







一. Why MADDPG?
多智能体层面传统的强化学习方法缺陷:
1、Q-learning无法适应环境不稳定的优化问题。即最优Q值会随着时间变化的问题,这会使Q-learning学习变得困难,此外环境的不稳定还会导致Q-learning的batch memory方法失效,进一步导致Deep Q Network的功能也变差。而在多智能体学习环境中,每次其他智能体的行为都是不同的,因此会造成环境不稳定
2、Policy-Gradient,在多智能体环境中,每个智能体的轨迹估计的梯度具有较高的相关性,即其他智能体的行为也会对特定智能体的结果产生影响,从而使梯度估计产生误差。(如果代理之间可交互,Policy Gradient还是可以用,但是交互计算量会随着代理数量变多而爆炸增长,一般来说,需要加入的参数是其他智能体的policy parameters。但是即使信息共享,也只是适用于在合作层面上的问题,在多智能体竞争层面表现很差)
二. Prerequisite in MADDPG
多传感器训练时的要求:
1、每个智能体最终的policy只能使用自己所能都获取到的信息(不能使用全局信息)
2、环境的动态性不可微分
3、学习过程中policy之间可以进行信息交互,但是该交互依然是不可微分的
三. How MADDPG
必须拿出那张著名的图:
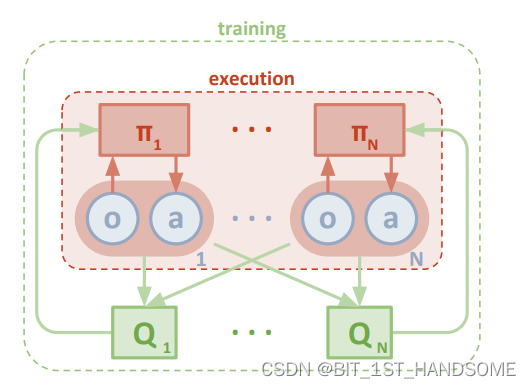
1、集中式训练,分布式执行:
集中式训练:在训练时,每个agent可以获取到除了自己所能观测到的信息的额外信息,包括其他agent的观测信息和行为。通过这种方式,agent就可以考虑到全局的状态。
分布式执行:在训练环节之后,每个agent智能通过自己的网络和自己的observation进行训练.
2、具体在Policy-Gradient上做的手脚
对于使用了Policy-Gradient的Actor,其里面参数的更新方法为:
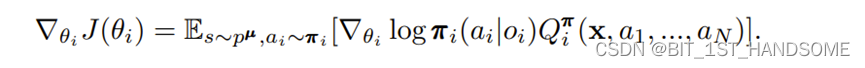
这里面和我们的Policy-Gradient唯一的区别在于,Policy-Gradient中直接就是一个Reward,但是这里的Q实际上是Critic相关的输出(td-error),并且这个输出和所有的智能体的行为,当前环境都是相关的,即,每个智能体都配备有一个专门负责其学习的Critic网络。当加入determine之后,该式子会变成:
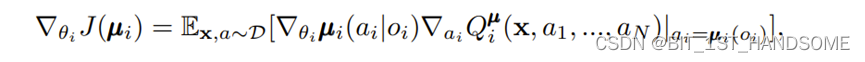
其实意思就是说,determine的网络不会再犹豫了,这里的第二个参数其实就是Critic的Eval网络传给Actor的Eval的参数。
此外,Critic网络的更新的机理和Q-Learning一样,毕竟Critic是以值为基础的嘛:
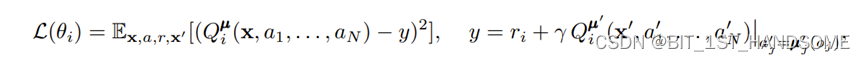
值得注意的是,从上式可见这个网络作为输入的参数是所有智能体的action,所有智能体观测值。Critic相当于是一个考虑了全局的指导网络。

















 9234
9234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









