






说在前面:本文是通过CUDA实现GELU算子,输入和输出的数据是FP16类型的,通过自定义向量结构体进行向量化访存的方式来提高算子工作效率,并会详细解释相关代码。
一. 算子公式
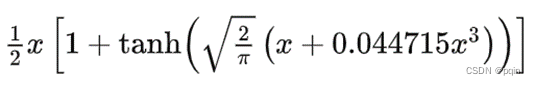
二. 优化思路
可以看出这是一个访存密集型的算子,我们可以从访存的角度和计算的角度进行优化。
访存角度:1. 向量化访存;2. 利用shared memory。
计算角度:1. 每个线程计算一个标量,尽可能多的利用GPU资源; 2. 将两个FP16设为一组使用FP16 intrinsic实现,但这种方式只有在安培架构及以上才能实现。
本篇博客仅通过向量化访存的方式进行优化,以8个FP16为一组进行存取。
三. 代码实现
这里我们先给出整体代码,再对其作出详细解释:
#include <stdio.h>
#include <cuda.h>
#include <cuda_fp16.h>
#include "cuda_runtime.h"
template <typename T, int Size>
struct alignas(sizeof(T) * Size) AlignedVector {
T val[Size];
__host__ __device__ inline const T& operator[](int i) const { return val[i]; }
__host__ __device__ inline T& operator[](int i) { return val[i]; }
};
template<typename T>
struct GeluFunctor {
static constexpr T alpha = static_cast<T>(0.7978845608028654);
static constexpr T beta = static_cast<T>(0.044714998453855515);
__device__ GeluFunctor() {};
__device__ T operator()(T x) const {
const T half = static_cast<T>(0.5);
const T one = static_cast<T>(1);
const T tanh_in = alpha * (x + beta * x * x * x);
return half * x * (one + tanh(tanh_in));
}
};
template<>
struct GeluFunctor<half> {
static constexpr float alpha = GeluFunctor<float>::alpha;
static constexpr float beta = GeluFunctor<float>::beta;
GeluFunctor<float> float_functor;
__device__ GeluFunctor() {};
__device__ half operator()(const half x) const {
return static_cast<half>(float_functor(static_cast<float>(x)));
}
template <int VecSize>
__global__ void FP16GeluCUDAKernel(const __half* x, __half* y, int n) {
int offset = static_cast<int>(threadIdx.x + blockIdx.x * blockDim.x) * VecSize;
int stride = static_cast<int>(blockDim.x * gridDim.x) * VecSize;
GeluFunctor<half> gelu_fwd;
__half y_reg[VecSize];
for (; offset < n; offset += stride) {
using ArrT = AlignedVector<__half, VecSize>;
const ArrT* in_arr = reinterpret_cast<const ArrT*>(x + offset);
const __half* in = reinterpret_cast<const __half*>(in_arr);
if (VecSize == 1){
y_reg[0] = gelu_fwd(in[0]);
} else {
for (int i = 0; i < VecSize; i++) {
y_reg[i] = gelu_fwd(in[i]);
}
}
*reinterpret_cast<ArrT*>(y + offset) = *reinterpret_cast<ArrT*>(y_reg);
}
}
int main() {
int n = 1000;
__half *x = new __half[n];
__half *y = new __half[n];
for (int i = 0; i < n; i++)
{
x[i] = (__half)(i);
}
__half * d_x, *d_y;
cudaMalloc((void **)&d_x, n * sizeof(__half));
cudaMalloc((void **)&d_y, n * sizeof(__half));
cudaMemcpy(d_x, x, sizeof(__half) * n, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, sizeof(__half) * n, cudaMemcpyHostToDevice);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, 0);
auto is_aligned = [](const void* p, int alignment) {
return reinterpret_cast<uintptr_t>(p) % alignment == 0;
};
constexpr auto kAlignment = alignof(AlignedVector<__half, 8>);
if (n % 8 == 0 && is_aligned(x, kAlignment) && is_aligned(y, kAlignment)) {
int thread = std::min<int>(512, deviceProp.maxThreadsPerBlock);
int block = (n + thread - 1) / thread;
block = std::min<int>(block, deviceProp.maxGridSize[0]);
FP16GeluCUDAKernel<8><<<block, thread>>>(d_x, d_y, n);
cudaMemcpy(y, d_y, sizeof(__half) * n, cudaMemcpyDeviceToHost);
}
printf("pass");
delete x;
x = nullptr;
delete y;
y = nullptr;
cudaFree(d_x);
cudaFree(d_y);
}四. 代码详解
1. AlignedVector结构体
template <typename T, int Size>
struct alignas(sizeof(T) * Size) AlignedVector {
T val[Size];
__host__ __device__ inline const T& operator[](int i) const { return val[i]; }
__host__ __device__ inline T& operator[](int i) { return val[i]; }
};可以看到我们在这里定义了一个结构体AlignedVector,这个结构体只有一个成员变量val,val是一个数组,结构体的对齐方式取决于val的数据个数和数据类型,并且重载了[],方便对val的访问。 注意第一个重载只能对数据进行读操作。这个结构体的作用就是用于数据向量化的存取。
2. GeluFunctor结构体
template<typename T>
