






隐马尔可夫模型HMM
介绍了模型的基本知识,和三个基本问题。其中对概率计算问题和预测(解码)问题进行了详细分析,并提供了python代码实现
公众号关注 52DATA ,获得更多数据分析知识,感谢支持—>
文章目录
一、题目引入
假设有三个盒子,每个盒子里都装有红白两种颜色的球,盒子里的红白球数由下表1列出
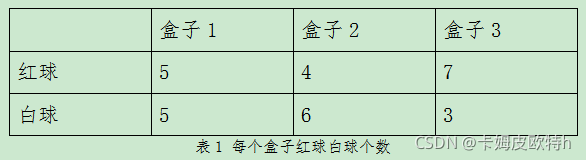
根据上表1,可以知道每次球出自于哪个盒子的概率,如表2:
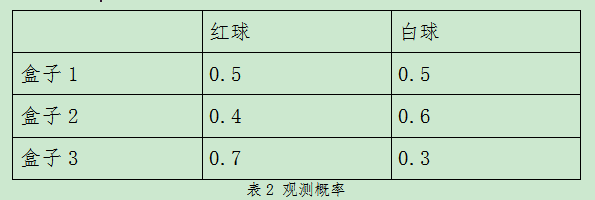
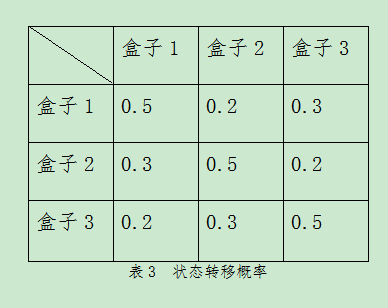
按照下面的方法抽球:开始,以(0.2,0.4,0.4)的概率随机选取 1 个盒子(假设已知,第一次在盒子1抽取球的概率为0.2,第一次在盒子2中抽取球的概率为0.4,第一次在盒子3中抽取球的概率为0.4),然后从这个盒子里随机抽出 1 个球,记录其颜色后,放回;然后,从当前盒子随机转移到下一个盒子(这个概率假设已知,如表3),继续抽球,放回…,但是这个过程不知道从哪个盒子里抽取的,只能看到球的颜色。
已知t时刻选择的盒子为a,下一刻选中盒子a,b,c的概率为:
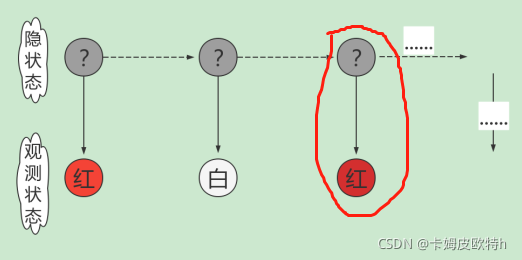
假设抽三次,抽取的结果为红球、白球、 红球,则该过程的流程图如下图:
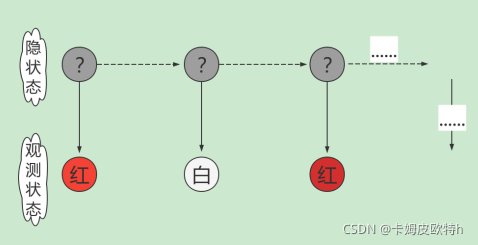
也就是我抽取完球之后,只能看到球的颜色,但我不知道球来自取哪里,于是上面的灰色叫为隐状态,下面叫为观测状态。上述过程就叫做隐马尔科夫模型(HMM)
二、隐马尔科夫的基本概念
1.隐状态集合Q和可观测状态集合V
Q是所有可能的状态的集合(隐状态集合)
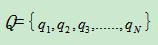 ,N是可能的状态数
,N是可能的状态数
V是所有可能的观测的集合(可观测状态集合)
 ,M是可能的观测数
,M是可能的观测数
注:集合里面的元素不能重复
2.状态序列I 和观测序列O
I 是长度为T 的状态序列,O 是对应的观测序列.
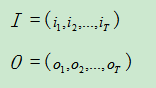
3.状态转移概率矩阵A

