






参考
可变形卷积(DCN,Deformable Convolution Network)-CSDN博客
https://blog.csdn.net/zyw2002/article/details/132333731
背景
论文发布时间:2017v1, ICCV-->2018v2(使用权重,对非目标区域的权重置为0)-->2023v3
几何变换能力主要来源:数据增强,模型容量,小模块的设计(小平移不变性的最大池化)
原理
简介
1.一种可学习的自适应模块,与注意力机制BAM、CBAM相似。
2.在标准卷积操作中的采样位置加一个偏移量,能够推广尺度、长宽比和旋转各种变换,这相比于一般的图像增强范围更广一些,效果如下图1所示。
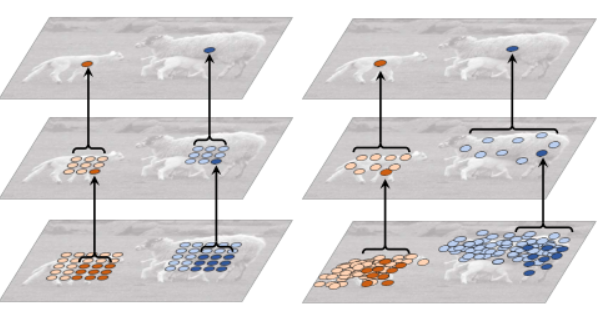
图1 左图为普通卷积,右图为可变形卷积
细节
(理解的不对,随时批评!!)
通过卷积核感受野的变化获取目标的形状,姿态,对非刚体的形变问题有较好的解决效果。
比如卷积是3*3卷积,步长为3,3*3内部每个特征点处都会存在其他偏置点插值后的像素值,这样神经网路的特征提取在这个特征点包含着不同位置的信息。
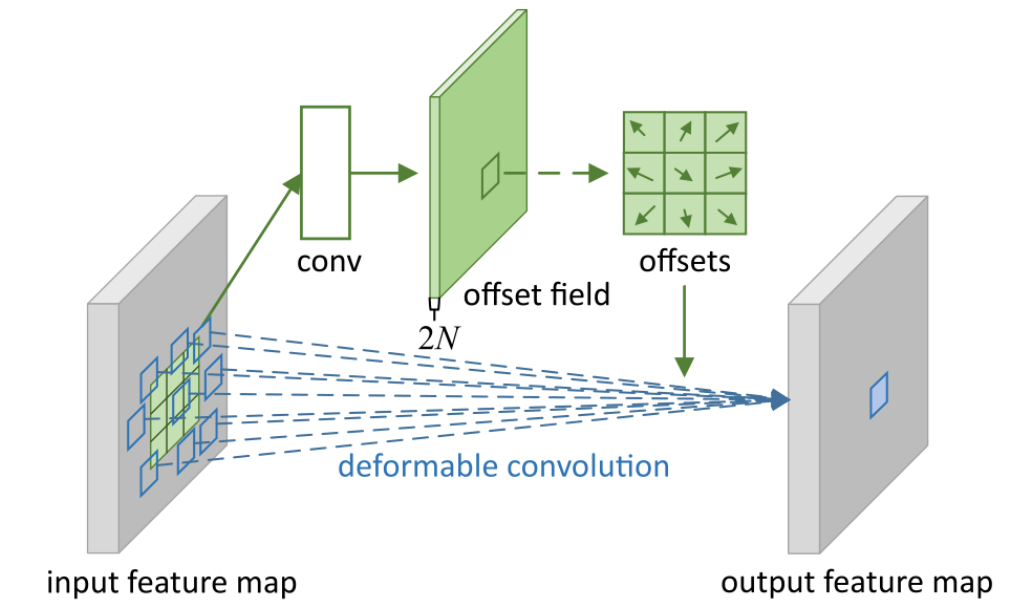 图2 变形卷积原理图
图2 变形卷积原理图
双线性插值是为了得到采样点在特征点处的像素值。
import torch
from torch import nn
class DeformConv2d(nn.Module):
def __init__(self, inc = 3, outc = 3, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
新增modulation 参数: 是DCNv2中引入的调制标量
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
# 输出通道是2N
nn.init.constant_(self.p_conv.weight, 0) #权重初始化为0
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation: # 如果需要进行调制
# 输出通道是N
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_backward_hook(self._set_lr) # 在指定网络层执行完backward()之后调用钩子函数
@staticmethod
def _set_lr(module, grad_input, grad_output): # 设置学习率的大小
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x): # x: (b,c,h,w)
# 0. 将特征图用卷积表示成偏移量的形式,2N表示x、y在9个方向的坐标,总共18个
offset = self.p_conv(x) # (b,2N,h,w) 学习到的偏移量 2N表示在x轴方向的偏移和在y轴方向的偏移
print(f"offset:{offset.shape}")
if self.modulation: # 如果需要调制
m = torch.sigmoid(self.m_conv(x)) # (b,N,h,w) 学习到的N个调制标量
dtype = offset.data.type()
ks = self.kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
print(f"x:{x.shape}")
# 1. 将offset加上位置先验
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
print(f"p:{p.shape}")
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
print(f"q_lt:{q_lt.shape}, q_rb:{q_rb.shape}")
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
print(f"p:{p.shape}")
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# 如果需要调制
if self.modulation: # m: (b,N,h,w)
m = m.contiguous().permute(0, 2, 3, 1) # (b,h,w,N)
m = m.unsqueeze(dim=1) # (b,1,h,w,N)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1) # (b,c,h,w,N)
x_offset *= m # 为偏移添加调制标量
x_offset = self._reshape_x_offset(x_offset, ks)
print(f"x_offset:{x_offset.shape}")
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
print(DeformConv2d().forward(torch.randn((12, 3, 100, 100))).shape)














 9040
9040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









