







上篇介绍了InceptionV3论文,指路:经典神经网络论文超详细解读(四)——InceptionV2-V3学习笔记(翻译+精读+代码复现)
本篇我们来复现一下InceptionV3代码
InceptionV1回顾:GoogLeNet InceptionV1代码复现+超详细注释(PyTorch)
第一步:定义基础卷积模块
卷积模块较上次多了BN层
BatchNorm2d()函数:
作用:卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
举例:
BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)1.num_features:一般输入参数的shape为batch_size*num_features*height*width,即为其中特征的数量,即为输入BN层的通道数;
2.eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5,避免分母为0;
3.momentum:一个用于运行过程中均值和方差的一个估计参数(可以理解是一个稳定系数,类似于SGD中的momentum的系数);
4.affine:当设为true时,会给定可以学习的系数矩阵gamma和beta
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
第二步:定义Inceptionv3模块
PyTorch提供的有六种基本的Inception模块,分别是InceptionA——InceptionE。
InceptionA
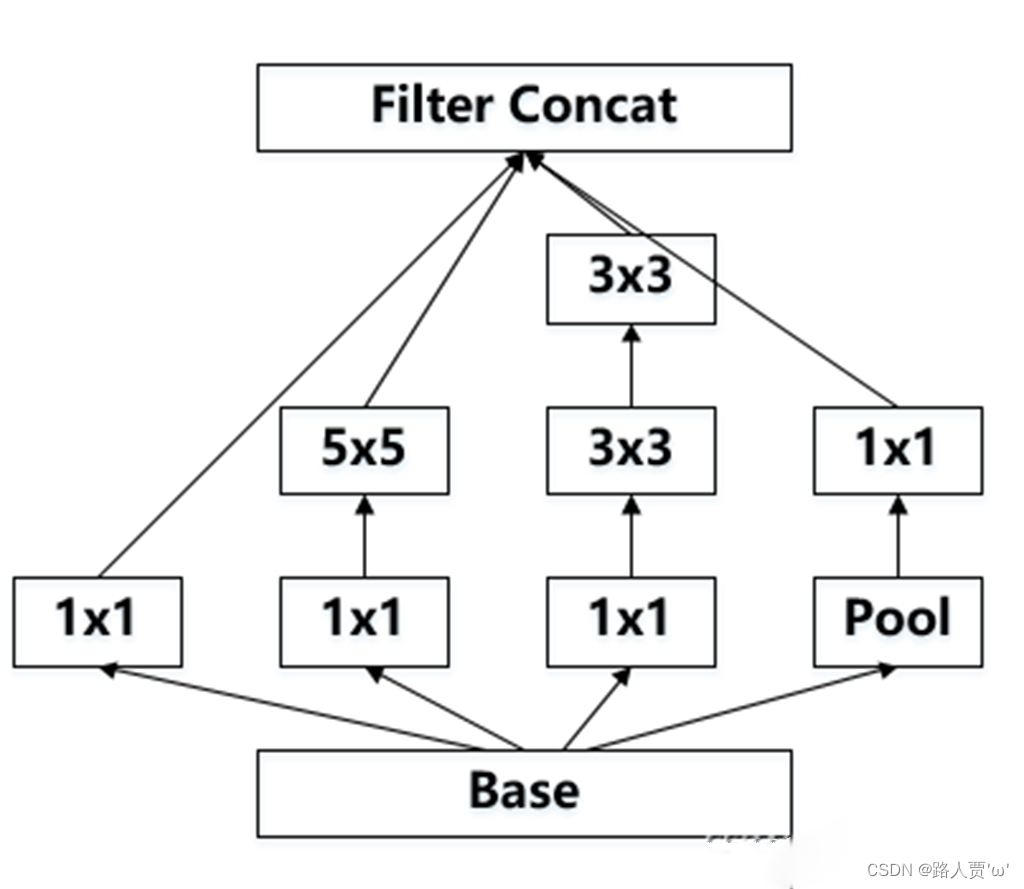
得到输入大小不变,通道数为224+pool_features的特征图。
假如输入为(35, 35, 192)的数据:
第一个branch:
经过branch1x1为带有64个1*1的卷积核,所以生成第一张特征图(35, 35, 64);
第二个branch:
首先经过branch5x5_1为带有48个1*1的卷积核,所以第二张特征图(35, 35, 48),
然后经过branch5x5_2为带有64个5*5大小且填充为2的卷积核,特征图大小依旧不变,因此第二张特征图最终为(35, 35, 64);
第三个branch:
首先经过branch3x3dbl_1为带有64个1*1的卷积核,所以第三张特征图(35, 35, 64),
然后经过branch3x3dbl_2为带有96个3*3大小且填充为1的卷积核,特征图大小依旧不变,因此进一步生成第三张特征图(35, 35, 96),
最后经过branch3x3dbl_3为带有96个3*3大小且填充为1的卷积核,特征图大小和通道数不变,因此第三张特征图最终为(35, 35, 96);
第四个branch:
首先经过avg_pool2d,其中池化核3*3,步长为1,填充为1,所以第四张特征图大小不变,通道数不变,第四张特征图为(35, 35, 192),
然后经过branch_pool为带有pool_features个的1*1卷积,因此第四张特征图最终为(35, 35, pool_features);
最后将四张特征图进行拼接,最终得到(35,35,64+64+96+pool_features)的特征图。
