








正式开始前,请确保你已经完全清晰地理解了假设检验、Z分数、Z检验和置信区间的基本概念,若还有疑虑,这篇文章也许能帮到你,当然直接开始其实也没问题。
统计学(三):置信区间; Z 检验(样本平均数的假设检验), 均值分布, 附Python实现(大牌护肤品碧欧泉背后的秘密)
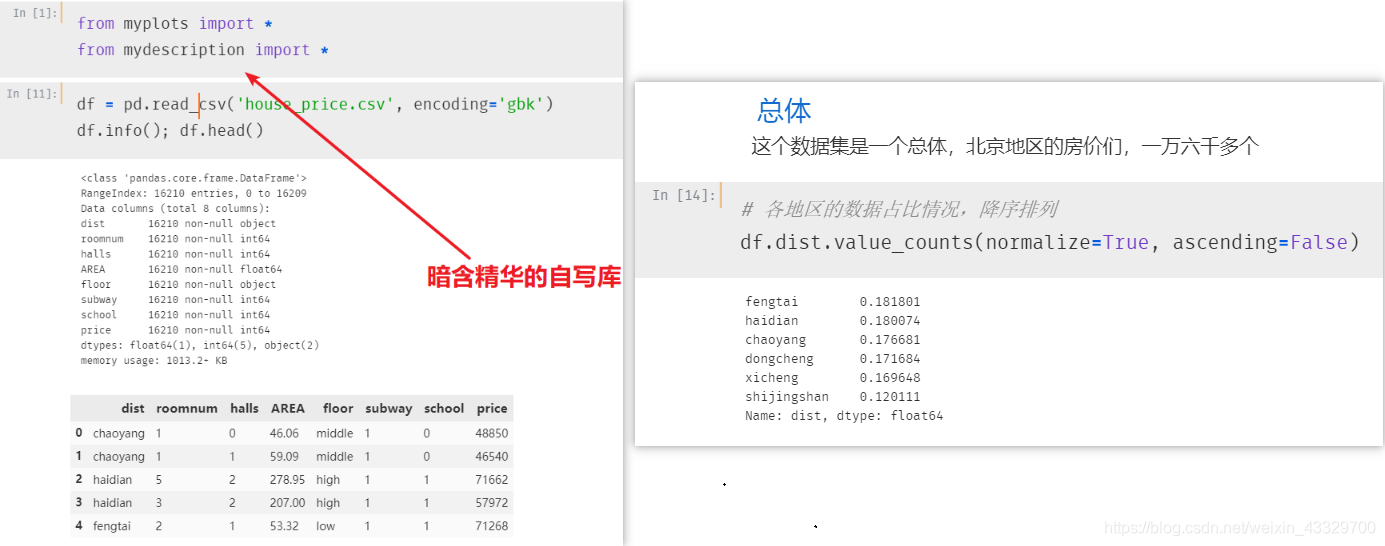
