







Transformer 的最大输入长度,即max_seq_length / max_source_length是一个非常值得注意的参数。
Transformer的encoder大多是Auto-encoder的结构,不同于Auto-regressive encode,由于auto-encoder缺乏时序序列的位置信息,因此其需要对输入的每个token的position进行编码。
而position的编码方式大致为两种:1).基于Embedding 2).非Embedding
1. Embedding编码
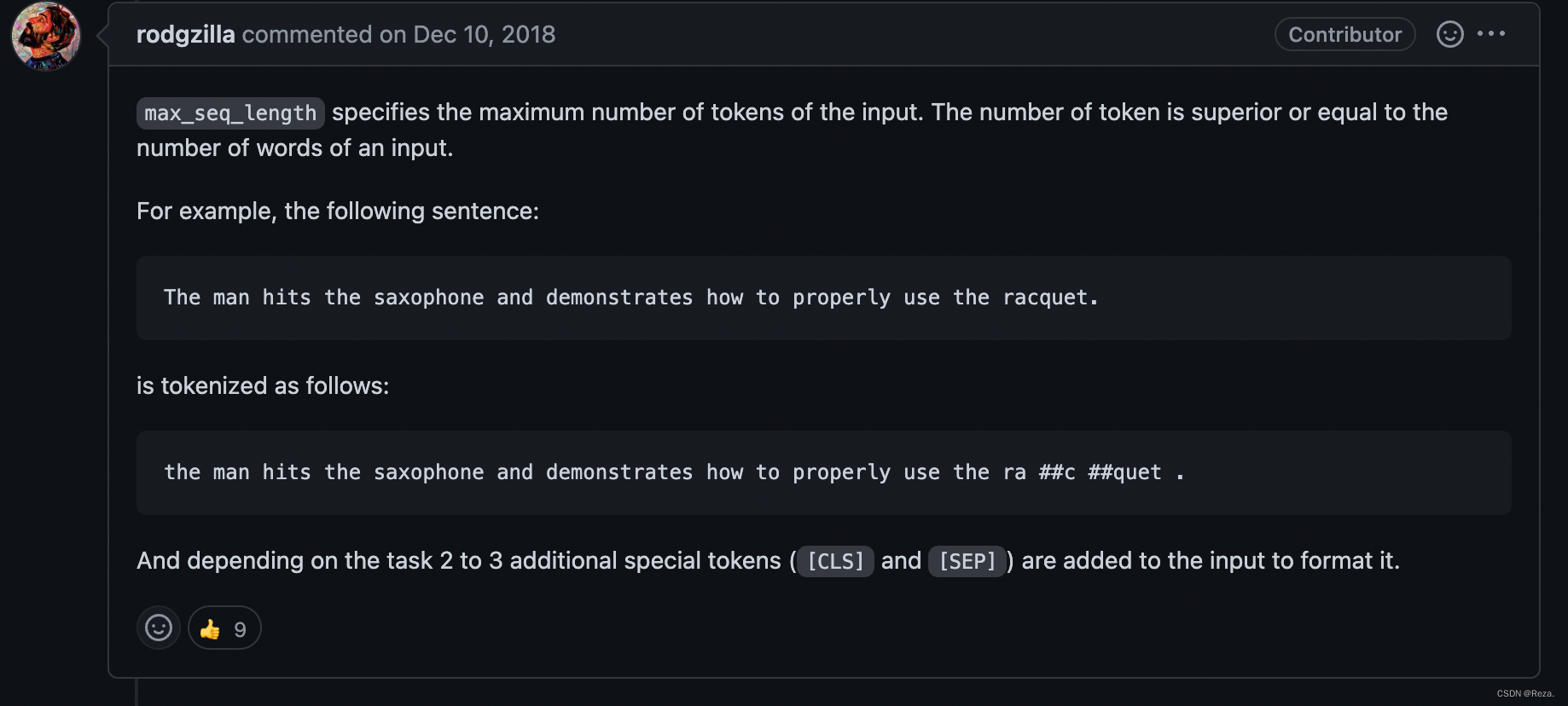
最常见的position编码方式自然就是绝对位置嵌入编码(i.e., absolute positional embeddings)。像BERT、Roberta、BART这种都是用的position embedding。也就是用每个token的index,去从embedding中取向量。
