







最近在看有关深度强化学习的内容,阅读了这篇综述性论文。本文对论文部分内容进行了整理,并翻译了文章的第12部分多智能体强化学习(Multi-Agent RL)。部分内容参考了https://mp.weixin.qq.com/s/MRS8to_Cy_p0niIkEaWsFA
深度强化学习
开始深度强化学习之前先来了解深度强化学习、深度学习、强化学习、监督学习、无监督学习、机器学习和人工智能之间的关系。
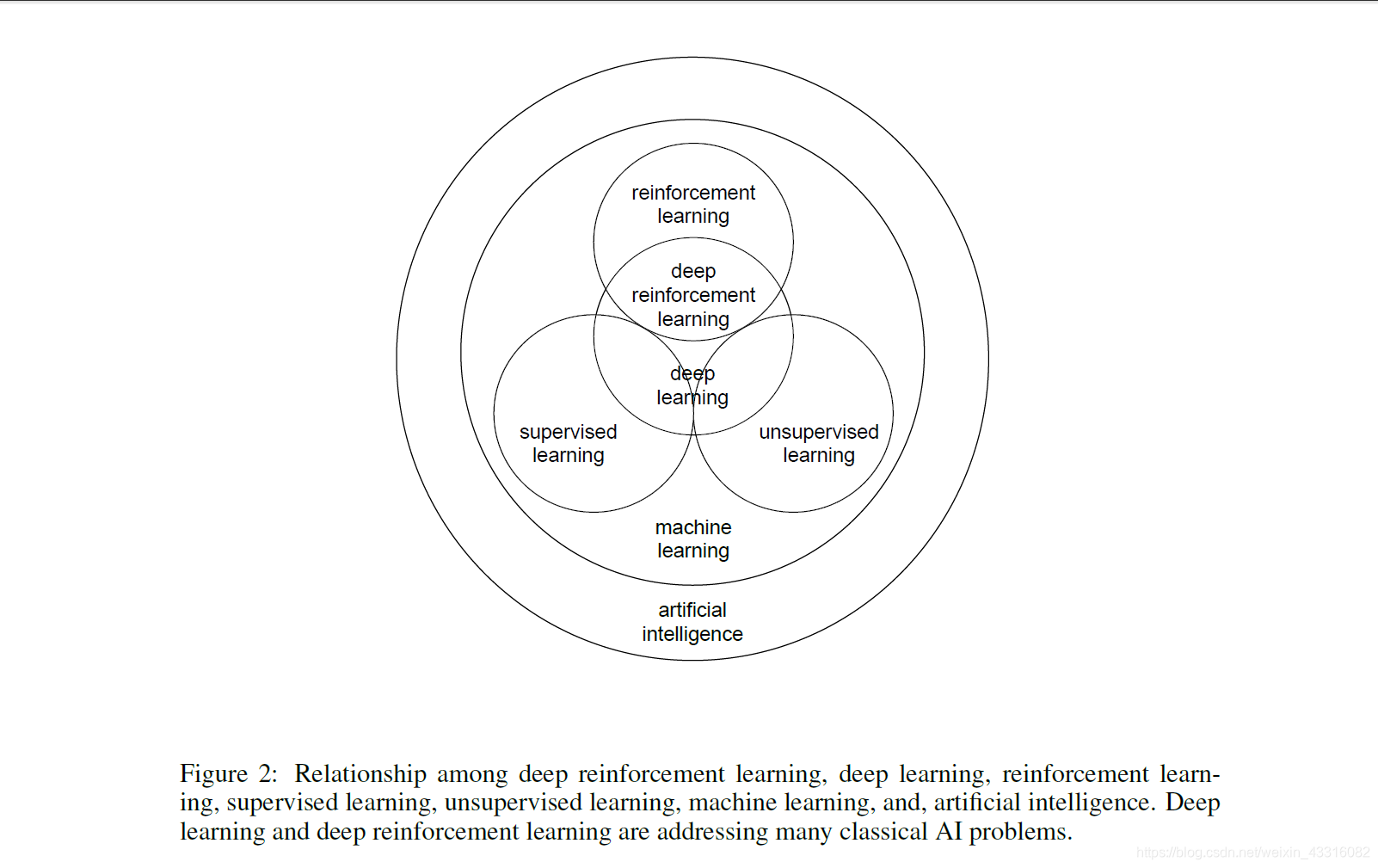
《深度强化学习》讨论了六个核心元素 (core elements): 值函数 (value function)、策略 (policy)、奖赏 (reward)、模型 (model)、探索与利用 (exploration vs. exploitation)、以及表征 (representation);
六个重要机制 (important mechanisms):注意力与存储机制 (attention and memory)、无监督学习 (unsupervised learning)、层次强化学习 (hierarchical RL)、多智能体强化学习 (multi-agent RL)、关系强化学习 (relational RL)、和元学习 (learning to learn);
以及十一个应用场景 (applications):游戏 (games)、机器人学 (robotics)、自然语言处理 (natural language processing, NLP)、计算机视觉 (computer vision)、金融和商务管理 (finance business management)、医疗(healthcare)、教育 (education)、能源 (energy)、交通 (transportation)、计算机系统 (computer systems)、以及科学、工程和艺术 (science, engineering, and art)等。
文章努力回答了下面三个问题:1)为什么用深度学习?2)最前沿的发展有哪些?3)有什么问题及解决方案?
深度强化学习最近取得了世人瞩目的成绩,比如,应用于雅达利游戏 (Atari games) 上的 DQN 算法吹响了这波深度强化学习前进的号角;在计算机围棋 (AlphaGo/AlphaGo Zero) 和德州扑克 (DeepStack) 上面取得了人工智能里程碑级别的成就。深度强化学习有很多新颖的算法被研发出来,比如,DQN、 A3C、TRPO、PPO、DDPG、Trust-PCL、GPS、UNREAL, 等等。
深度强化学习也被应用于很多很广的方向,比如,夺旗游戏 (Capture the Flag)、刀塔 (Dota 2)、星际争霸 (StarCraft II)、机器人学、动画人物模拟、智能对话、神经元网络结构设计、机器学习自动化、数据中心降温系统、推荐系统、数据扩充、模型压缩、组合优化、程序合成、定理证明、医学成像、音乐合成、化学逆合成,等等。
深度强化学习虽然已经取得了很多傲人的成绩,但是,它也有很多问题亟需解决,比如成绩分配 (credit assignment), 稀疏奖赏 (sparse reward), 采样效率 (sample efficiency), 不稳定性 (instability), 发散性 (divergence), 可解释性 (interpretability), 安全性 (safety),等等;甚至可复制性 (reproducibility) 仍然是一个问题。
