







百度百科定义:统计学是通过搜索、整理、分析、描述数据等手段,以达到推断所测对象的本质,甚至预测对象未来的一门综合性科学。其实在个人看来,统计学发展至今最主要有2个功能:1.分析过去,2.预测未来。
1.样本和总体
- 总体(population)就是研究对象的全部.
- 样本(sample)是从总体中选出来的一部分. 总体相当于讨论问题的基础集.而样本则 是总体的一个子集,样本所包括的元素个数称为样本容量.从总体中选择样本的方法有很多种,比如随机抽样、典型抽样等等,选择样本的出发点是要保证样本具有代表性.
- 参数(parameter)是用来描述总体特征的量.
- 统计量(statistic)是指从样本计算而来的主要用于推断总体参数的量.
- 均值、中位数、众数是用来描述数据的集中趋势的测度. 总体均值用
μ
\mu
μ 表示,样本均值用
x
ˉ
\bar{x}
xˉ表示.
视频中提到的:样本数据收集越多,越具有代表性。样本取样方法比较关键,一般为随机抽样,可消除偏性。
2.总体方差何样本方差(重点)
首先,我们来看一下样本方差的计算公式:
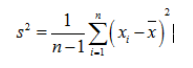
刚开始接触这个公式的话可能会有一个疑问就是:为什么样本方差要除以(n-1)而不是除以n?为了解决这个疑惑,我们需要具备一点统计学的知识基础,关于总体、样本、期望(均值)、方差的定义以及统计估计量的评选标准。有了这些知识基础之后,我们会知道样本方差之所以要除以(n-1)是因为这样的方差估计量才是关于总体方差的无偏估计量。这个公式是通过修正下面的方差计算公式而来的:
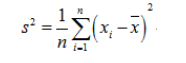
修正过程为:
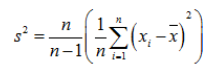
我们看到的其实是修正后的结果:
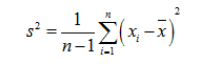
为了方便叙述,在这里说明好数学符号:

前面说过样本方差之所以要除以(n-1)是因为这样的方差估计量才是关于总体方差的无偏估计量。在公式上来讲的话就是样本方差的估计量的期望要等于总体方差。如下:
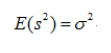
但是没有修正的方差公式,它的期望是不等于总体方差的
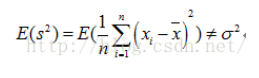
也就是说,样本方差估计量如果是用没有修正的方差公式来估计总计方差的话是有偏差的
下面给出比较好理解的公式推导过程:

需要注意的是不等式右边的才是的对方差的“正确”估计,但是我们是不知道真正的总体均值是多少的,只能通过样本的均值来代替总体的均值。所以样本方差估计量如果是用没有修正的方差公式来估计总计方差的话是会有偏差,是会低估了总体的样本方差的。为了能无偏差的估计总体方差,所以要对方差计算公式进行修正,修正公式如下:
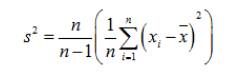
这种修正后的估计量将是总体方差的无偏估计量,下面将会给出这种修正的一个来源;
为了能搞懂这种修正是怎么来的,首先我们得有下面几个等式:
1.方差计算公式:
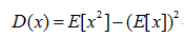
2. 均值的均值、方差计算公式:
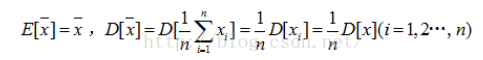
对于没有修正的方差计算公式我们有:

因为:
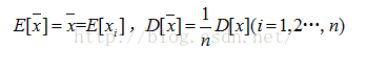
所以有: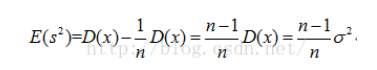
在这里如果想修正的方差公式,让修正后的方差公式求出的方差的期望为总体方差的话就需要在没有修正的方差公式前面加上来进行修正,即:
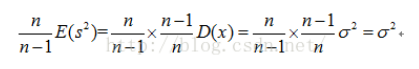
所以就会有这样的修正公式:
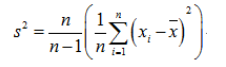
而我们看到的都是修正后的最终结果:
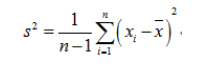
这就解释了为什么要对方差计算公式进行修正,且为什么要这样修正。
3.两点分布、二项分布、伯努利试验、0,1分布
说起二项分布(binomial distribution),不得不提的前提是伯努利试验(Bernoulli experiment),也即n次独立重复试验。伯努利试验是在同样的条件下重复、相互独立进行的一种随机试验。
伯努利试验的特点是:
(1)每次试验中事件只有两种结果:事件发生或者不发生,如硬币正面或反面,患病或没患病;
(2)每次试验中事件发生的概率是相同的,注意不一定是0.5;
(3)n次试验的事件相互之间独立。
n次试验中恰好出现k次的概率为
P(X=k) = C(n,k) * pk*(1-p)n-k
这就是二项分布的分布律,记作X~B(n,p),其中C(n,k)是组合数,在数学中也叫二项式系数,这就是二项分布名称的来历。
判断某个随机变量X是否符合二项分布除了满足上述的伯努利试验外,关键是这个X是否表示事件发生的次数。二项分布的数学期望E(X)=np,方差D(X)=np*(1-p)。
在实际应用中还有伯努利分布、两点分布、0-1分布等,它们与二项分布之间有什么关系呢?
X~B(n,p),当n = 1时,二项分布就变成了伯努利分布(Bernoulli distribution),伯努利分布又称为“两点分布”或“0-1分布”,或者说伯努利分布/两点分布/0-1分布是二项分布在n=1时的特例,即伯努利分布、两点分布、0-1分布这三种分布是同一个分布的不同名称,又都是二项分布在n=1时的特例。
4.大数定理
*概率书中数学语言的描述
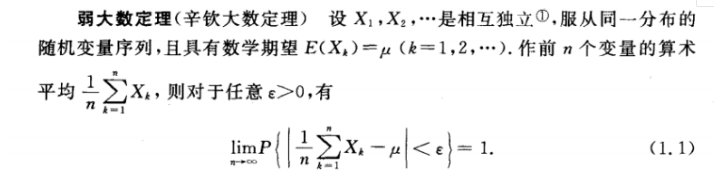
弱大数定理用一句话表述就是n很大时它们的算术平均值很接近期望值。(当然前提随机变量??是独立同分布,期望值最一样,它们指 ??,?=0,1,…。)
弱大数定理是抽样统计的理论基础,例如估算全国人口的平均身高,一般通过做多个抽样,分另计算其均值,再对其均值求平均数,作为所有样本的平均身高。参照样品标准差。
上面定理特别说明了随机变量服从同一分布,实际上即使X1,X2,…Xk不服从同一分布结论也成立,这被称为切比雪夫大数定理,再看看切比雪夫不等式
不知道随机变量的具体概率密度函数,但知道它总体的均值和方差时,可用切比雪夫不等式来估算一定条件下的概率。
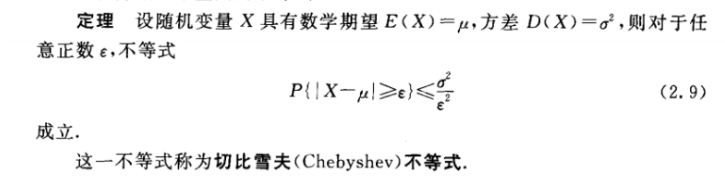
**伯努利大数定理

伯努利大数定理是日常中最常被使用的,它的直观表达就是只要做的试验够多,出现的次数除以总次数的结果接近统计概率p,这也是频率到概率概念演变的理论基础
举个例子,结合概率论里面的概念。
”抛5次硬币“是一种试验,一共作n重,
“ 3次出现正面”,称为事件A,n重试验出现A的次数为fA
另外已知"抛5次3次正面"的概率是p,这是一个先验可统计概率。
如果n很大,则出现A的次数除以n就可做为统计的概率p
5.中心极限定理
中心极限定理通俗介绍
中心极限定理是统计学中比较重要的一个定理。 本文将通过实际模拟数据的形式,形象地展示中心极限定理是什么,是如何发挥作用的。
什么是中心极限定理(Central Limit Theorem)
中心极限定理指的是给定一个任意分布的总体。我每次从这些总体中随机抽取 n 个抽样,一共抽 m 次。 然后把这 m 组抽样分别求出平均值。 这些平均值的分布接近正态分布。
我们先举个栗子
现在我们要统计全国的人的体重,看看我国平均体重是多少。当然,我们把全国所有人的体重都调查一遍是不现实的。所以我们打算一共调查1000组,每组50个人。 然后,我们求出第一组的体重平均值、第二组的体重平均值,一直到最后一组的体重平均值。中心极限定理说:这些平均值是呈现正态分布的。并且,随着组数的增加,效果会越好。 最后,当我们再把1000组算出来的平均值加起来取个平均值,这个平均值会接近全国平均体重。
其中要注意的几点:
1.总体本身的分布不要求正态分布
上面的例子中,人的体重是正态分布的。但如果我们的例子是掷一个骰子(平均分布),最后每组的平均值也会组成一个正态分布。(神奇!)
2.样本每组要足够大,但也不需要太大
取样本的时候,一般认为,每组大于等于30个,即可让中心极限定理发挥作用。
6.正态分布
















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