但是这也带来了一个问题,position embedding的长度是有限的,输入的tokens如果超出这个长度,就会有index error,这也是为什么会有max_seq_length这个参数,将过长的输入部分切掉。
所以,如果模型是用position embedding编码位置信息的,则必须传入正确的max_seq_length长度(可以利用tokenizer的truncation属性,指定模型config里面的max_seq_length)。
否则,一旦输入超出了这个最大长度,会报index error:
2. 非Embedding编码
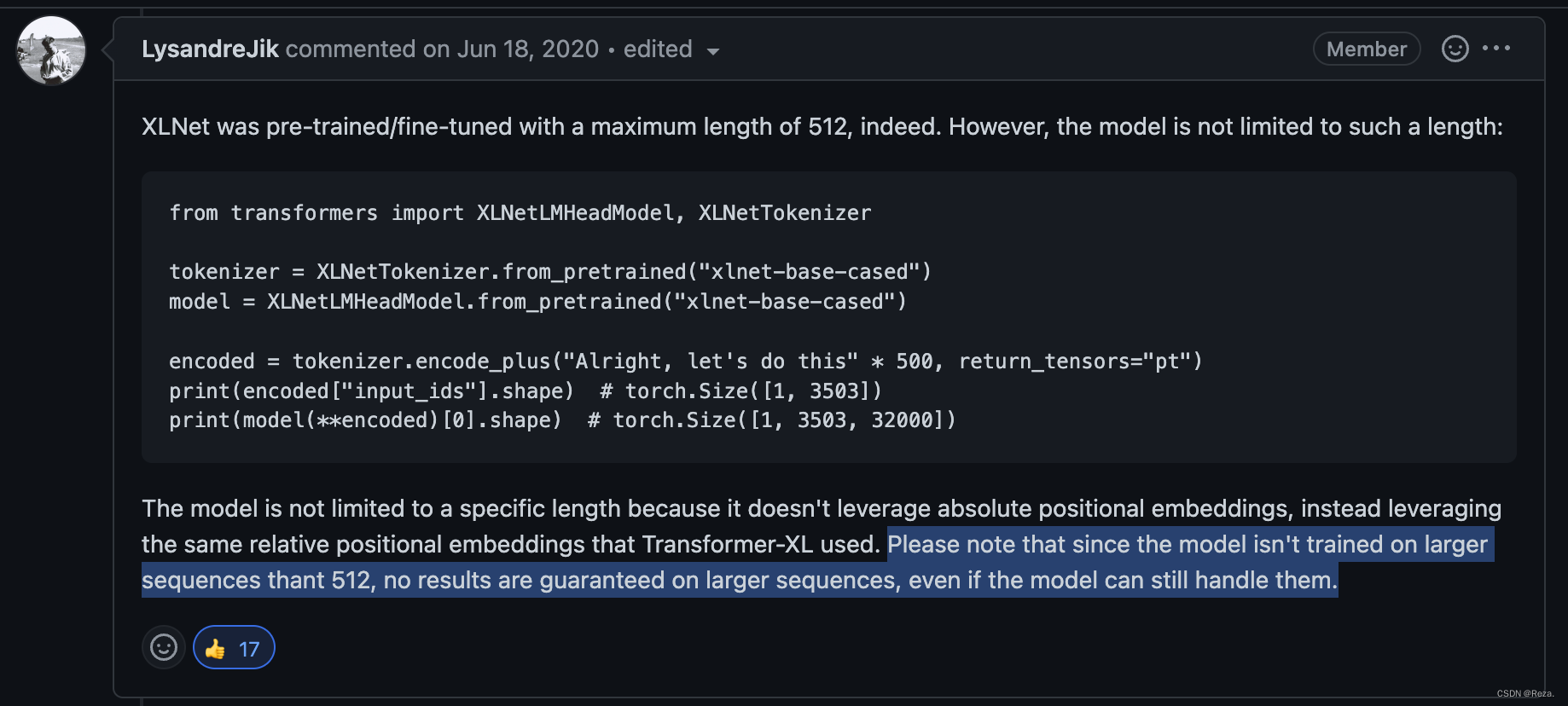
而像XLNet、T5这种模型的位置编码,则不是利用这种传统的embedding式(XLNet用的shuffle,T5用的相对位置编码),因此就不会有输入长度的限制。
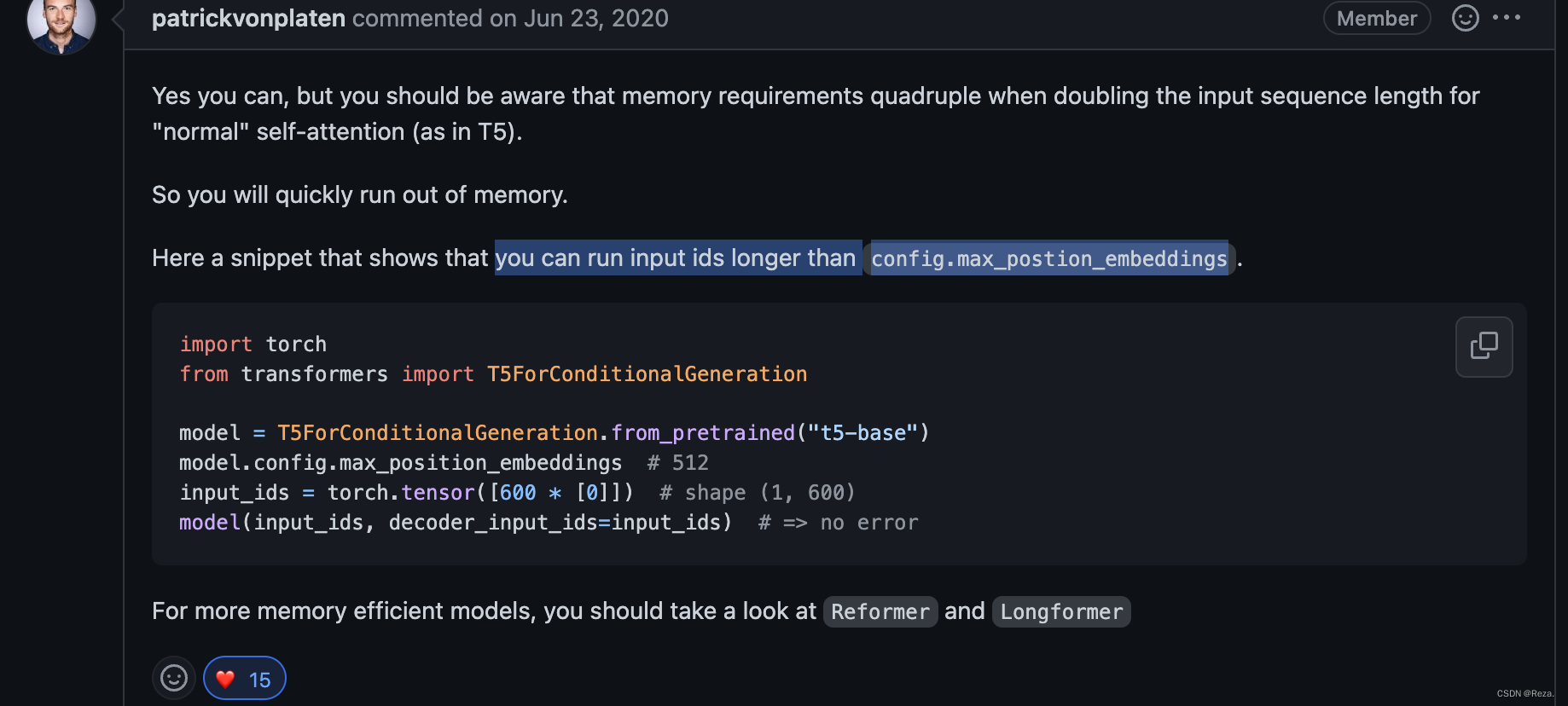
尽管huggingface的接口都提供了max_source_length这个参数选项,其值默认设定为模型预训练时使用的max_seq_length,可如果实际传入长度大于该值的input,也并不会有任何报错。
但是更大的输入长度,自然会带来更重的计算负担:
更重要的是,更长的输入也并不一定能带来更好的性能(具体看做的任务),因为这与模型预训练时存在着差别(如下图所述):
笔者在使用T5-base的时候,也尝试过将默认的
max_seq_length==512增大为1024,使用更长的input,但并未发现存在明显性能提升的现象,甚至还会略微损害性能(注:笔者使用的数据集存在大量的输入长度超过512的样本,因此排除max_seq_length不生效的情况)。当然,这个结论是比较主观和局限的,可能某些任务使用更大的max_seq_length去进行fine-tune效果会更好。

















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