《深度强化学习》提出了六个研究方向,同时作为挑战和机遇。应该提到的是,在这些方向,已经有了一些进展,比如,Dopamine、TStarBots、 unsupervised video object segmentation for deep RL、generative query network、neural-symbolic learning, universal planning networks, causal InfoGAN, meta-gradient RL, 等等。这些方向的发展,会大幅度促进强化学习乃至人工智能的发展。
1、系统地比较深度强化学习算法
2、「解决」多智能体问题
3、基于实体 (entities) 学习,而不只是基于原始数据学习
4、为强化学习设计最优的表征形式
5、自动化强化学习 (AutoRL)
6、研发强化学习杀手级应用
深度学习在第三波人工智能的蓬勃发展中,发挥着越来越深远的影响;我们也在深度学习的很多成就中看到了它的作用。强化学习提供更通用的学习和决策模式;它会深远影响深度学习、机器学习、乃至人工智能的进一步发展。
12、多智能体强化学习
多智能体RL是多智能体系统(Horling and Lesser, 2004; Shoham and Leyton-Brown, 2009; Stone and Veloso, 2000)与RL的集成。它是博弈论(Leyton-Brown and Shoham, 2008)和RL/AI的交叉点。
除了RL中的稀疏奖励和样本效率等问题外,还有一些新的问题如多重均衡,甚至还有一些基本问题如多智能体学习的问题是什么,收敛到均衡是否是合适的目标等等。因此,多智能体学习在技术上和概念上都具有挑战性,需要对要解决的问题、用于评估的标准和一致的研究议程有清晰的理解。
在完全集中的方法中,当全局状态和联合动作信息可用时,就可以估计联合Q动作值函数。这可以解决非平稳问题。然而,随着智能体数量的增加,会遇到维数灾难的问题。另一个问题是,可能很难提取分散的策略,让智能体根据自己的观察做出决策。
Littman(1994)利用随机博弈作为多智能体强化学习的框架,提出了零和博弈的minimax-Q learning算法,并在一定条件下证明了算法的收敛性。Hu and Wellman(2003)提出了一般和博弈的Nash Q-learning,并证明了其具有唯一纳什均衡的收敛性。Bowling和Veloso(2002)提出了WoLF原则来改变学习率以解决学习移动目标的问题,并在某些迭代矩阵博弈中证明了自我游戏的收敛性。这些论文与Foerster et al. (2018a)、Lowe et al.(2017)和Usunier et al.(2017)等都采用集中方法。
Tan(1993)为多智能体强化学习引入了独立Q-learning (IQL),在算法中每个智能体独立学习一个Q 动作值函数。为了使Q-learning稳定收敛,环境必须是是稳定的。然而对于多智能体系统通常不是这样,在多智能体系统中,智能体会根据其它智能体更改策略,并且环境通常是不平稳的,甚至是敌对的。独立的多智能体强化学习方法可能不会收敛。Foerster et al. (2017) 和 Omidshafiei et al. (2017)提出稳定独立方法。
