







1. 介绍
在计算机并行计算领域,并行计算模型常分为以下四种情况:
- 单指令单数据 (SISD)
- 单指令多数据 (SIMD)
- 多指令单数据 (MISD)
- 多指令多数据 (MIMD)
在GPU shader编程中,处理器会自动把shader转换为并行执行,如Pixel shader, 只需对一个像素点处理,GPU会对所有的像素做相同处理,这是一种隐式的SIMD,用户是无法控制的,在最新的DX12/Vulkan 图形API中,都加强了用户层代码对底层功能的控制能力,HLSL SM6.0 提供了一系列Wave操作,Vulkan也提供了类型概念Invacation , 详见文献[3,4], 这类接口使用户层编写一些并行程序更加容易,如FFT(快速傅里叶变换),并行快排算法,但想要高效的使用这些接口,需要理解GPU如何执行的.
假设我们的芯片是一个SIMD32的架构,下图中每一个小方块代表一个lane, 上面有不同的数据,
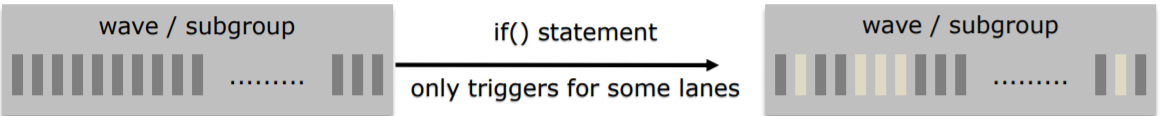
在芯片上运行下面这段代码
instruction 1;
----------
if (condition)
{
color = vec4(1.0,1.0,1.0,0.0); // a
}
else {
if (condition2)
color = vec4(1.0,1.0,1.0,0.0); // b
else
color = vec4(1.0,1.0,1.0,0.0); // c
}
----------
instruction 2;
上面的代码片段分为三个部分:if-else 语句前一条,if-else, if-else语句前后一条. SIMD 上不同的数据会根据条件是否满足,相应执行a,b,c 路径,而GPU SIMD 是lockstep的执行模式,即虽然 a 路径的 线程执行结束后直接到达 instruction 2前, 但是它们不会继续往下执行,必须等待b,c路径的线程也执行到instruction 2前,所有的线程才能继续执行下去。如果代码中有很多的嵌套if-else, 先执行完的线程会等待很多时钟周期等待其他线程,如果SIMD 出现了这种情况,会对GPU 性能有很大的浪费。divergence 也就是指这种情况,SIMD遇到了if-else 分支,线程出现了分叉的情况。
对于Divergence的分析与优化,用户层代码不需要考虑,主要是通过Compiler的来优化,从参考文献1已经提出解决方案。在此,先提前提出几个问题帮助理解这个Pass:
- 如何用静态分析技术,判断某种指令在该条件分支是否会造成divergence? 反之,该指令会让线程汇聚(Uniform)
- 学术答案:根据论文1 和论文2 可知,
THEOREM 3.1. A variable v ∈ P is divergent if, and only if, one of these conditions hold:
1. v = tid.
2. v is defined by the atomic increment, e.g: atomic(v, vx).
3. v is data dependent on some divergent variable.
4. v is sync dependent on some divergent variable.
- 工业界答案:根据AMD源码可知
1. 传参,看寄存器类型
2. Load 指令,具体看地址空间
3. atomic 指令
4. intrinsic指令 :AMDGPUSearchableTables.td
5. 排除部分InlineAsm 的所有call指令
6. InvokeInst 指令
bool GCNTTIImpl::isSourceOfDivergence(const Value *V) const {
if (const Argument *A = dyn_cast<Argument>(V))
return !isArgPassedInSGPR(A);
if (const LoadInst *Load = dyn_cast<LoadInst>(V))
return Load->getPointerAddressSpace() == AMDGPUAS::PRIVATE_ADDRESS ||
Load->getPointerAddressSpace() == AMDGPUAS::FLAT_ADDRESS;
if (isa<AtomicRMWInst>(V) || isa<AtomicCmpXchgInst>(V))
return true;
if (const IntrinsicInst *Intrinsic = dyn_cast<IntrinsicInst>(V))
return AMDGPU::isIntrinsicSourceOfDivergence(Intrinsic->getIntrinsicID());
if (const CallInst *CI = dyn_cast<CallInst>(V)) {
if (CI->isInlineAsm())
return isInlineAsmSourceOfDivergence(CI);
return true;
}
if (isa<InvokeInst>(V))
return true;
return false;
}
2. Divergence 算法伪码
GPUDivergenceAnalysis()
{
// S1: Collect some Known info from hardware view.
DenseSet<const Value *> DivergentValues;
DenseSet<const Value *> UniformOverrides;
for (auto &I : instructions(F)) {
if (isSourceOfDivergence(I))
DivergentValues.insert(I);
else if(isAlwaysUniform(I))
UniformOverrides.insert(I);
}
// S2. Deduce unknown information
}
5. 参考文献
- https://homepages.dcc.ufmg.br/~fernando/publications/papers/divergence.pdf
- https://hal.inria.fr/hal-00909072/document
- https://www.cs.cornell.edu/courses/cs6120/2019fa/blog/divergence-optimizations/
- https://docs.microsoft.com/en-us/windows/win32/direct3dhlsl/hlsl-shader-model-6-0-features-for-direct3d-12#shading-language-intrinsics
- https://gpuopen.com/wp-content/uploads/2017/07/GDC2017-Wave-Programming-D3D12-Vulkan.pdf














 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