Python 逐步实现Z检验
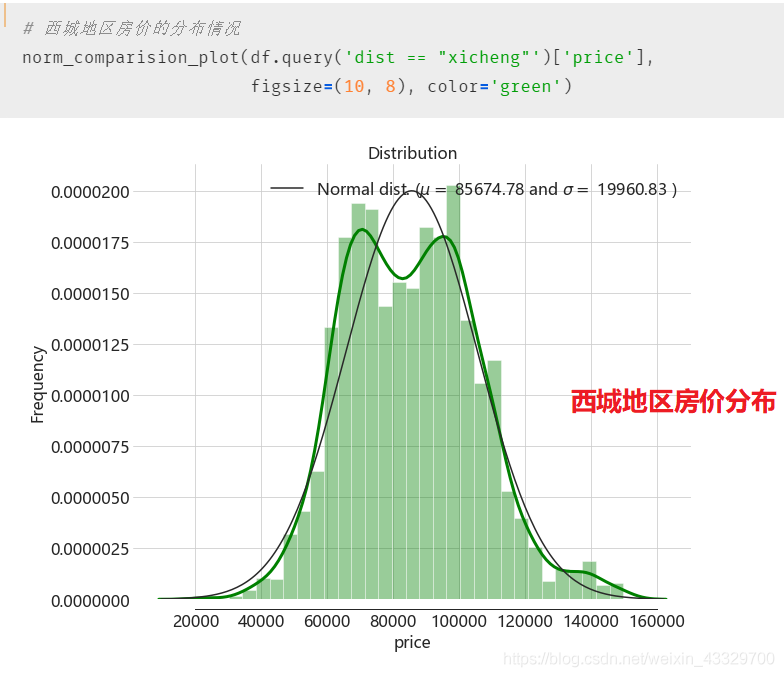
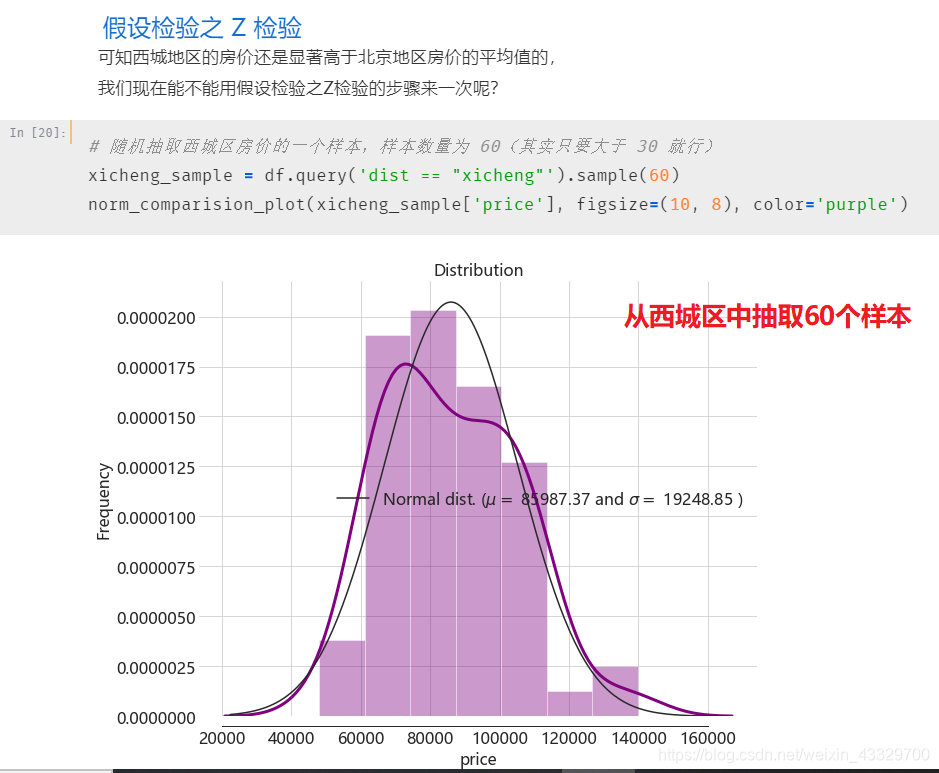
这里直接贴上读者 Jupyter Notebook 中的运行步骤流程,内涵精彩的可视化。