Oliehoek et al. (2008)介绍了对于分散执行的集中训练范例。我们将讨论以下遵循此方案的几篇论文。
随着强化学习在单一智能体问题(如Mnih et al. (2015), Jaderberg et al. (2017), Schulman et al. (2015), Nachum et al. (2018) )和两玩家博弈(如Silver et al. (2016a; 2017); Moravcik et al. (2017))上的成功,最近,我们看到在多智能体强化学习问题上的一些进展(如Jaderberg et al. (2018) for Quake III Arena Capture the Flag, Sun et al. (2018) and Pang et al. (2018) for StarCraft II, and OpenAI Five for Dota 2)
Zambaldi et al. (2018)研究了《星际争霸2》中带有关系深度强化学习的迷你游戏,如第13章所述。Bansal et al. (2018)通过多智能体竞争研究了涌现复杂技能。Foerster et al. (2018b)提出了具有对手学习意识的学习方法,使得每个智能体都考虑环境中其它智能体的学习过程。Hoshen(2017)提出了一种带有注意神经网络的顶点注意交互网络(VAIN), 用于多智能体预测建模。Mhamdi et al. (2017)在联合行动学习者和独立学习者场景中为多智能体强化学习引入了动态安全中断。Perolat et al. (2017)提出使用多智能体强化学习解决公共池资源占用问题。Hu et al. (2018b)为星际争霸微观管理提出了对手引导的战术学习。Song et al. (2018)将生成式对抗模仿学习(GAIL) (Ho and Ermon, 2016)扩展到多智能体设置。Lanctot et al. (2018)研究了部分可观察的多智能体环境下的actor-critic策略优化。也可参见Hughes et al. (2018), Wai et al. (2018), and Zhou et al. (2018)
多智能体系统有许多应用,例如,我们将在第15章讨论游戏,第16章讨论机器人,第20.3节讨论能源,第20.4节讨论交通,第20.5节讨论计算机系统。
Busoniu et al. (2008)和Ghavamzadeh et al. (2006)对多智能体强化学习进行了调查。Parkes and Wellman (2015)对经济推理和人工智能进行了调查。
下面,我们将讨论用于分散执行的集中训练方法、博弈论和游戏中的几个问题。
用于分散执行的集中训练
一个集中的评论家可以从所有以联合行动为条件的可用状态信息中学习,并且每个智能体从它自己的观察行动历史中学习它的策略。集中的评论家只在学习过程中使用,而在执行过程中只需要分散的表演者。以下是最近提出的几种使用星际争霸作为实验平台的方法,如(Peng et al. (2017b), Foerster et al. (2018a), and Rashid et al. (2018).)
