






一、切割数据集方法获取最佳分数和超参数
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# 1.导入数据集
iris=load_iris()
#2.预处理,划分数据及为 训练集特征值,测试集特征值,训练集目标值,测试集目标值(x代表特征值,y代表目标值)
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.3,random_state=22)
#3.特征工程,因为归一化容易受最大最小点影响,所以一般选用标准化
transfer=StandardScaler()
transfer.fit_transform(x_train)
transfer.transform(x_test)
#4.模型训练 5.模型评估
best_k,best_p,best_s=1,1,0
for k in range(1,9):
for p in range(1,5):
estimator=KNeighborsClassifier(n_neighbors=k,p=p)
estimator.fit(x_train,y_train)
s=estimator.score(x_test,y_test)
if s >= best_s:
best_k,best_p,best_s=k,p,s
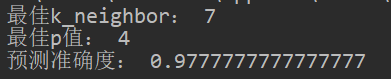
print('最佳k_neighbor:',best_k)
print('最佳p值:',best_p)
print('预测准确度:',best_s)
运行结果:
二、交叉验证、网格搜索选取最佳参数
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# 1.导入数据集
iris=load_iris()
#2.预处理,划分数据及为 训练集特征值,测试集特征值,训练集目标值,测试集目标值(x代表特征值,y代表目标值)
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.3,random_state=22)
#3.特征工程,因为归一化容易受最大最小点影响,所以一般选用标准化
transfer=StandardScaler()
transfer.fit_transform(x_train)
transfer.transform(x_test)
#4.进行机器学习模型训练, 进行交叉验证网格搜索
estimator=KNeighborsClassifier()
param_grid={'n_neighbors':(1,2,3,4,5,6,7,8,9),'p':(1,2,3,4,5)}
estimator=GridSearchCV(estimator,param_grid=param_grid,cv=3)
estimator.fit(x_train,y_train)
#5.模型评估
#查看交叉验证结果
print("最好的参数模型:\n", estimator.best_estimator_)
# print('*'*50)
# print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
print('*'*50)
print('最好的分数:\n',estimator.best_score_)
#和真实值进行对比
# y_predict=estimator.predict(x_test)
# print('真实值和预测值进行对比:',y_predict==y_test)
#计算准确度
print('*'*50)
score=estimator.score(x_test,y_test)
print('预测准确度:\n',score)
运行结果:

三、比较
从我们上面的结果我们可以看出,虽然给出的两个超参数给出的选择范围是一致的,但是他们得出的最佳模型和分数都不一致,而且,在对测试集的预测分数上(预测准确度),分割数据集得出的分数什么还要高一点。
我的理解:
1.GridSearchCV比分割数据集多出了交叉验证的部分,这就使得,GridSearchCV方法得出的模型泛化能力更强。所以我们看到经过交叉验证过的模型在训练集中的最佳分数是很高的。
2.分割数据集中最佳分数是根据不断地对测试集进行预测得出的,所以最后分数很高,而且最后选出的超参数也是最适合于给定测试集的超参数,但是如果换了一个测试集的话结果就不一定了。
3.GridSearchCV的目的不是选择一个对给定数据集预测效果最好的模型,而是选出一个泛化能力比较好的模型,能对不同测试集做出较准确的预测。














 7232
7232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