具体是怎么一步到位实现快捷且含有不少细节的可视化的,可见文末的延伸阅读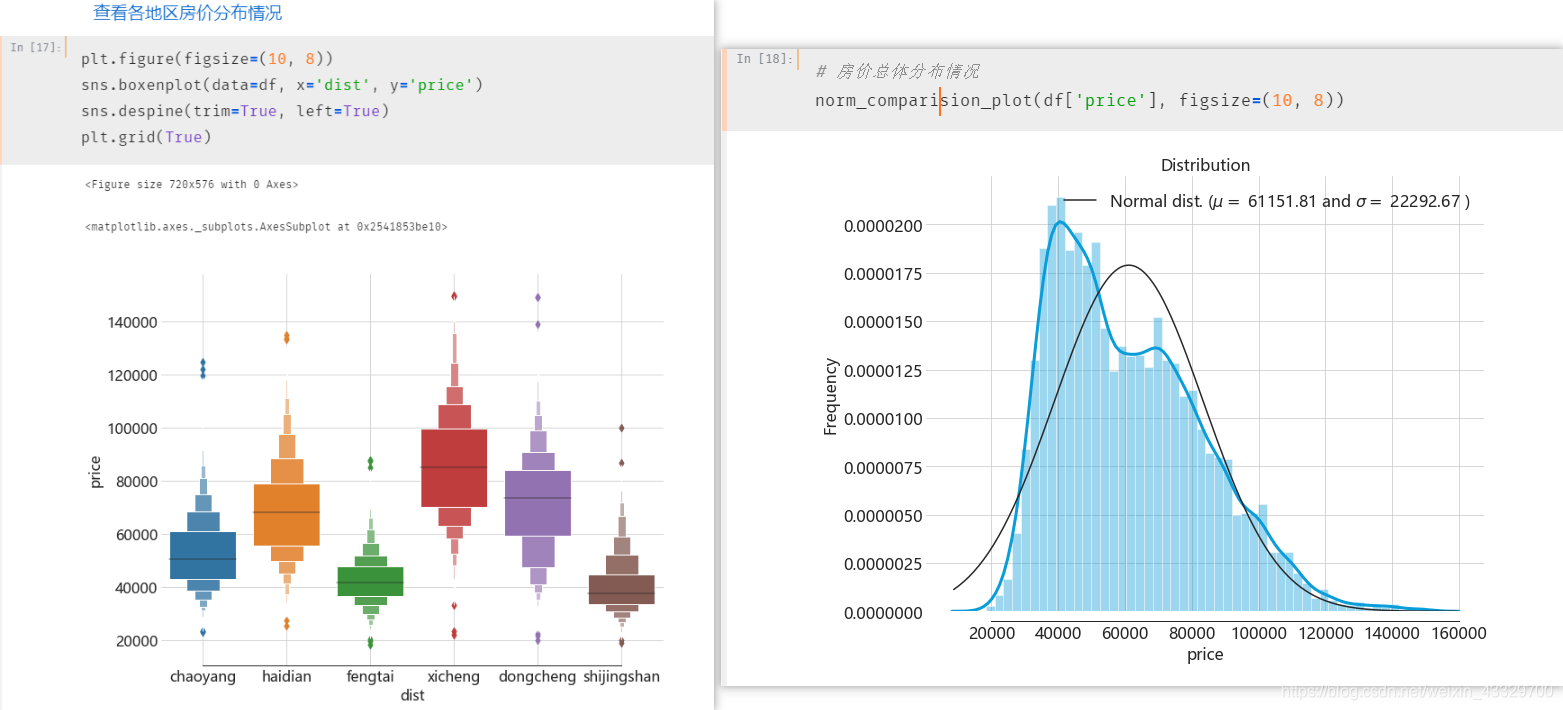

自定义 Z 检验函数
自定义置信区间函数
源代码呈现
可以直接放进自己写的库 mystatistic:我的专属统计学库,函数中的一些变量设置可能会过于冗长,这里只是方便阐述思路,可根据实际情况改装.