Foerster et al. (2018a)提出了反事实多智能体 (COMA)的actor-critical方法。在COMA方法下,采用分散的表演者优化策略,采用集中的评论家估计q函数,使用反事实基线边缘化一个智能体的动作,并修正其他智能体的动作,以实现多智能体的成绩分配。
一些论文提到了在多智能体强化学习中的沟通机制(Foerster et al., 2016; Sukhbaatar et al., 2016)。Peng et al. (2017b)需要沟通。
Peng et al. (2017b)提出了一个多智能体actor-critic框架,该框架采用双向协调的网络来形成团队中多个智能体之间的协调,采用动态分组和参数共享的概念来实现更好的可扩展性。在《星际争霸》的测试平台上,在没有人类演示或标注数据作为监督的情况下,该方法学习了与经验丰富的人类玩家类似的协调策略,比如无碰撞移动、打了就跑、掩护攻击以及没有过度杀伤的集中火力攻击。
在独立强化学习方法和完全中心化强化学习方法两个极端之间设计一种算法是可取的。一种方法是分解Q函数。Sunehag et al. (2017) and Rashid et al. (2018)属于这一类。
Sunehag et al. (2017)提出了值分解网络(VDN),将集中的动作值函数Q表示为单个智能体的值函数之和。在VDN中,每个agent都根据自己的观察和动作训练自己的值函数,并从其动作值函数中推导出分散策略。
Rashid et al. (2018)提出QMIX,使每个智能体网络代表一个单独的动作值函数,混合网络将它们组合成一个集中的动作值函数,采用非线性的方法,而不是VDN中的简单和(Sunehag et al., 2017)。这种因子表示允许复杂的集中动作值函数和扩展性,使用线性时间单个argmax操作提取分散策略。
博弈论中的问题
Heinrich and Silver (2016)提出了一种神经虚拟自玩(NFSP),将虚拟自玩与深度强化学习相结合,在不具备先验领域知识的情况下,以一种可扩展的端到端方法学习不完全信息博弈的近似纳什均衡。NFSP是在两玩家零和博弈中评估的。在Leduc扑克中,NFSP方法接近纳什均衡,而常用的强化学习方法存在分歧。在《极限德州扑克》中,这是一款真实世界规模的不完美信息博弈,NFSP的表现类似于基于领域专长的最先进的超人算法。
Lanctot et al. (2017)观察到,独立的强化学习方法会将学习到的策略过度拟合其它智能体的策略,在该方法中每个智能体通过与环境交互进行学习,而不关注其它智能体。作者提出了policy-space response oracle (PSRO)及其近似的深度认知层次结构(DCH),使用深度强化学习计算策略组合的最佳响应,并利用经验博弈论分析计算新的元策略分布。PSRO/DCH推广了以前的算法,如独立强化学习、迭代最佳响应、double oracle和fictitious play。作者提出了对于分散执行的集中训练的一种实现,如下所述。作者用网格世界协调(一种部分可观察的游戏)和Leduc扑克(一种具有六副牌的不完全信息竞争游戏)进行了实验,结果表明联合策略相关性(JPC)降低,这是一种量化过度拟合效果的新指标。
社会困境,如囚徒困境,揭示了集体理性与个体理性之间的冲突。合作通常对所有人都有益。然而,搭便车等寄生行为可能导致公共的悲剧,使合作不稳定。矩阵博弈社会困境(MGSD)的形式主义是一种流行的研究方法。然而,正如Leibo et al. (2017)所讨论的,MGSD没有考虑现实世界社会困境的这几个重要方面: “合作与背叛是执行战略决策的策略标签”,“合作可以是一个分级的数量”。它们是暂时的长期合作,而叛变可能不会完全同时发生,因为一个参与者开始一项战略的信息会影响另一个参与者,而且,决策是强制性的,尽管只有关于世界和其他参与者的部分信息。
