







目前准备详读以下文章
2020年文章,较为新,同时文章比较全面,内容分类较清楚
Evolution of Image Segmentation using Deep Convolutional NeuralNetwork: A Survey
一:分割分类


如上图所示分割可以分为三类
1) 语义分割:像素级分类,同类物体之间没有分别。
2)实例分割:检测每个 object instance,并进行分割,同类物体之间有分别。
3)全景分割:上面二者的结合。既需要分割出全部像素,同类像素不同物体间不能有重合。图片内的每个像素都必须分配 semantic label 和 instance id. 如 Figure 1d. 相同 label 和相同 id 的像素属于相同 object。
二:语义分割
2.1 FCN


1)将全连接层替换为卷积层:从而可以接收不同大小图片的输入;其次可以进行像素级分类
- 在恢复高分辨率图像时,结合前面卷积层的信息,进行融合,相加。
不足:没有全局信息,在结合前面卷积层时都是局部信息。
2.2空洞卷积
2.2.1 空洞卷积



空洞卷积可以扩大感受野,但存在问题:

1)kernel 并不连续,也就是并不是所有的 pixel 都用来计算了
2)缺少局部关联信息,上下文信息。大 dilation rate 的信息或许只对一些大物体分割有效果,而对小物体来说可能则有弊无利了。
解决方案:Hybrid Dilated Convolution (HDC)
第一个特性是,叠加卷积的 dilation rate 不能有大于1的公约数。比如 [2, 4, 6] 则不是一个好的三层卷积,依然会出现 gridding effect。
第二个特性是,我们将 dilation rate 设计成 锯齿状结构,例如 [1, 2, 5, 1, 2, 5] 循环结构。
第三个特性是,我们需要满足一下这个式子:
其中 是 i 层的 dilation rate 而 是指在 i 层的最大dilation rate,那么假设总共有n层的话,默认 。假设我们应用于 kernel 为 k x k 的话,我们的目标则是 ,这样我们至少可以用 dilation rate 1 即 standard convolution 的方式来覆盖掉所有洞。
一个简单的例子: dilation rate [1, 2, 5] with 3 x 3 kernel (可行的方案)
2.2.2 Deeplab系列
v1 & v2 
v3 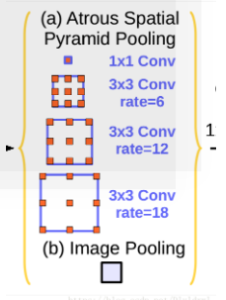


v3+ 
不足:容易出现分类错误,因为脱离了上下文信息。
2.2.3 基于上下采样结构

上采样的几种方式
1)反卷积


2)up-pooling

3)双线性差值

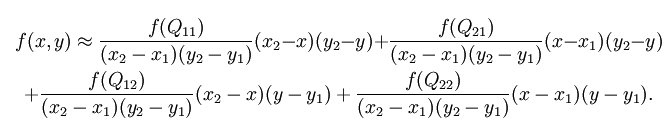
Unet

- SegNet

- FC-DenseNet

Dense Dlock(DB)的layer由BN,ReLU,3 × 3卷积,dropout(p=0.2)组成,每个DB模块包括4 layer,采用稠密连接方式,増量率k=16。
Transition down(TD)的layer包含BN,ReLU,1×1卷积,dropout(p=0.2)和max pooling(2×2)组成。
Transition up由3 × 3转移卷积组成。m表示block输出特征图的通道数,c表示类别。
2.2.3 基于全局信息结构
ParseNet

l2正则为了让两个特征相融合
这里的结构可以添加到很多层中,例如下表所示的fcn的结构中。
- GCN
**
**
使用大的卷积核来提取全局信息
3.EncNet

Context Encoding Module可以捕获场景的语义上下文并选择性地强调与类别相关的特征图。
常规的训练过程中只用了逐像素的分割loss,没有利用场景的上下文。引入了Semantic Encoding Loss(SE-loss),SE-loss以非常小的计算代价强制网络理解全局信息。在Encoding Layer上额外加入一个全连接层和sigmoid激活函数用binary cross entropy loss来预测在场景中是否有某一类存在。在实际中,发现对于小物体的分割有改进。
2.2.4 基于多尺度上下文融合和扩大感受野
Deeplabv2之后的系列
PspNet

3.Gated-SCNN


这里是gated conv layer 的具体形式。在论文中,是将不同层的regular stream和shape stream的特征图进行concatenate,然后通过1x1的标准卷积,最后通过sigmoid函数得到attenion map。如下图所式,其中||就是concatenate操作
得到attention map之后,GCL用于将shape stream的输出特征图st和attention map (at)的元素点积,卷积之后通过一次残差网络且通道加权值为wt,最后GCL计算如下所示
下面这个分支用来处理边界信息,门控。
三:实例分割
3.1:基于候选框
SDS