# 基础库
import numpy as np
import pandas as pd
# 提高输出效率库
from IPython.core.interactiveshell import InteractiveShell # 实现 notebook 的多行输出
InteractiveShell.ast_node_interactivity = 'all' #默认为'last'
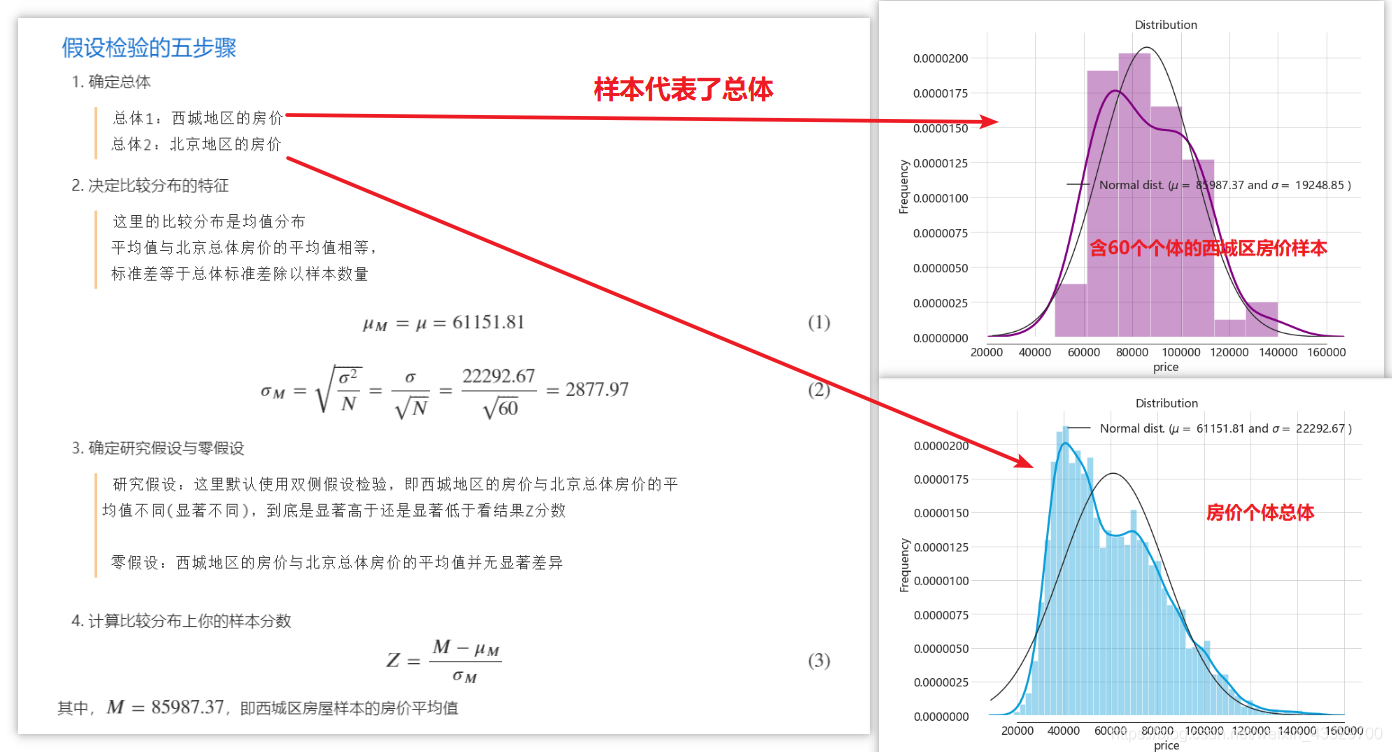
def z_test(sample, totality, alpha=0.05, size='double'):
""" 传入样本,总体,显著性水平,默认为双侧检验 """
N = len(sample) # N
sample_mean = np.mean(sample) # M
totality_mean = np.mean(totality) # mu_M
totality_std = np.std(totality) # sigma
sigma_m = totality_std / N**0.5 # sigma_M
z_score = (sample_mean - totality_mean) / sigma_m
return {'样本数 N': N, '样本均值 M': sample_mean,
'总体均值μ_m': totality_mean,