4.观测概率矩阵B

5.初始状态概率向量π
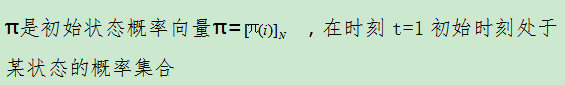
6.隐马尔科夫模型的三要素
隐马尔可夫模型由初始状态概率向量π、状态转移概率矩阵 A 和观测概率矩阵 B 决定.π和 A 决定状态序列,B 决定观测序列.因此,隐马尔可夫模型λ可以用三元符号表示,即λ=(A,B,π).A,B,π叫做隐马尔科夫模型的三要素。
7.隐马尔可夫模型的两个基本假设
(1)齐次马尔可夫性假设
即假设隐藏的马尔可夫链在任意时刻 t 的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻 t 无关.
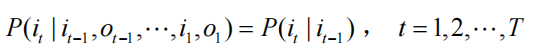
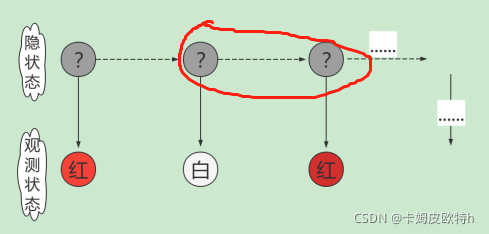
(2)观测独立性假设
即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关.
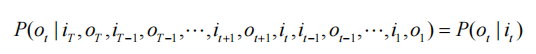
三、将第一个问题用符号表示
隐藏状态集合Q={盒子1,盒子2,盒子3},N=3
观测状态集合V={红,白},M=2

假设总共摸了三次球,依次是红球,白球,红球,则
观测序列O={红,白,红}
但状态序列I 是不固定的,可能的取值有27种
1: 盒子1-->盒子1-->盒子1
2: 盒子1-->盒子1-->盒子2
3: 盒子1-->盒子1-->盒子3
......
25: 盒子3-->盒子3-->盒子1
26: 盒子3-->盒子3-->盒子2
27: 盒子3-->盒子3-->盒子3
四、隐马尔科夫的三个基本问题

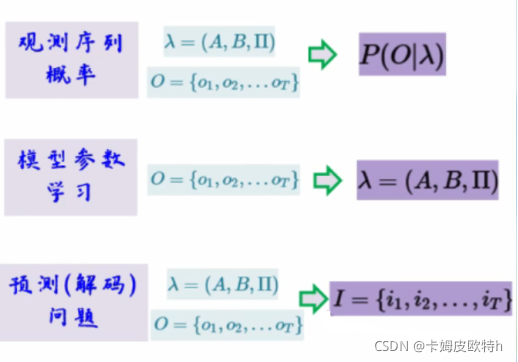
(一)概率计算问题(例题+代码实现)

