







先说结论:理论上Transformer是支持处理变长序列的。常说的对序列截断和填充是针对同一batch(方便做并行计算),不同batch之间序列长度是可以不一样的。
当然在实际应用上,如果序列太长,计算复杂度太大,一般会做截断。
下面就来分析下,我们先来看一下Transformer的结构:
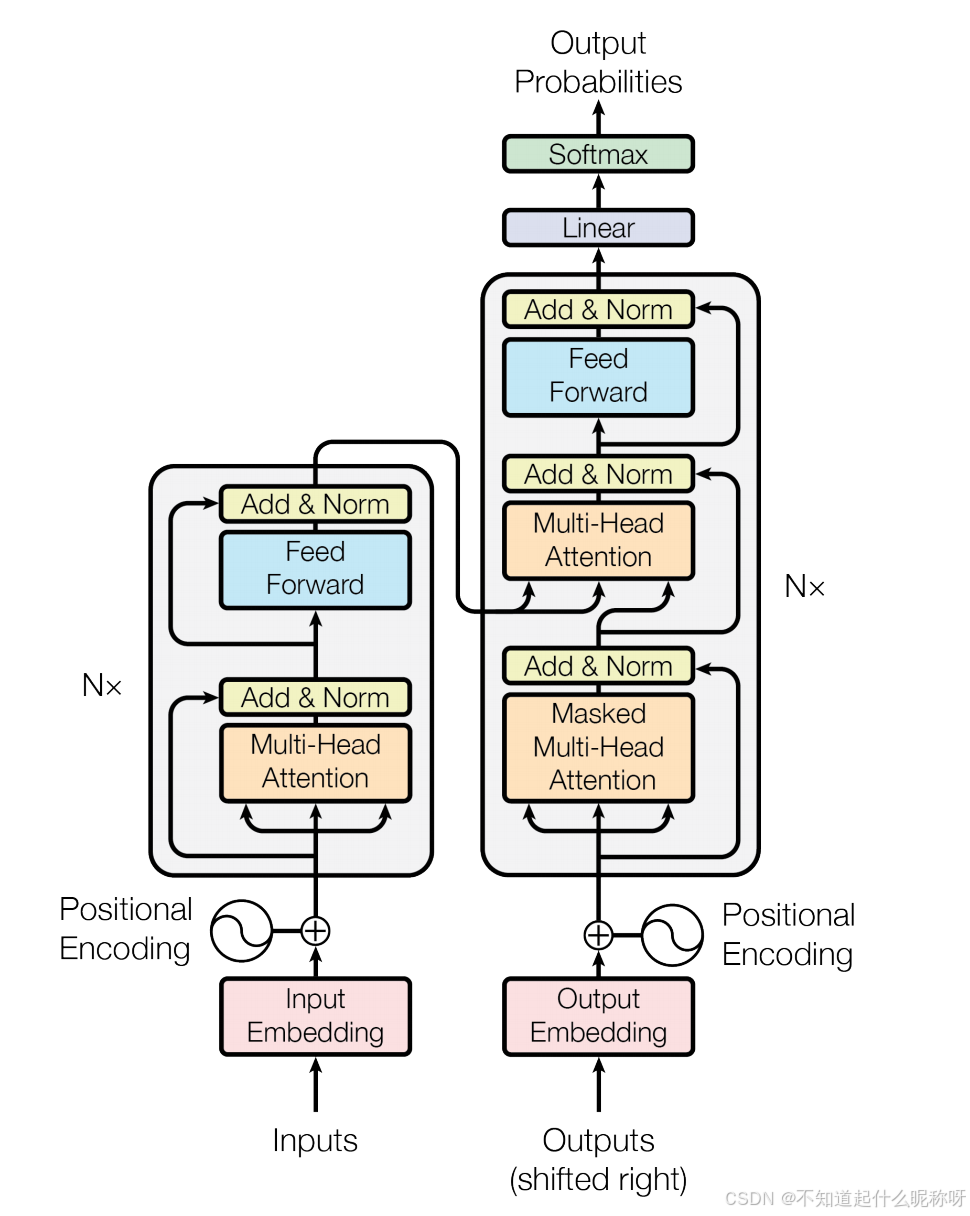
因为Encoder和Decoder结构基本一致,这里以Encoder结构为例,我们逐个模块分析。
词嵌入 & 位置编码
词嵌入和位置编码都是从向量空间中找到token(位置)对应的向量表征。如果输入的是变长序列,token变多,向量维度变大,但并不影响计算,参数量也没有增加,可以处理。
多头注意力机制
多头注意力机制的实现逻辑是输入向量分别经过Projection Layer(线性变换层)得到三个矩阵Q、K、V。然后拆分成多个矩阵计算Q、K的相关性。序列长度变长,计算量变大,但是参数量没有增加,可以处理。
残差结构 & 标准化
这块就不用说了,简单的相加和norm处理。
FFN
最重要的是这块,之前一直以为在这里是序列emb拼接过两层的全连接。但是,FFN的计算是recurrent的,这里会独立的对每个位置进行处理,不会考虑序列中其他位置的信息,也就是说,[emb1,emb2,emb3,emb4]会分别进行相同的处理。每个位置都会独立的通过两层的全连接层,不是concat之后再经过全连接层,当然FFN部分的参数是共享的。序列长度变长,带来的仅仅是计算开销变化,可以处理。
综上,理论上Transformer是支持处理变长序列的。
推理阶段为什么有时候也需要pad?
既然Transformer可以处理变长序列,为什么推理阶段有时候还需要pad呢?
是这样,有时候为了提高推理效率和充分利用硬件资源,推理阶段也会做批处理。比如做机器翻译任务,需要将多个句子翻译成中文,就可以做批处理,不过句子长度不一,这时候就需要做pad了。
当然了,如果每次infer的batch_size都是1,也就没必要做pad了。

















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