'''---InceptionA---'''
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features, conv_block=None):
super(InceptionA, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 64, kernel_size=1)
self.branch5x5_1 = conv_block(in_channels, 48, kernel_size=1)
self.branch5x5_2 = conv_block(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, padding=1)
self.branch_pool = conv_block(in_channels, pool_features, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
InceptionB
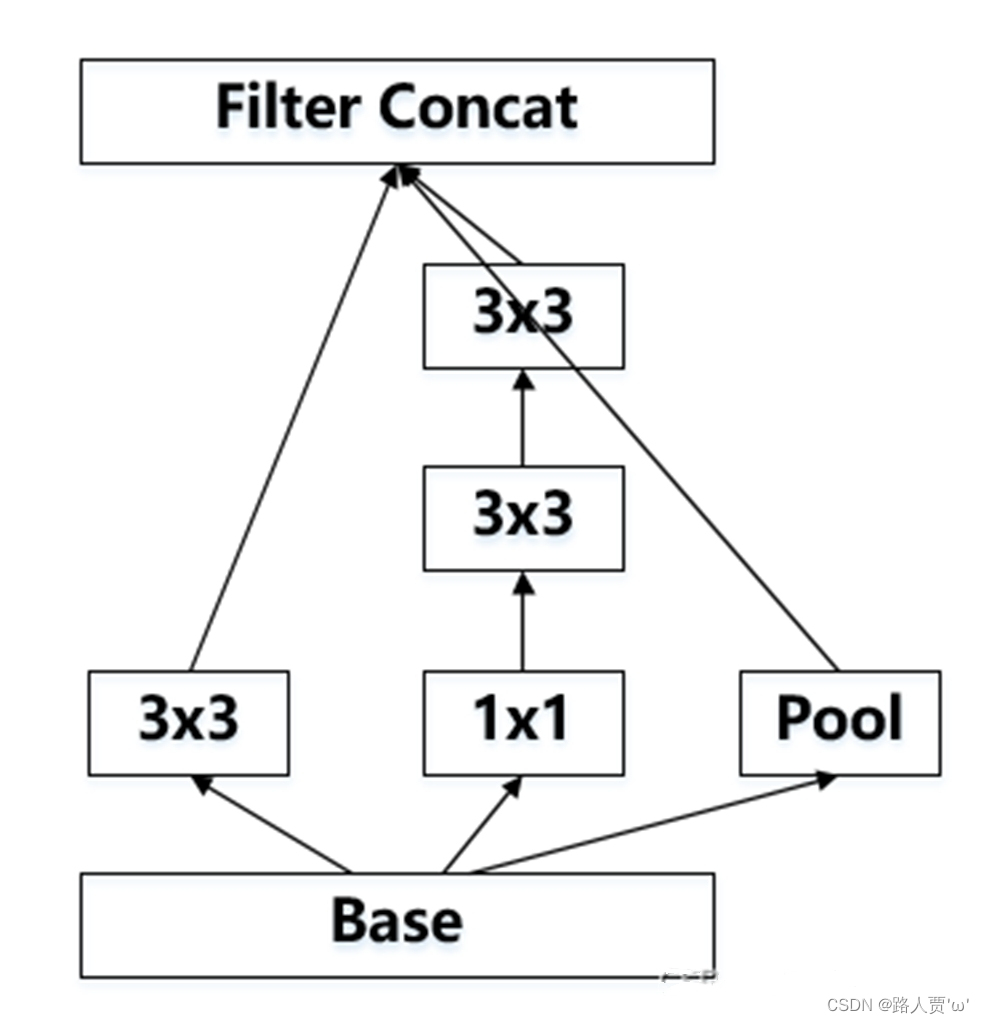
得到输入大小减半,通道数为480的特征图,
假如输入为(35, 35, 288)的数据:
第一个branch:
经过branch1x1为带有384个3*3大小且步长2的卷积核,(35-3+2*0)/2+1=17所以生成第一张特征图(17, 17, 384);
第二个branch:
首先经过branch3x3dbl_1为带有64个1*1的卷积核,特征图大小不变,即(35, 35, 64);
然后经过branch3x3dbl_2为带有96个3*3大小填充1的卷积核,特征图大小不变,即(35, 35, 96),
再经过branch3x3dbl_3为带有96个3*3大小步长2的卷积核,(35-3+2*0)/2+1=17,即第二张特征图为(17, 17, 96);
第三个branch:
经过max_pool2d,池化核大小3*3,步长为2,所以是二倍最大值下采样,通道数保持不变,第三张特征图为(17, 17, 288);
最后将三张特征图进行拼接,最终得到(17(即Hin/2),17(即Win/2),384+96+288(Cin)=768)的特征图。
'''---InceptionB---'''
class InceptionB(nn.Module):
def __init__(self, in_channels, conv_block=None):
super(InceptionB, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch3x3 = conv_block(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, stride=2)
def _forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
InceptionC
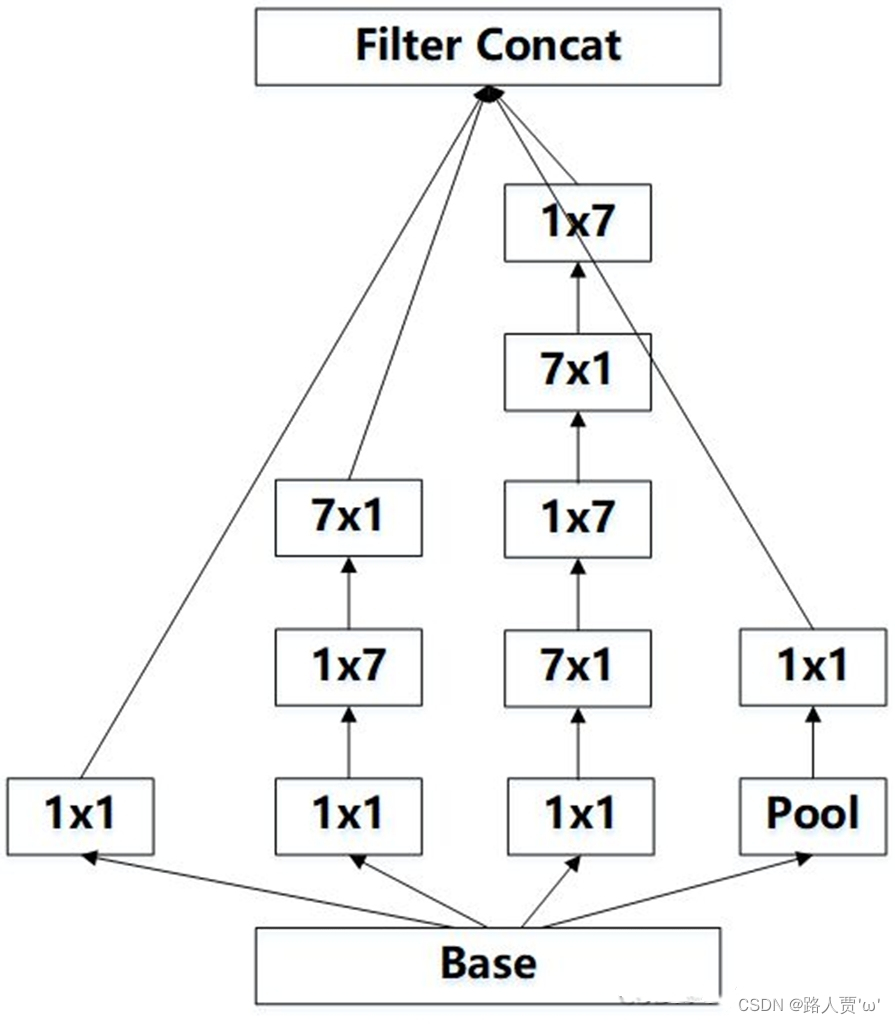
得到输入大小不变,通道数为768的特征图。
假如输入为(17,17, 768)的数据:
第一个branch:
