




 本文梳理了推荐系统的发展历程,从早期的协同过滤算法,到矩阵分解、LR、FM、Word2vec、DeepWalk、GBDT+LR、Wide&Deep、DeepFM、DCN、NeutralCF、DIN、EGES、DSIN、YouTubeNet等模型。随着技术的进步,模型不断引入特征交叉、embedding、深度学习和注意力机制,以提高推荐的准确性和覆盖率。其中,EGES通过补充信息解决冷启动问题,DSIN引入session和attention捕捉兴趣变迁。未来模型趋势将更注重特征的深度利用和模型的并行计算能力。
本文梳理了推荐系统的发展历程,从早期的协同过滤算法,到矩阵分解、LR、FM、Word2vec、DeepWalk、GBDT+LR、Wide&Deep、DeepFM、DCN、NeutralCF、DIN、EGES、DSIN、YouTubeNet等模型。随着技术的进步,模型不断引入特征交叉、embedding、深度学习和注意力机制,以提高推荐的准确性和覆盖率。其中,EGES通过补充信息解决冷启动问题,DSIN引入session和attention捕捉兴趣变迁。未来模型趋势将更注重特征的深度利用和模型的并行计算能力。
推荐系统发展历程
梳理推荐系统的模型进化历程,明白模型改进了什么,有什么缺点。做到心中有一副big picture,才能明白未来模型的趋势。
前言
前期已经详细展示了各种推荐模型的原理和详解。本次按照时间线把各个模型串联起来。
一、模型进化历程
-
1、90年代,推荐算法主要是协同过滤算法,产生了基于用户(UserCF)、基于物品(ItermCF)的协同过滤算法。
- 优点:模型最简单,计算快。
- 模型缺点:行为数据非常稀疏,模型欠拟合
-
2、2006年,产生了基于矩阵分解的协同过滤算法
- 优点:有点embedding的意思,但是没有明确提出embedding技术。改善了模型数据的稀疏性,可以为没有行为数据的物品和用户做推荐,
- 实践:利用MF协同过滤算法,为校园BBS论坛推荐用户关心的top10热点帖子。
- 缺点:只能用到行为数据一个特征,没有充分利用其他信息。
-
3 、LR模型:针对协同过滤只能用一个特征的缺点,那时传统机器学习大行其道,很自然就能想到最简单的线性回归模型LR。以及一些树决策树模型,比如GBDT、randomforest等。其中以线性回归LR为代表。
- 优点:能利用多维度特征数据 ,计算速度快,目前仍有召回层采用此方法。
- 缺点:
- 1、模型过于简单,表达力不强
- 2、特征之间相互独立,未能充分挖掘特征组合的特性。
-
3、2010年,产生FM模型,针对LR模型未充分挖掘特征之间的相关性,引入了特征交叉的概念,借鉴了二阶多项式模型,引入了特征之间的二阶交叉项。

然后利用矩阵分解等优化手段,最终优化后表达式
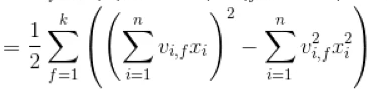
让FM可以达到线性时间的训练和预测,精度高于LR。FM
后面再2017年,台湾人提出了对FM的改进模型FFM,引入了field的概念,FFM把相同性质的特征归于同一个field,有点特征降维和特征正交化的意思。FFM 由于引入了场,使得每两组特征交叉的隐向量都是独立的,可以取得更好的组合效果。 -
2013年,谷歌提出Word2vec模型,提出了embedding概念,开启了全新是视角,后被广泛应用到推荐系统,后续产生了Iterm2vec等一系列算法,为后续模型的发展,奠定了基础。
- 优点:全新视角,用稠密向量表示物品,让计算物品间的相似性成为可能。
- 缺点:只能处理类似时序性的序列,有些没有很强时序性,比如人际关系网这种图型结构,表达能力有限。
-
2014年,进一步在Word2vec embedding基础上,产生了Graph Embedding算法,比如DeepWalk,采用随机游走的方式,去捕获关联物品间的机构化信息。
- 优点:对图结构有了表达能力
- 缺点: 仅仅考虑了图节点间的链接权重,未进一步挖掘图结构的结构信息,比如中兴节点,周围节点。
- 后续2016年斯坦福大学提出了Node2vec,通过调整随机游走的权重,从而体现网络的同质性(DFS)和结构性(BFS)。
-
同年2014年,Facebook提出了GBDT+LR模型,开启了组合模型的概念,充分利用各个模型的优点,进行强强联合,从而达到当个模型更好的准确率,性能提升3%。此时的GBDT决策树有点特征自动组合交叉的意思。GBDT+LR在当时比赛中也常见。
- 优点:在当时算是传统机器学习中最好的模型。2014年中国人陈天奇发明的XGboost算法,目前应该是决策树模型的天花板,至今在各个数据比赛中依然常见,用XGboost+LR模型结合,模型的精度还是会比单个XGboost更好,我的cdsn论文中有描述。
- 实践:实习时,采用此模型做了一个网上鲜花店的顾客兴趣商品top10推荐。效果不错。
- 缺点:传统学习算法到达了性能瓶颈,再优化很难,未能充分挖掘物品之间的内在联系信息。
-
2016年,谷歌提出了wide&deep模型正式把深度神经网络引入到推荐系统,运用在了app推荐场景中。也成了后续改进模型的baseModle。整体有点集成学习的思想,wide部分是一个线性模型,利用了线性模型的记忆功能,deep部分是个3层的神经网络,对稠密后的特征向量进行自动特征提取,因此具有泛化能力,最后集成wide和deep部分,联合训练,得到最终的结果。
- 优点:实现了对记忆和泛化能力的统一建模,提供了一种很好的思想,为后续模型改进提供了思路。
- 缺点:Wide部分还是需要人为的特征工程,人工地设计特征叉乘。
-
2017年,华为提出了DeepFM,也就是用FM替换了Wide&deep中的LR部分,这也是很容易想到的对LR模型是升级部分,但FM模型的特征交叉仅限于二阶交叉,因此此模型的创新性不大。
- 优点:升级了Wide&Deep模型
- 缺点:特征交叉仅限二阶,特征提取还不够充分。
-
2017年,微软提出了DCN模型,尝试告别人工做特征交叉,提出了一种用cross network替换wide&deep模型的LR部分,cross network有点类似残差网络的结构,下一层元素等本层元素乘以第一层元素,然后再加上本次元素,因此,cross network设计多少层,就能做到多少阶的特征交叉。此外,相比于wide@Deep,DCN的cross部分和deep部分的输入是相同的,实验表明,cross部分能帮助deep部分收敛。
- 模型优点:cross network自动做特征交叉。
- 模型缺点:这种特征交叉是bit(位)界别的,不是向量级别的。特征向量作为一个整体才更能表达一个特征维度,拆分成bit,可能会失去向量整体的意思表达。
-
2017年,新加坡国立大学提出了NeutralCF,也就是著名的双塔结构,即采用神经网络来优化最初的协同过滤算法。优化点有两个:1、基于矩阵分解的协同过滤算法,最后用点积计算相似度,点积计算相
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1890
1890




 到【灌水乐园】发言
到【灌水乐园】发言