四个流程:候选区域提取-特征提取-分类-边界圆滑
MNC|

三个步骤:候选框提取(RPN)-分割-分类
mask r-cnn

第一个阶段:利用RPN产生RoI
第二个阶段:预测类别;bounding box偏移量; 二分类mask对每一个RoI
3.2:基于分割掩码候选生成
DeepMask

两个分支
输入是图片patch的形式
(1)生成一个mask,表示patch上每个pixel是否属于物体
(2)得到一个objectness score,表示这个patch的中心是否包含物体的置信度。
sharpMask

从下到上:生成粗糙的分割结果
从上到下:对边界不断进行refine
3.3:基于多尺度特征
MultiPath Network

三个特征:skip connections, foveal structure, and integral loss
3.3:基于实例的相对位置
InstanceFCN

会生成k∗k个score maps,表示的是输入图像中每一个ROI的不同位置的分数(score),也就是每个像素都会有k×k个不同的值,每个score map只表示instance的某个相对位置的得分。
比如,左上角的一张score map,代表的就是输入图像中每一个ROI中的左上角部分(标志为1的小框内部)的score


经过assembling module就可以生成all Instance map
但是并不是所有的响应都有Instance出现。所以作者在bottom branch,计算了objectness score map。将两者融合就能获得最终的Instance Segmentation。
FCIs

该方法实现了端到端的全卷积训练模型。
图像输入进来,经过卷积层提取初步特征,然后利用这些特征,一边经过RPN(Region Proposal Network)网络提取ROI区域,一边再经过一些卷积层生成2×(C+1)×k×k个特征图。2代表inside和outside两类;C+1代表图像类别一共C类,再加上背景(未知的)1类;k×k代表每一类score map中各有k个(上图的例子中k就为3)。在经过assembling之后(其实就是复制粘贴),对于每一个ROI,k×k个position-sensitive score map被综合成了一个,然后放小了16倍(长宽各变成1/4),得到2×(C+1)个特征图。然后开始并行操作,第一条线:对于每一类的ROI inside map和ROI outside map逐像素取最大值,得到了C+1个特征图,对这C+1个特征图逐个求平均值,将平均值同阈值比较,若大于阈值,则判定该ROI合理,则直接送入softmax分类器进行分类,得到图像类别。若小于阈值,则不进行任何操作。第二条线:做C+1次softmax分类,对每一个类别得到前景与背景,然后根据第一条并行线的分类结果,选择出对应类别的前景与背景划分结果。

FCIS是怎么实现图像分类与图像分割的并联呢?
通过两类score map解决,一类叫inside score map,一类叫outside score map。
inside score map表征了像素点在ROI区域内部中前景的分数,如果一个像素点是位于一个ROI区域内部并且是目标(前景),那么在inside score map中就应该有较高的分数,而在outside score map中就应该有较低的分数。反之亦然,如果一个像素点是位于一个ROI区域内部并且是背景,那么在inside score map中就应该有较低的分数,而在outside score map中就应该有较高的分数。
针对图像分割,使用两类score map,通过一个分类器就可以分出前景与背景。
针对图像分类,将两类score map结合起来,可以实现分类问题。
这样做还有一个好处,通过两类score map的结合,可以甄别出ROI检测失误的区域。
首先,对于每个ROI区域,将inside score maps和outside score maps中的小块特征图复制出来,拼接成为了ROI inside map和ROI outside map。
针对图像分割任务,直接对上述两类map通过softmax分类器分类,得到ROI中的目标前景区域(Mask)。
针对图像分类任务,将两类map中的score逐像素取最大值,得到一个map,然后再通过一个softmax分类器,得到该ROI区域对应的图像类别。
在完成图像分类的同时,还顺便验证了ROI区域检测是否合理,具体做法是求取最大值得到的map的所有值的平均数,如果该平均数大于某个阈值,则该ROI检测是合理的。
针对输入图像上的每一个像素点,有三种情况:
第一种情况是inside score高,outside score低;则该像素点位于ROI中的目标部分。
第二种情况是inside score低,outside score高,则该像素点位于ROI中的背景部分。
第三种情况是inside score和outside score都很低,那么该像素点不在任何一个ROI里面。
因此,我们在上一段中描述的,针对ROI inside map和ROI outside map中逐像素点取最大值得到的图像:如果求平均后分数还是很低,那么,我们可以断定这个检测区域是不合理的。如果求平均后分数超过了某个阈值,我们就通过softmax分类器求ROI的图像类别,再通过softmax分类器求前景与背景。
MaskLab

使用faster rcnn 生成bounding boxes
然后利用分割分支生成每个像素的语义分割结果
利用方向分支获得指向中心的每个像素的方向
最后这两个图进行建材得到新的实例分割结果
3.3:基于特征图传播
PANet

四:全景分割
输出两个通道:1.像素级类别标签(语义分割)2.每个像素的实例(实例分割)
oanet

mask rcnn:用来实例分割
最后送入spatial ranking module进行融合。
UPSNet

Multitask Network for Panoptic Segmentation
**
**
同样也用了mask-rcnn来实例分割
最后进行融合















 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