首先经过branch1x1为带有192个1*1的卷积核,所以生成第一张特征图(17,17, 192);
第二个branch:
首先经过branch7x7_1为带有c7个1*1的卷积核,所以第二张特征图(17,17, c7),
然后经过branch7x7_2为带有c7个1*7大小且填充为0*3的卷积核,特征图大小不变,进一步生成第二张特征图(17,17, c7),
然后经过branch7x7_3为带有192个7*1大小且填充为3*0的卷积核,特征图大小不变,进一步生成第二张特征图(17,17, 192),因此第二张特征图最终为(17,17, 192);
第三个branch:
首先经过branch7x7dbl_1为带有c7个1*1的卷积核,所以第三张特征图(17,17, c7),
然后经过branch7x7dbl_2为带有c7个7*1大小且填充为3*0的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, c7),
然后经过branch7x7dbl_3为带有c7个1*7大小且填充为0*3的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, c7),
然后经过branch7x7dbl_4为带有c7个7*1大小且填充为3*0的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, c7),
然后经过branch7x7dbl_5为带有192个1*7大小且填充为0*3的卷积核,特征图大小不变,因此第二张特征图最终为(17,17, 192);
第四个branch:
首先经过avg_pool2d,其中池化核3*3,步长为1,填充为1,所以第四张特征图大小不变,通道数不变,第四张特征图为(17,17, 768),
然后经过branch_pool为带有192个的1*1卷积,因此第四张特征图最终为(17,17, 192);
最后将四张特征图进行拼接,最终得到(17, 17, 192+192+192+192=768)的特征图。
'''---InceptionC---'''
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7, conv_block=None):
super(InceptionC, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = conv_block(in_channels, c7, kernel_size=1)
self.branch7x7_2 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = conv_block(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = conv_block(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = conv_block(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = conv_block(in_channels, 192, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)InceptionD
