预训练的BERT
原始的BERT模型有数以亿计的参数。在下面,我们提供了两个版本的预训练的BERT:“bert.base”与原始的BERT基础模型一样大,需要大量的计算资源才能进行微调,而“bert.small”是一个小版本,以便于演示。
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')两个预训练好的BERT模型都包含一个定义词表的“vocab.json”文件和一个预训练参数的“pretrained.params”文件。我们实现了以下load_pretrained_model函数来加载预先训练好的BERT参数。
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, max_len, devices):
data_dir = d2l.download_extract(pretrained_model)
# 定义空词表以加载预定义词表
vocab = d2l.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir,
'vocab.json')))
vocab.token_to_idx = {token: idx for idx, token in enumerate(
vocab.idx_to_token)}
bert = d2l.BERTModel(len(vocab), num_hiddens, norm_shape=[256],
ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens,
num_heads=4, num_layers=2, dropout=0.2,
max_len=max_len, key_size=256, query_size=256,
value_size=256, hid_in_features=256,
mlm_in_features=256, nsp_in_features=256)
# 加载预训练BERT参数
bert.load_state_dict(torch.load(os.path.join(data_dir,
'pretrained.params')))
return bert, vocab为了便于在大多数机器上演示,我们将在本节中加载和微调经过预训练BERT的小版本(“bert.small”)。在练习中,我们将展示如何微调大得多的“bert.base”以显著提高测试精度。
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
'bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_layers=2, dropout=0.1, max_len=512, devices=devices)
















 1674
1674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











