









2023年第十三届MathorCup高校数学建模挑战赛
C题 电商物流网络包裹应急调运与结构优化问题
原题再现:
电商物流网络由物流场地(接货仓、分拣中心、营业部等)和物流场地之间的运输线路组成,如图 1 所示。受节假日和“双十一”、“618”等促销活动的影响,电商用户的下单量会发生显著波动,而疫情、地震等突发事件导致物流场地临时或永久停用时,其处理的包裹将会紧急分流到其他物流场地,这些因素均会影响到各条线路运输的包裹数量,以及各个物流场地处理的包裹数量。
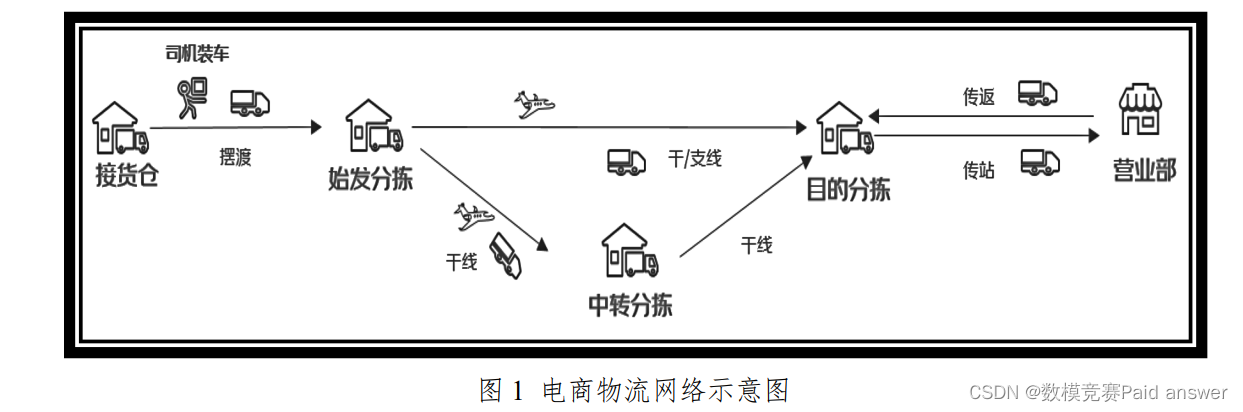
如果能预测各物流场地及线路的包裹数量(以下简称货量),管理者将可以提前安排运输、分拣等计划,从而降低运营成本,提高运营效率。特别地,在某些场地临时或永久停用时,基于预测结果和各个物流场地的处理能力及线路的运输能力,设计物流网络调整方案,将会大大降低物流场地停用对物流网络的影响,保障物流网络的正常运行。
附件 1 给出了某物流网络在 2021-01-01 至 2022-12-31 期间每天不同物流场地之间流转的货量数据,该物流网络有 81 个物流场地,1049 条线路。其中线路是有方向的,比如线路 DC1→DC2 和线路 DC2→DC1 被认为是两条线路。假设每个物流场地的处理能力和每条线路的运输能力上限均为其历史货量最大值。
基于以上背景,请你们团队完成以下问题:
问题 1:建立线路货量的预测模型,对 2023-01-01 至 2023-01-31 期间
每条线路每天的货量进行预测,并在提交的论文中给出线路 DC14→DC10、
DC20→DC35、DC25→DC62 的预测结果。
问题 2:如果物流场地 DC5 于 2023-01-01 开始关停,请在问题 1 的预测基础上,建立数学模型,将 DC5 相关线路的货量分配到其他线路使所有包裹尽可能正常流转,并使得 DC5 关停前后货量发生变化的线路尽可能少,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期部分货量没有正常流转,你们的分流方案还应使得 2023-01-01 至 2023-01-31 期间未能正常流转的包裹日累计总量尽可能少。正常流转时,请给出因 DC5 关停导致货量发生变化的线路数及网络负荷情况;不能正常流转时,请给出因 DC5关停导致货量发生变化的线路数、不能正常流转的货量及网络的负荷情况。
问题 3:在问题 2 中,如果被关停的物流场地为 DC9,同时允许对物流网络结构进行动态调整(每日均可调整),调整措施为关闭或新开线路,不包含新增物流场地,假设新开线路的运输能力的上限为已有线路运输能力的最大值。请将 DC9 相关线路的货量分配到其他线路,使所有包裹尽可能正常流转,并使得 DC9 关停前后货量发生变化的线路数尽可能少,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期没有满足要求的流转方案,你们的分流方案还应使得 2023-01-01 至 2023-01-31 期间未能正常流转的包裹日累计总量尽可能少。正常流转时,请给出因 DC9 关停导致货量发生变化的线路数及网络负荷情况;不能正常流转时,请给出因 DC9 关停导致货量发生变化的线路数、不能正常流转的货量及网络的负荷情况;同时请给出每天的线路增减情况。
问题 4:根据附件 1,请对该网络的不同物流场地及线路的重要性进行评价;为了改善网络性能,如果打算新增物流场地及线路,结合问题 1 的预测结果,探讨分析新增物流场地应与哪几个已有物流场地之间新增线路,新增物流场地的处理能力及新增线路的运输能力应如何设置?考虑到预测结果的随机性,请进一步探讨你们所建网络的鲁棒性。
整体求解过程概述(摘要)
本文主要研究物流网络的优化问题。根据神经网络模型以及熵权法测评模型求解出物流网络优化的结果。
针对问题一,根据附件中的历史数据进行构建总货物量的预测模型,建立出神经网络模型,从而求解出2023-01-01 至 2023-01-31 期间DC14→DC10、DC20→DC35、DC25→DC62的预测结果。
针对问题二,根据问题一中建立的预测模型的基础上对于DC5站点停用之后对于相关站点会发生的影响以及对于其他线路是否因为DC5的停用发生负荷现象做出预测以及给出处理的方法,优化问题二中所建立的预测模型从而求解出题中所需要的结果。
针对于问题三,问题三在问题二的条件下增加了日期作为动态处理的条件,从而处理问题三的过程中可以采用以问题二中所求解的模型进行推理,以问题二的模型为基础,增加一个动态处理,使得达到问题三所需要的数据。
针对于问题四,问题四针对于物流网络中各个站点以及各条线路的评测分析,通过选择对各线路和站点科学性全面性的评测条件,建立熵权法评测模型求解其权重以及成绩最后进行排名从而得到重要程度的排名,最后根据高分和实际负荷率的对比寻找需要进行新增或者更新的站点或线路从而达到物流网络的优化。
模型假设:
1.不考虑物流配送装卸时所耗时间。
2.不考虑物流配送在各个配送点的停留时间。
3.假设配送到达目的区域工作负荷只与货量的数量有关,与目的区域人员等其他因素无关。
问题分析:
问题1通过建立线路货量的预测模型,对 2023-01-01 至 2023-01-31 期间每条线路每天的货量进行预测,随后给出线路 DC14→DC10、DC20→DC35、DC25→DC62 的预测结果。根据各条线路的历史数据进行预测,建立预测模型时,可以选择的预测方法有很多,如典型的时间序列预测,神经网络预测等等。
文中选取了神经网络预测,通过对总货物量的数据进行预测,在进行所需要线路的预测,从而得到所需要的结果。
在以物流场地 DC5 于 2023-01-01 开始关停为约束条件,去尽可能完成目标其他路线尽可能正常流转,工作负荷尽可能均衡。先将所有可以代为分配的起点和终点进行统计,利用Dijkstra算法进行计算出任意两地之间的邻接矩阵,然后对每一条路的起点和终点的组合建立最短路模型,求解得最短路径的结果。将结果中重复的路径进行去重得到目标路径。在此基础上量化各线路的负荷率,通过负荷率的方差作为目标函数进行构建非线性规划模型,将数据带入模型中求解出对应的符合率,对各站点负荷率进行分析处理,若负荷率出现大于1时按拥堵处理后更新次日的货物量得到2023.01.01-2023.01.31的数量。
问题3中以DC9的关停为假设条件,再将结合每月各站点的实际数据对其当日的线路分配进行求解预测,在结合问题2中所建立的模型进行进一步的求解并设计动态的优化算法。最后对于每日的线路及负荷进行求解。
问题4中对于附件数据的评估首先要进行对于物流站点的各个方面进行科学性、全面性的评估和分析,同理站点也是一样进行分析处理。对于评估的处理等级可以使用构建站点及线路的重要程度的综合评价的体现,建立熵权法模型对线路和站点进行评测。在评测结束后,对于负荷率较高的站点和线路进行重新规划可以达到缓解压力的作用最后通过得到的数据进行对于整体鲁棒性的分析得到最后的数据答案。
模型的建立与求解整体论文缩略图