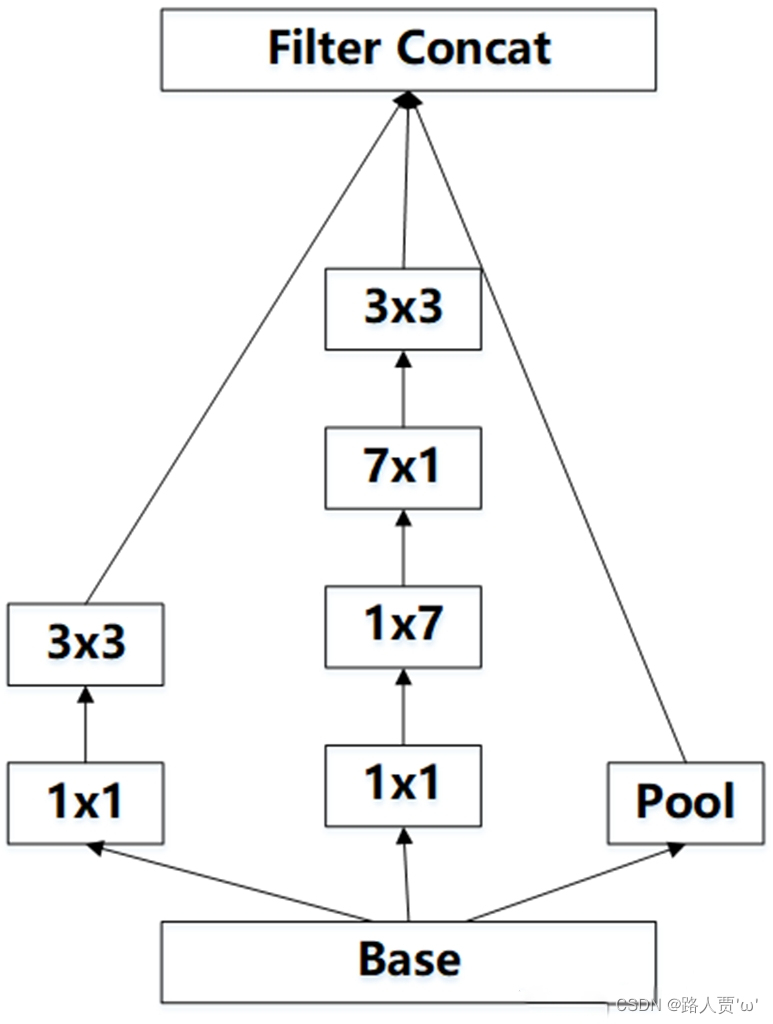
得到输入大小减半,通道数512的特征图,
假如输入为(17, 17, 768)的数据:
第一个branch:
首先经过branch3x3_1为带有192个1*1的卷积核,所以生成第一张特征图(17, 17, 192);
然后经过branch3x3_2为带有320个3*3大小步长为2的卷积核,(17-3+2*0)/2+1=8,最终第一张特征图(8, 8, 320);
第二个branch:
首先经过branch7x7x3_1为带有192个1*1的卷积核,特征图大小不变,即(17, 17, 192);
然后经过branch7x7x3_2为带有192个1*7大小且填充为0*3的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, 192);
再经过branch7x7x3_3为带有192个7*1大小且填充为3*0的卷积核,特征图大小不变,进一步生成第三张特征图(17,17, 192);
最后经过branch7x7x3_4为带有192个3*3大小步长为2的卷积核,最终第一张特征图(8, 8, 192);
第三个branch:
首先经过max_pool2d,池化核大小3*3,步长为2,所以是二倍最大值下采样,通道数保持不变,第三张特征图为(8, 8, 768);
最后将三张特征图进行拼接,最终得到(8(即Hin/2),8(即Win/2),320+192+768(Cin)=1280)的特征图。
'''---InceptionD---'''
class InceptionD(nn.Module):
def __init__(self, in_channels, conv_block=None):
super(InceptionD, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch3x3_1 = conv_block(in_channels, 192, kernel_size=1)
self.branch3x3_2 = conv_block(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = conv_block(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = conv_block(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = conv_block(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = conv_block(192, 192, kernel_size=3, stride=2)
def _forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)InceptionE
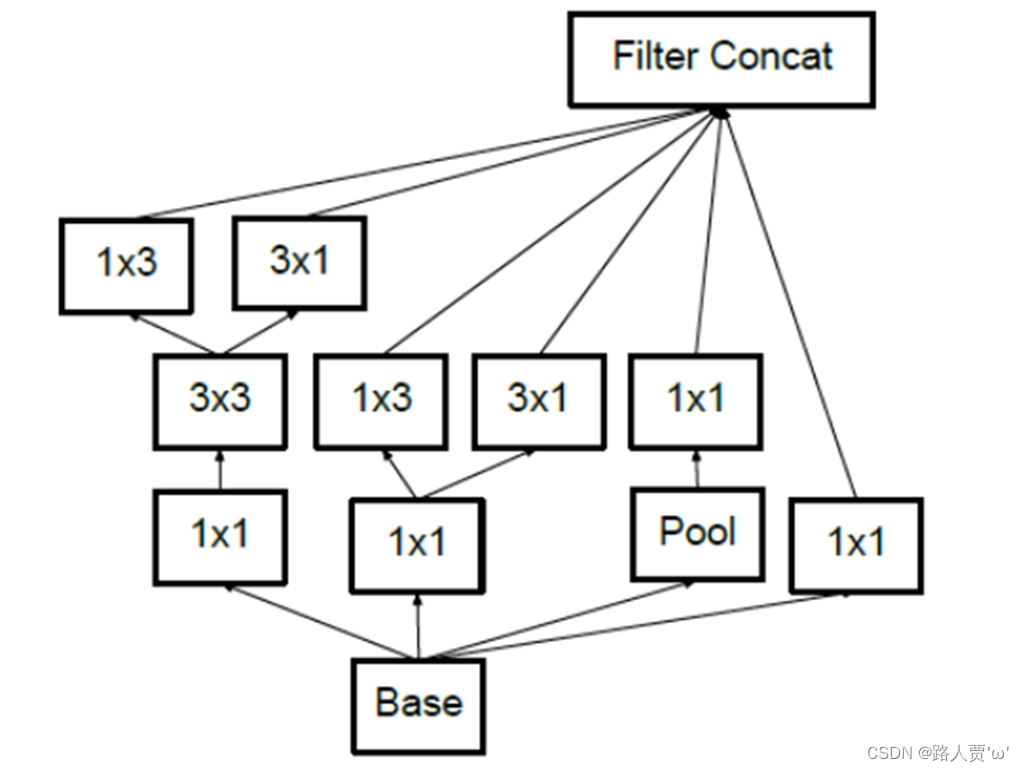
最终得到输入大小不变,通道数为2048的特征图。
假如输入为(8,8, 1280)的数据:
第一个branch:
首先经过branch1x1为带有320个1*1的卷积核,所以生成第一张特征图(8, 8, 320);
第二个branch:
首先经过branch3x3_1为带有384个1*1的卷积核,所以第二张特征图(8, 8, 384),
经过分支branch3x3_2a为带有384个1*3大小且填充为0*1的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
经过分支branch3x3_2b为带有192个3*1大小且填充为1*0的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
因此第二张特征图最终为两个分支拼接(8,8, 384+384=768);
第三个branch:
首先经过branch3x3dbl_1为带有448个1*1的卷积核,所以第三张特征图(8,8, 448),
然后经过branch3x3dbl_2为带有384个3*3大小且填充为1的卷积核,特征图大小不变,进一步生成第三张特征图(8,8, 384),
经过分支branch3x3dbl_3a为带有384个1*3大小且填充为0*1的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
经过分支branch3x3dbl_3b为带有384个3*1大小且填充为1*0的卷积核,特征图大小不变,进一步生成特征图(8,8, 384),
因此第三张特征图最终为两个分支拼接(8,8, 384+384=768);
第四个branch:
首先经过avg_pool2d,其中池化核3*3,步长为1,填充为1,所以第四张特征图大小不变,通道数不变,第四张特征图为(8,8, 1280),
然后经过branch_pool为带有192个的1*1卷积,因此第四张特征图最终为(8,8, 192);
最后将四张特征图进行拼接,最终得到(8, 8, 320+768+768+192=2048)的特征图。
'''---InceptionE---'''
class InceptionE(nn.Module):
def __init__(self, in_channels, conv_block=None):
super(InceptionE, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 320, kernel_size=1)
self.branch3x3_1 = conv_block(in_channels, 384, kernel_size=1)
self.branch3x3_2a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = conv_block(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = conv_block(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = conv_block(in_channels, 192, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)第三步:定义辅助分类器InceptionAux
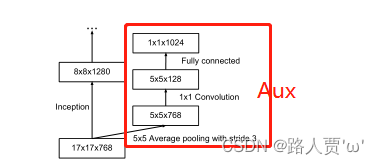