1.直接计算

公式看的太难了,以我们的例子来看,实际上就是穷举出所有情况出现的概率求和
盒子1 --> 盒子1 --> 盒子1 0.2*0.5*0.5*0.5*0.5*0.5
盒子1 --> 盒子1 --> 盒子2 0.2*0.5*0.5*0.5*0.2*0.4
盒子1 --> 盒子1 --> 盒子3 0.2*0.5*0.5*0.5*0.3*0.7
盒子1 --> 盒子2 --> 盒子1 0.2*0.5*0.2*0.6*0.3*0.5
盒子1 --> 盒子2 --> 盒子2 0.2*0.5*0.2*0.6*0.5*0.4
盒子1 --> 盒子2 --> 盒子3 0.2*0.5*0.2*0.6*0.2*0.7
盒子1 --> 盒子3 --> 盒子1 0.2*0.5*0.3*0.3*0.2*0.5
盒子1 --> 盒子3 --> 盒子2 0.2*0.5*0.3*0.3*0.3*0.4
盒子1 --> 盒子3 --> 盒子3 0.2*0.5*0.3*0.3*0.5*0.7
盒子2 --> 盒子1 --> 盒子1 0.4*0.4*0.3*0.5*0.5*0.5
盒子2 --> 盒子1 --> 盒子2 0.4*0.4*0.3*0.5*0.2*0.4
盒子2 --> 盒子1 --> 盒子3 0.4*0.4*0.3*0.5*0.3*0.7
盒子2 --> 盒子2 --> 盒子1 0.4*0.4*0.5*0.6*0.3*0.5
盒子2 --> 盒子2 --> 盒子2 0.4*0.4*0.5*0.6*0.5*0.4
盒子2 --> 盒子2 --> 盒子3 0.4*0.4*0.5*0.6*0.2*0.7
盒子2 --> 盒子3 --> 盒子1 0.4*0.4*0.2*0.3*0.2*0.5
盒子2 --> 盒子3 --> 盒子2 0.4*0.4*0.2*0.3*0.3*0.4
盒子2 --> 盒子3 --> 盒子3 0.4*0.4*0.2*0.3*0.5*0.7
盒子3 --> 盒子1 --> 盒子1 0.4*0.7*0.2*0.5*0.5*0.5
盒子3 --> 盒子1 --> 盒子2 0.4*0.7*0.2*0.5*0.2*0.4
盒子3 --> 盒子1 --> 盒子3 0.4*0.7*0.2*0.5*0.3*0.7
盒子3 --> 盒子2 --> 盒子1 0.4*0.7*0.3*0.6*0.3*0.5
盒子3 --> 盒子2 --> 盒子2 0.4*0.7*0.3*0.6*0.5*0.4
盒子3 --> 盒子2 --> 盒子3 0.4*0.7*0.3*0.6*0.2*0.7
盒子3 --> 盒子3 --> 盒子1 0.4*0.7*0.5*0.3*0.2*0.5
盒子3 --> 盒子3 --> 盒子2 0.4*0.7*0.5*0.3*0.3*0.4
盒子3 --> 盒子3 --> 盒子3 0.4*0.7*0.5*0.3*0.5*0.7
以上式子求和P(O|λ)=0.130218
画两个流程图就能明白了
盒子1 --> 盒子1 --> 盒子1 :
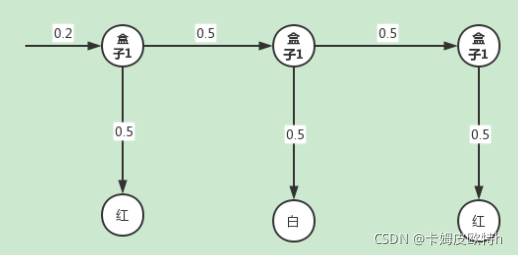
盒子2 --> 盒子1 --> 盒子3:
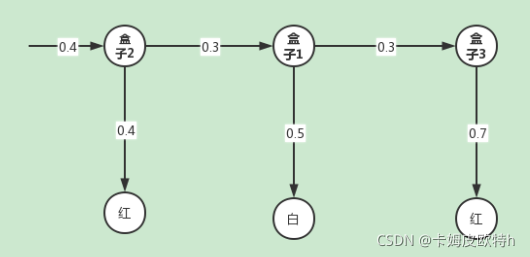
但是直接求解太麻烦了,需要穷举出所有的情况,所以一般采用前向算法或后向算法
Python代码实现–直接求法
A=np.array([[0.5,0.2,0.3],[0.3,0.5,0.2],[0.2,0.3,0.5]])
B=np.array([[0.5,0.5],[0.4,0.6],[0.7,0.3]])
pai=np.array([0.2,0.4,0.4])
sum=0
for i in range(len(Q)):
for j in range(len(Q)):
for k in range(len(Q)):
sum=sum+pai[i]*B[i][0]*A[i][j]*B[j][1]*A[j][k]*B[k][0]
#print(Q[i],"-->",Q[j],"-->",Q[k],("%s*%s*%s*%s*%s*%s ")%(pai[i],B[i][0],A[i][j],B[j][1],A[j][k],B[k][0]),pai[i]*B[i][0]*A[i][j]*B[j][1]*A[j][k]*B[k][0])
print(Q[i],"-->",Q[j],"-->",Q[k]," ",("%s*%s*%s*%s*%s*%s ")%(pai[i],B[i][0],A[i][j],B[j][1],A[j][k],B[k][0]))
print("P(O|λ)=",sum)
2.前向算法




python代码实现–前向算法
Q=["box1","box2","box3"]#状态集合
V=["红","白"] #观测集合
#O=["红","白","红"] #观测序列
O=[0,1,0] #转为数字类型,0代表红,1代表白
A=np.array([[0.5,0.2,0.3],[0.3,0.5,0.2],[0.2,0.3,0.5]])
B=np.array([[0.5,0.5],[0.4,0.6],[0.7,0.3]])
pai=np.array([0.2,0.4,0.4])
#前向算法
for i in range(len(O)):
if i==0:
pai=pai*B.T[O[i]] #初始状态概率
else:
pai=pai.dot(A)*B.T[O[i]] #之后的状态概率迭代
print(pai.sum())
3.后向算法



python代码实现–后向算法
Q=["box1","box2","box3"]#状态集合
V=["红","白"] #观测集合
#O=["红","白","红"] #观测序列
O=[0,1,0] #转为数字类型
A=np.array([[0.5,0.2,0.3],[0.3,0.5,0.2],[0.2,0.3,0.5]])
B=np.array([[0.5,0.5],[0.4,0.6],[0.7,0.3]])
pai=np.array([0.2,0.4,0.4])
#后向算法
for i in range(len(O),0):
if i==len(O):
pai1=np.array([1,1,1]) #t=3时刻
else:
pai1=A.dot(B.T[O[i]]*pai1)##之前的状态概率迭代
print((pai1*pai*B.T[0]).sum())#终止
(二)模型参数学习
学习问题

