










DCN(Deep & Cross)
目标:
斯坦福与Google联合发表在AdKDD 2017上的论文《Deep & Cross Network for Ad Click Predictions》。
特点:对Wide@Deep模型的升级,可以自动自动构造高阶交叉特征。可以说和华为同期提出的DeepFM属于同一种思想,并且走得更远。看了下作者,好像也是中国人。中国不注重AI人才,导致大量的AI领军人物流失。真是可惜。
华为同期提出的DeepFM只是用了FM替换了Wide@Deep中的Wide(LR)部分,没有提出更多的创新,DCN创新更大。
- 模型优点:自动自动构造高阶交叉特征。模型复杂度整体可控。
- 缺点:基于Embedding向量的位(bit)进行的特征交叉,没有基于向量 vector的交叉,基于向量 vector的交叉可以学到更多信息。FM是基于向量 vector的交叉,但是其复杂度基本上限制其停留在二阶交叉。
- 后续演进模型:xDeepFM,基于向量 vector的交叉,但是时间复杂度是硬伤。后续单独介绍。
概要:
本文(知乎)介绍斯坦福与Google联合发表在AdKDD 2017上的论文《Deep & Cross Network for Ad Click Predictions》。这篇论文是Google 对 Wide & Deep工作的一个后续研究,文中提出 Deep & Cross Network,将Wide部分替换为由特殊网络结构实现的Cross,自动构造有限高阶的交叉特征,并学习对应权重,告别了繁琐的人工叉乘。
文章发表后业界就有一些公司效仿此结构并应用于自身业务,成为其模型更新迭代中的一环。观看 作者对Deep & Cross的Oral视频。
动机Motivation:
针对大规模稀疏特征的点击率预估问题,Google在2016年提出 Wide & Deep 的结构来同时实现Memorization(记忆能力)与Generalization(泛化能力)。
- 但是在Wide部分,仍然需要人工地设计特征叉乘。面对高维稀疏的特征空间、大量的可组合方式,基于人工先验知识虽然可以缓解一部分压力,但仍需要不小的人力和尝试成本,并且很有可能遗漏一些重要的交叉特征。
- FM可以自动组合特征,但也仅限于二阶叉乘。
能否告别人工组合特征,并且自动学习高阶的特征组合呢?Deep & Cross(DCN) 即是对此的一个尝试。
Model介绍:
类似Wide & Deep,Deep & Cross的网络结构如图1所示,可以仔细观察下:

文中对原始特征做如下处理:
-
- 对sparse特征进行embedding,对于multi-hot的sparse特征,embedding之后再做一个简单的average pooling;
-
- 对dense特征归一化,然后和embedding特征拼接,作为随后Cross层与Deep层的共同输入。

注意:这里提供了一种思想:Cross层与Deep层的输入相同,后面证实,这种方法可以让模型通过线性的Cross层,结合深度Deep层进行后向反馈,能起到一种线性的Cross层给深度Deep层减负的作用,效果比“Cross层与Deep层的输入不同 ”更好。
Cross Layer交叉层
Cross的目的是以一种显示、可控且高效的方式,自动构造有限高阶交叉特征,我们会对这些特点进行解读。Cross结构如上图1左侧所示,其中第 l + 1 l+1 l+1层输出为:

即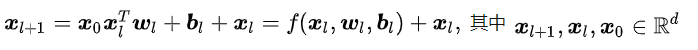
Cross Layer 设计的巧妙之处全部体现在上面的计算公式中,我们先看一些明显的细节: - 对dense特征归一化,然后和embedding特征拼接,作为随后Cross层与Deep层的共同输入。
- 每层的神经元个数都相同,都等于输入 x 0 x_{0} x0的维度 d d d ,也即每层的输入输出维度都是相等的;
- 受残差网络(Residual Network)结构启发,每层的函数 f f f 拟合的是 x l + 1 − x l x_{l+1}-x_{l} xl+1−xl的残差,残差网络有很多优点,其中一点是处理梯度消失的问题,使网络可以“更深”.
那么为什么这样设计呢?Cross究竟做了什么?对此论文中给出了定理3.1以及相关证明,但定理与证明过程都比较晦涩,为了直观清晰地讲解清楚,我们直接看一个具体的例子:假设Cross有2层,