struct GeluFunctor {
static constexpr T alpha = static_cast<T>(0.7978845608028654);
static constexpr T beta = static_cast<T>(0.044714998453855515);
__device__ GeluFunctor() {};
__device__ T operator()(T x) const {
const T half = static_cast<T>(0.5);
const T one = static_cast<T>(1);
const T tanh_in = alpha * (x + beta * x * x * x);
return half * x * (one + tanh(tanh_in));
}
};可以看出这个结构体就是在作Gelu运算,这和上面的公式是对应的,这里不做过多解释。
3. FP16GeluCUDAKernel核函数
template <int VecSize>
__global__ void FP16GeluCUDAKernel(const __half* x, __half* y, int n) 这是一个 CUDA 核函数,由 __global__ 修饰符标记,在 GPU 上执行。template <int VecSize> 是模板参数,允许函数针对不同的向量大小 VecSize 实例化。函数接受两个指针 const __half* x 和 __half* y,分别指向输入和输出数据,以及一个表示元素总数的 int n。
int offset = static_cast<int>(threadIdx.x + blockIdx.x * blockDim.x) * VecSize;
int stride = static_cast<int>(blockDim.x * gridDim.x) * VecSize;
offset计算了每个线程应该开始处理的数据索引。这考虑到了线程ID、块ID和块大小,并乘以
VecSize。stride是每个线程在处理完其初始数据后应该跳过的数据量,以处理下一批数据。
for (; offset < n; offset += stride) 这个循环对每个线程负责的数据点进行遍历。通过在每次迭代后增加 stride 来确保每个线程处理不同的数据集。因为不能保证每个线程刚好处理完所以的数据。
using ArrT = AlignedVector<__half, VecSize>;
const ArrT* in_arr = reinterpret_cast<const ArrT*>(x + offset);
const __half* in = reinterpret_cast<const __half*>(in_arr);
这里实现了数据的向量化读取。
if (VecSize == 1){
y_reg[0] = gelu_fwd(in[0]);
} else {
for (int i = 0; i < VecSize; i++) {
y_reg[i] = gelu_fwd(in[i]);
}
}
调用gelu_fwd函数进行Gelu计算,注意一个线程需要对向量中的每个元素进行计算。
*reinterpret_cast<ArrT*>(y + offset) = *reinterpret_cast<ArrT*>(y_reg);
向量化写回数据。
4. main函数
int n = 1000;
__half *x = new __half[n];
__half *y = new __half[n];
for (int i = 0; i < n; i++) {
x[i] = (__half)(i);
}
定义两个大小为 n 的数组,并分配内存,使用整数值初始化 x 数组。
__half * d_x, *d_y;
cudaMalloc((void **)&d_x, n * sizeof(__half));
cudaMalloc((void **)&d_y, n * sizeof(__half));
cudaMemcpy(d_x, x, sizeof(__half) * n, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, sizeof(__half) * n, cudaMemcpyHostToDevice);
在 GPU 上为输入 (d_x) 和输出 (d_y) 数组分配内存,将数据从主机(CPU)复制到设备(GPU)。
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, 0);
获取 CUDA 设备的属性,以确定线程和块的最大数量。
auto is_aligned = [](const void* p, int alignment) {
return reinterpret_cast<uintptr_t>(p) % alignment == 0;
};
constexpr auto kAlignment = alignof(AlignedVector<__half, 8>);
if (n % 8 == 0 && is_aligned(x, kAlignment) && is_aligned(y, kAlignment)) {
定义一个检查内存对齐的 lambda 函数。检查 x 和 y 是否按 AlignedVector<__half, 8> 的对齐方式对齐,同时确认 n 是 8 的倍数。需要注意的是当我们在CUDA中进行向量化存取的时候,往往需要检测输入、输出数据是否符合向量数据的对齐方式。这里就是在检测输入和输出数据的地址是否是向量的对齐大小的整数倍。
int thread = std::min<int>(512, deviceProp.maxThreadsPerBlock);
int block = (n + thread - 1) / thread;
block = std::min<int>(block, deviceProp.maxGridSize[0]);
计算每个块的线程数和所需的块数。
FP16GeluCUDAKernel<8><<<block, thread>>>(d_x, d_y, n);
调用之前定义的 CUDA 核函数 FP16GeluCUDAKernel,并将向量大小设置为8。这里向量的长度设为8的原因是在CUDA中我们进行向量化存取的大小要不超过128bit,FP16占用两个字节,那8个FP16刚好是128bit。
cudaMemcpy(y, d_y, sizeof(__half) * n, cudaMemcpyDeviceToHost);
printf("pass");
delete[] x;
delete[] y;
cudaFree(d_x);
cudaFree(d_y);
将结果从 GPU 内存复制回主机内存。打印“pass”表示程序运行成功。释放在主机和设备上分配的内存。
小知识
访存密集型(Memory-bound)
访存密集型的应用或算法是指其性能主要受限于内存访问速度。这意味着,程序执行的瓶颈主要在于从内存(包括主内存和缓存)中读取数据和写入数据的速度。这类问题通常有以下特征:
- 高内存访问需求:算法需要频繁地从内存中读取或写入大量数据。
- 低算术强度:算术强度是指每次内存访问所进行的计算量。低算术强度意味着相对于每次内存访问,执行的计算较少。
- 缓存未能有效利用:数据访问模式可能不规则或随机,使得缓存命中率低。
- 内存带宽饱和:监控工具显示内存带宽接近或达到极限。
优化访存密集型应用通常涉及减少内存访问次数、提高缓存利用率和优化数据访问模式。
计算密集型(Compute-bound)
计算密集型的应用或算法是指其性能主要受限于处理器的计算能力。这类问题的特征包括:
- 高算术强度:每次内存访问后,执行大量的计算操作。
- 处理器资源饱和:处理器核心的利用率高,而内存带宽使用率相对较低。
- 缓存效率较高:数据访问模式使得大部分所需数据能够高效地从缓存中获取。
- 并行计算潜力:算法可以有效地分解为并行任务,充分利用多核心或多线程的优势。
优化计算密集型应用通常聚焦于提高计算效率,例如通过算法优化减少不必要的计算、使用更有效的数学方法或者增强并行处理能力。















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