全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:(代码和文档not free)
import pandas as pd
df = pd.read_excel("附件1:物流网络历史货量数据.xlsx",sheet_name='汇总')
for p in df['线路1'].unique():
df.loc[df['线路1'] == p].to_excel(f'{p}_线路.xlsx',index=False)
import os
#获取指定文件下所有文件名
filename = os.listdir('F:/数学建模历年论文/2023mathorcup/2023年MathorCup高校数学建模挑战赛赛题/C题/分组后的结果存储')
import numpy as np
from datetime import datetime
for i in range(len(filename)):
df = pd.read_excel(r'F://数学建模历年论文//2023mathorcup//2023年MathorCup高校数学建模挑战赛赛题//C题//分组后的结果存储//' + filename[i])
#print(df)
m=len(df['货量'])
amean=df['货量'].mean() #计算所有数据的平均值
df['日期'] = pd.to_datetime(df['日期'])
df['month'] = df['日期'].dt.month
df['day'] = df['日期'].dt.day
#print(df['day'])
#print(df)
cmean=df.loc[(df['month']==df['month']) & (df['day']==df['day']),['货量']].mean()
# #cmean=df['货量'].mean(axis=0) #逐列求均值
r=cmean/amean #计算季节系数
w=np.arange(1,m+1)
# #print(w)
yh=df['货量'].dot()/m #计算下一年的预测值
# yj=yh/m #计算预测年份的季度平均值
# yjh=yj*r #计算季度预测值
# print("下一年1月的预测值为:",yjh)
import numpy as np
m,n=df.shape
amean=df['货量'].mean() #计算所有数据的平均值
cmean=df['货量'].mean(axis=0) #逐列求均值
r=cmean/amean #计算季节系数
w=np.arange(1,m+1)
yh=w.dot(df['货量'].sum(axis=1))/w.sum() #计算下一年的预测值
yj=yh/n #计算预测年份的季度平均值
yjh=yj*r #计算季度预测值
print("下一年1月的预测值为:",yjh)















 2186
2186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