Leibo et al. (2017)提出了一个与MARL一起解决这些问题的序列社会困境(sequence social dilemma, SSD)。作者对采果和猎狼两种博弈进行了实证博弈论分析,结果表明,在MGSD中把合作和背叛作为一次性决策时,存在囚徒困境的经验收益矩阵。然而,聚集和狼群是两种不同的游戏,在合作的出现和稳定中表现出截然相反的行为。SSDs可以捕捉到这两款游戏的不同之处,利用一个因素来促进聚集中的合作,并阻止狼群中的合作。SSDs的序列结构导致了计算或学习均衡的复杂模型。作者提出将应用DQN寻找SSDs的平衡。
游戏
Jaderberg et al. (2018)的方法使用原始输入(包括像素和游戏分数)以端到端的方式玩夺旗游戏(第一人称3D多人视频游戏),并使用基于种群的训练、内部奖励的优化和时间分层的RL技术,首次实现了针对多智能体 RL问题人类水平的性能。
Jaderberg et al. (2018)提出训练不同类型的智能群体,形成相互竞争的两个团队,并且用分散的方式训练单个智能体,仅与环境进行交互,没有环境模型、其它智能体和人类先验策略的知识,不与其它智能体进行沟通。每个智能体学习一个内部的奖励信号,生成内部目标,如夺旗,以补充稀疏的游戏获胜奖励。作者提出了一个两层优化过程。内部优化最大化智能体预期的未来内部折扣奖励。外部优化求解元博弈,利用内部优化提供的元转移动力学,以最大化赢得比赛的元奖励。(w.r.t. internal reward functions and hyperparameters)。利用RL求解内部优化问题。采用基于种群的训练(PBT)解决外部优化问题(Jaderberg et al., 2017),这是一种适应内部奖励和超参数的在线进化方法,通过智能体突变进行模型选择,即用更好的智能体取代表现不佳的智能体。辅助信号(Jaderberg et al., 2017)和可微神经计算机内存(Graves et al.,2016)也被用来提高性能。RL智能体在随机生成映射的数千个并发匹配上进行异步地训练。
作者设计了一种学习与进化相结合的智能体,该智能体具有较强的能力,避免了几种常见的RL问题。从随机映射上的不同代理群体中学习有助于实现概括映射的可变性、玩家的数量、队友的选择以及部分可观察的多智能体环境的稳定性的技能。学习内部奖励信号有助于解决稀疏奖励问题和未来的的成绩分配问题。多时间尺度表示有助于记忆和高层次策略的长期时间推理。作者选择PBT而不是self play,因为self play在多代理RL环境中可能是不稳定的,需要更多的操作来支持并发训练,从而获得更好的可伸缩性。
实验表明,一个智能体可以学习一个与一些单个神经元激活相关的解纠缠的表示来编码游戏情境的各种知识,比如标志状态、重生状态和房间类型的连接,并且表现得像人类一样,例如导航、跟随和防御。这些知识是通过RL训练获得的,而不是通过确定的模型得到。实验还表明,由时间层次结构和显式内存模块产生的丰富的空间环境表示支持随机映射任务的可泛化能力。实验显示了人类的水平表现,而一项调查显示,这些智能体比人类参与者更具协作性。看来是可以用少于2000台商品计算机进行训练。
作者提到了当前工作的局限性:“维护智能群体多样性的困难,PBT执行的元优化的贪婪本质,以及RL更新中与时间成绩分配的差异”。 查看博客:https://deepmind.com/blog/capture-the-flag/
Sun et al. (2018) and Pang et al. (2018)在《星际争霸2》中击败了全游戏内置AI。OpenAI Five设计了一个针对5v5玩法的Dota2智能体,它采用了常见的RL算法:近端策略优化(PPO)和self play,并击败了人类玩家。然而,这涉及到大量的计算,256个GPU和128,000个CPU内核。见https://openai.com/five/















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