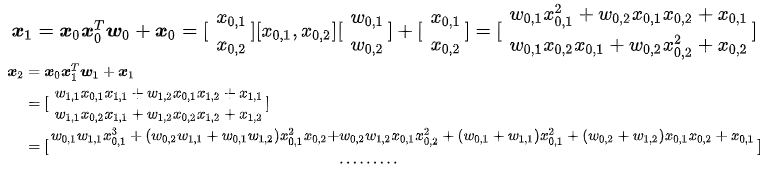
最后得到

参与到最后的
l
o
s
s
loss
loss计算。
可以看到
x
1
x_{1}
x1 包含了原始特征
[
x
0
,
1
,
x
0
,
2
]
[x_{0,1},x_{0,2}]
[x0,1,x0,2]从一阶到二阶的所有可能叉乘组合,而
x
2
x_{2}
x2包含了其从一阶到三阶的所有可能叉乘组合。现在大家应该可以理解cross layer计算公式的用心良苦了,上面这个例子也可以帮助我们更深入地理解Cross的设计:
-
有限高阶:叉乘阶数由网络深度决定,深度 L c L_{c} Lc 对应最高 L c + 1 L_{c}+1 Lc+1 阶的叉乘.
-
自动叉乘:Cross输出包含了原始特征从一阶(即本身)到 L c + 1 L_{c}+1 Lc+1 阶的所有叉乘组合,而模型参数量仅仅随输入维度成线性增长: 2 ∗ d ∗ L c 2*d*L_{c} 2∗d∗Lc
-
参数共享:不同叉乘项对应的权重不同,但并非每个叉乘组合对应独立的权重(指数数量级), 通过参数共享,Cross有效降低了参数量(这个在很多模型中有体现,比如GRU,记忆门和遗忘门用一个门限来控制,CNN中每层一个卷积核,并非每次运算一个卷积核,也是相同的参数共享思想)。此外,参数共享还使得模型有更强的泛化性和鲁棒性。例如,如果独立训练权重,当训练集中 x i = 0 ⋂ x j = 0 x_{i}=0\bigcap x_{j}=0 xi=0⋂xj=0这个叉乘特征出现 ,对应权重肯定是零,而参数共享则不会,类似地,数据集中的一些噪声可以由大部分正常样本来纠正权重参数的学习.
这里有一点很值得留意,前面介绍过,文中将dense特征和embedding特征拼接后作为Cross层和Deep层的共同输入。这对于Deep层是合理的,但我们知道人工交叉特征基本是对原始sparse特征进行叉乘,那为何不直接用原始sparse特征作为Cross的输入呢?
结合这里介绍的Cross设计,每层layer的节点数都与Cross的输入维度一致的,直接使用大规模高维的sparse特征作为输入,会导致极大地增加Cross的参数量。当然,可以畅想一下,其实直接拿原始sparse特征喂给Cross层,才是论文真正宣称的“省去人工叉乘”的更完美实现,但是现实条件不太允许。所以将高维sparse特征转化为低维的embedding,再喂给Cross,实则是一种trade-off的可行选择。
联合训练
模型的Deep 部分如图1右侧部分所示,DCN拼接Cross 和Deep的输出,采用logistic loss作为损失函数,进行联合训练,这些细节与Wide & Deep几乎是一致的,在这里不再展开论述。
另外,文中也在目标函数中加入L2正则防止过拟合。
模型分析
设初始输入
x
0
x_{0}
x0维度为
d
d
d,Deep和Cross层数分别为
L
c
r
o
s
s
L_{cross}
Lcross 和
L
d
e
e
p
L_{deep}
Ldeep,为便于分析,设Deep每层神经元个数为
m
m
m ,则两部分的参数量为:
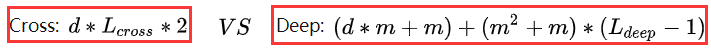
可以看到Cross的参数量随
d
d
d 增大仅呈“线性增长”!相比于Deep部分,对整体模型的复杂度影响不大,这得益于Cross的特殊网络设计,对于模型在业界落地并实际上线来说,这是一个相当诱人的特点。
Experiment测试结果
对比方法 文中选择DNN,LR,FM与Deep Cross(DC)作为对比方法,其中DNN可看作将DCN去除Cross部分,LR使用所有稀疏特征(dense特征会被离散化)与部分精选交叉特征。
实验结果 实验结果如下表,DCN不但效果明显最优,而且相比之下仅用了DNN的40%内存。

作者进一步对比了DCN与DNN在memory占用和效果上的差异,实验结果如下两表所示。为达到同样性能,DCN所需的参数量显著更少;此外,随着参数量的上升,DNN与DCN的差距在减小,但DCN仍稳定占优。相比DNN,Cross可以辅助Deep,减小了Deep的“工作量”,通过特殊的cross layer设计,用更少的参数量有效捕获有意义的、DNN难以捕捉的特征相关性。


文中也在两个Non-CTR数据集——Forest Covertype和Higgs上进行了实验,这是UCI上的公开数据集,结果类似,DCN最优。此外,文中也对cross层数进行了实验,实验显示cross层并非越多越好,具体结果如下图:

Conclusion结论
-
- 论文提出一种新型的交叉网络结构 DCN,其中 Cross 可以显示、自动地构造有限高阶的特征叉乘,从而在一定程度上告别人工特征叉乘,“一定程度”是因为文中出于模型复杂度的考虑,仍是仅对sparse特征对应的embedding作自动叉乘,但这仍是一个有益的创新。
-
- Cross部分的复杂度与输入维度呈线性关系,相比DNN非常节约内存。实验结果显示了DCN的有效性,DCN用更少的参数取得比DNN更好的效果。
-
- 共享参数的设计,Cross层与Deep层的输入相同,是其提供的新思想。














 3861
3861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