'总体标准差 σ': totality_std,
'均值分布的标准差 σ_m': sigma_m,
'Z 分数': z_score,
'上临界值': +1.96, '下临界值': -1.96}
if size == 'hemi': # 单侧检验
pass # 以后再自定义,先用着双侧的先
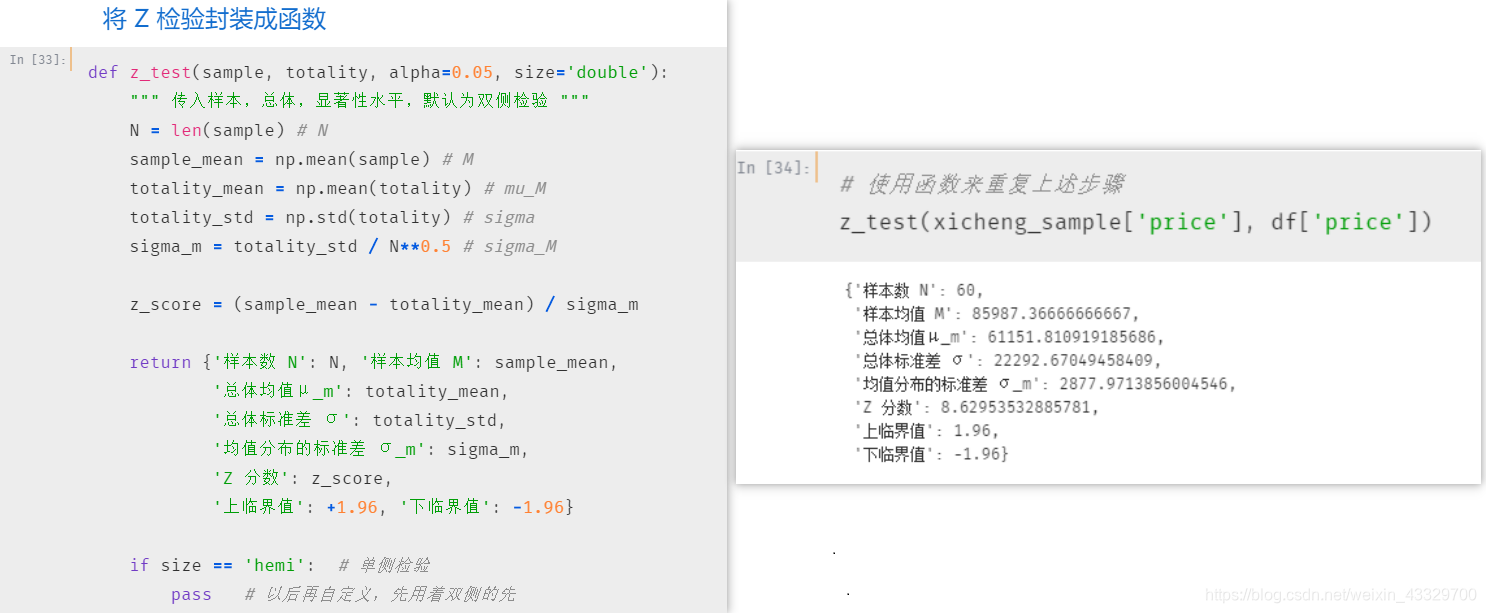
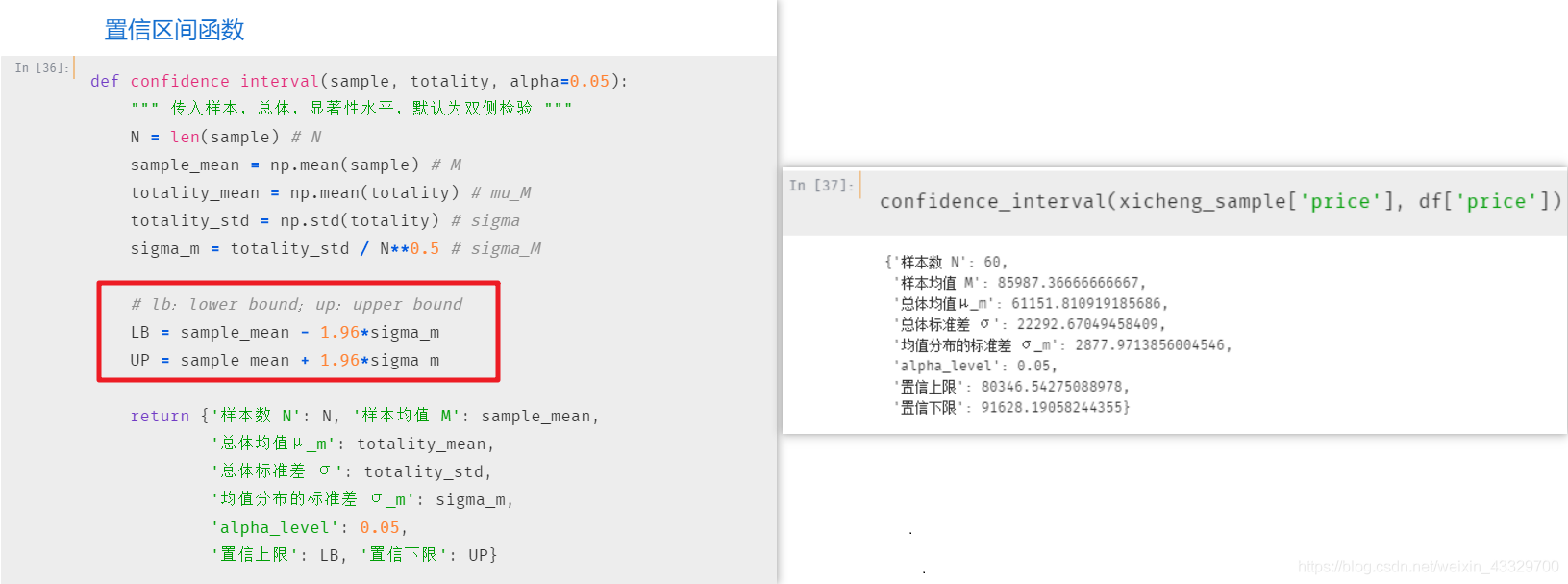
def confidence_interval(sample, totality, alpha=0.05):
""" 传入样本,总体,显著性水平,默认为双侧检验 """
N = len(sample) # N
sample_mean = np.mean(sample) # M
totality_mean = np.mean(totality) # mu_M
totality_std = np.std(totality) # sigma
sigma_m = totality_std / N**0.5 # sigma_M
# lb:lower bound;up:upper bound
LB = sample_mean - 1.96*sigma_m
UP = sample_mean + 1.96*sigma_m
return {'样本数 N': N, '样本均值 M': sample_mean,
'总体均值μ_m': totality_mean,
'总体标准差 σ': totality_std,
'均值分布的标准差 σ_m': sigma_m,
'alpha_level': 0.05,
'置信上限': LB, '置信下限': UP}
延伸阅读 & 精彩回顾
延伸阅读
-
Python 数据可视化:seaborn displot 正态分布曲线拟合图代码注释超详解(放入自写库,一行代码搞定复杂细节绘图)
-
Python 数据可视化:treemap 树形图 饼图升级版超详解,体现占比的同时显示出数量(放入自写库,一行代码搞定复杂细节绘图)
精彩回顾
-
统计学(三):置信区间; Z 检验(样本平均数的假设检验), 均值分布, 附Python实现(大牌护肤品碧欧泉背后的秘密)
-
Excel 还在重复输入相同的数据?不用那么麻烦(避免重复输入,批量填充 – 非手动输入与复制粘贴的快捷精准输入的方法)
数据分析,商业实践,数据可视化,网络爬虫,统计学,Excel,Word, 社会心理学,认知心理学,行为科学,民族意志学 各种专栏后续疯狂补充
欢迎评论与私信交流!















 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