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes, conv_block=None):
super(InceptionAux, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.conv0 = conv_block(in_channels, 128, kernel_size=1)
self.conv1 = conv_block(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
# N x 768 x 17 x 17
x = F.avg_pool2d(x, kernel_size=5, stride=3)
# N x 768 x 5 x 5
x = self.conv0(x)
# N x 128 x 5 x 5
x = self.conv1(x)
# N x 768 x 1 x 1
# Adaptive average pooling
x = F.adaptive_avg_pool2d(x, (1, 1))
# N x 768 x 1 x 1
x = torch.flatten(x, 1)
# N x 768
x = self.fc(x)
# N x 1000
return x第四步:搭建GoogLeNet网络
'''-----------------------搭建GoogLeNet网络--------------------------'''
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, transform_input=False,
inception_blocks=None):
super(GoogLeNet, self).__init__()
if inception_blocks is None:
inception_blocks = [
BasicConv2d, InceptionA, InceptionB, InceptionC,
InceptionD, InceptionE, InceptionAux
]
assert len(inception_blocks) == 7
conv_block = inception_blocks[0]
inception_a = inception_blocks[1]
inception_b = inception_blocks[2]
inception_c = inception_blocks[3]
inception_d = inception_blocks[4]
inception_e = inception_blocks[5]
inception_aux = inception_blocks[6]
self.aux_logits = aux_logits
self.transform_input = transform_input
self.Conv2d_1a_3x3 = conv_block(3, 32, kernel_size=3, stride=2)
self.Conv2d_2a_3x3 = conv_block(32, 32, kernel_size=3)