没有找到具体例子,若用到,再更新…
(三)预测(解码)问题(例题+代码实现)
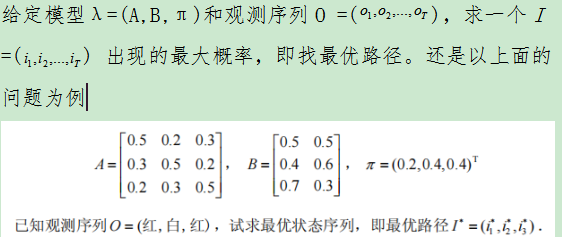
1.穷举
找出所有可能出现的情况,选择概率最大的一组
直接附代码
Q=["box1","box2","box3"]#状态集合
V=["红","白"] #观测集合
#O=["红","白","红"] #观测序列
O=[0,1,0] #转为数字类型
A=np.array([[0.5,0.2,0.3],[0.3,0.5,0.2],[0.2,0.3,0.5]])
B=np.array([[0.5,0.5],[0.4,0.6],[0.7,0.3]])
pai=np.array([0.2,0.4,0.4])
#暴力破解 穷举
sum=0
pathlist=[]#存路径
plist=[]#存概率
for i in range(len(Q)):
for j in range(len(Q)):
for k in range(len(Q)):
pathlist.append((i,j,k))
plist.append(pai[i]*B[i][0]*A[i][j]*B[j][1]*A[j][k]*B[k][0])
print((i,j,k),("%s*%s*%s*%s*%s*%s =")%(pai[i],B[i][0],A[i][j],B[j][1],A[j][k],B[k][0]),pai[i]*B[i][0]*A[i][j]*B[j][1]*A[j][k]*B[k][0])
#看概率最大的路径 则是最优
maxp=max(plist) #计算列表最大值
xb=plist.index(maxp)#取出最大值所对应的下标
print("最优路径为:",pathlist[xb])#输出最优解pathlist[xb]
print("最优路径对应概率为:",plist[xb])#输出最大概率p[xb]
输出

2.维特比viterbi算法
维特比算法实际是用动态规划解隐马尔可夫模型预测问题,即用动态规划(dynamic programming)求概率最大路径(最优路径).这时一条路径对应着一个状态序列.
定义两个变量:

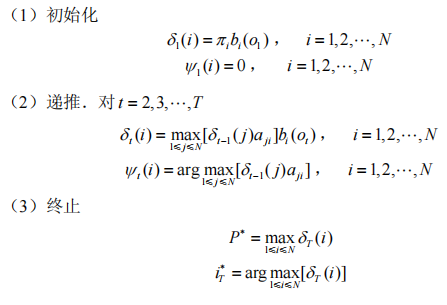

Python代码实现
Q=["box1","box2","box3"]#状态集合
V=["红","白"] #观测集合
#O=["红","白","红"] #观测序列
O=[0,1,0] #转为数字类型
A=np.array([[0.5,0.2,0.3],[0.3,0.5,0.2],[0.2,0.3,0.5]])
B=np.array([[0.5,0.5],[0.4,0.6],[0.7,0.3]])
pai=np.array([0.2,0.4,0.4])
#维特比viterbi算法
maxxb=[] #存φ,b-->δ
for i in range(len(O)):
if i==0:
b=pai*B.T[0]#t=1时刻概率
else:
maxxb.append(np.argmax(b*A.T,axis=1)) #返回最大值下标,axis=1每行最大,axis=0每列最大
b=np.max(b*A.T,axis=1)*B.T[O[i]] #迭代取最大值
#print(list(maxxb))
path=[]#最优路径
it=np.argmax(b,axis=0)#最优路径的“终点”
path.append(it)
for i in range(len(maxxb)):#最优路径回溯
it=maxxb[len(maxxb)-i-1][it]
path.append(it)
path.reverse()#把顺序调整一下,因为存的时候是倒着存储的
print(path)
输出
[2, 2, 2]



















 1861
1861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











