







很多初学者在学到字节输入流时都有一个疑惑,当使用字节输入流(FileInputStream)读取数字字母时会正常读取,而读取中文数据时会出现中文乱码的情况,是不是读取中文数据非得使用字符输入流来读取呢?其实字节输入流一样是可以读取中文数据的。
看你使用的是什么开发工具,idea的话是默认使用utf-8编码的,使用eclipse的小伙伴需要手动改成utf-8,具体怎么改这里不介绍了。
首先应该明确两点:utf-8编码1个中文占3个字节,gbk编码1个中文占2个字节
所以当我们读取中文数据采用的是一次读取一个字节的方式,始终会报错,假如你的开发工具改的是gbk编码,那么每次读取到该中文字符的1/2个字节,utf-8的话每次读取到的是1/3个字节,所以读取中文数据不能采用该方式读取。只能使用每次读取一个字节数组的方式来读取
当我们使用记事本中存储汉字时默认是ANSI编码,其实就是GBK编码。如果开发工具已经改为了utf-8,读取中文数据要想不乱码,可以使用String类的一个构造方法
String(byte[] bytes, int offset, int length, Charset charset)
将charset改为gbk即可,下面看具体代码
import java.io.FileInputStream;
import java.io.IOException;
public class FileInputStreamDemo06 {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("C:\\iotest\\a.txt");
int len;
byte[] bytes = new byte[7];
while ((len = fis.read(bytes)) != -1) {
System.out.print(new String(bytes, 0, len, "gbk"));
}
fis.close();
}
}
因为gbk编码一个中文字符占用两个字节,所以这里定义一个长度为2的字节数组,当然也可以是2的整数倍

运行结果
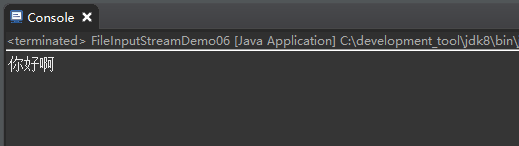
要想不出现乱码还可以将记事本的编码改为utf-8,改编码的方式可以将刚才的文件另存,具体步骤如下

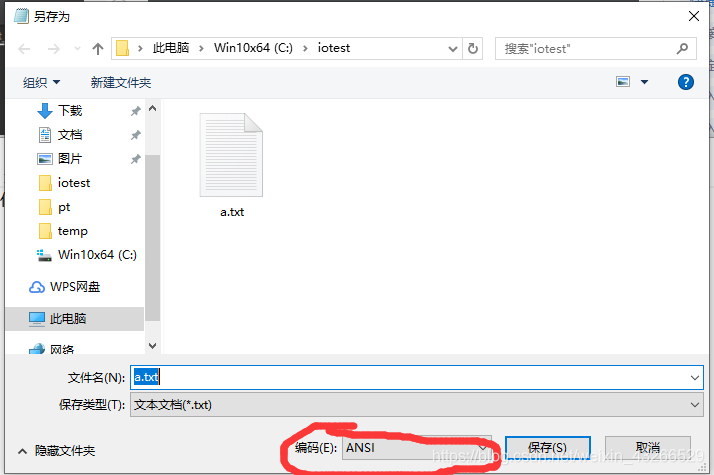
这里就可以使用String类的另外一个构造方法
String(byte[] bytes, int offset, int length)
因为记事本改为了utf-8就和开发工具的编码想同了,但是这里定义数组的时候需要定义为长度为3。
总结:以上的做法其实意义不大,读取中文数据的时候我们最好还是使用字符输入流进行读取















 3136
3136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