self.Conv2d_2b_3x3 = conv_block(32, 64, kernel_size=3, padding=1)
self.Conv2d_3b_1x1 = conv_block(64, 80, kernel_size=1)
self.Conv2d_4a_3x3 = conv_block(80, 192, kernel_size=3)
self.Mixed_5b = inception_a(192, pool_features=32)
self.Mixed_5c = inception_a(256, pool_features=64)
self.Mixed_5d = inception_a(288, pool_features=64)
self.Mixed_6a = inception_b(288)
self.Mixed_6b = inception_c(768, channels_7x7=128)
self.Mixed_6c = inception_c(768, channels_7x7=160)
self.Mixed_6d = inception_c(768, channels_7x7=160)
self.Mixed_6e = inception_c(768, channels_7x7=192)
if aux_logits:
self.AuxLogits = inception_aux(768, num_classes)
self.Mixed_7a = inception_d(768)
self.Mixed_7b = inception_e(1280)
self.Mixed_7c = inception_e(2048)
self.fc = nn.Linear(2048, num_classes)
'''输入(229,229,3)的数据,首先归一化输入,经过5个卷积,2个最大池化层。'''
def _forward(self, x):
# N x 3 x 299 x 299
x = self.Conv2d_1a_3x3(x)
# N x 32 x 149 x 149
x = self.Conv2d_2a_3x3(x)
# N x 32 x 147 x 147
x = self.Conv2d_2b_3x3(x)
# N x 64 x 147 x 147
x = F.max_pool2d(x, kernel_size=3, stride=2)
# N x 64 x 73 x 73
x = self.Conv2d_3b_1x1(x)
# N x 80 x 73 x 73
x = self.Conv2d_4a_3x3(x)
# N x 192 x 71 x 71
x = F.max_pool2d(x, kernel_size=3, stride=2)
'''然后经过3个InceptionA结构,
1个InceptionB,3个InceptionC,1个InceptionD,2个InceptionE,
其中InceptionA,辅助分类器AuxLogits以经过最后一个InceptionC的输出为输入。'''
# 35 x 35 x 192
x = self.Mixed_5b(x) # InceptionA(192, pool_features=32)
# 35 x 35 x 256
x = self.Mixed_5c(x) # InceptionA(256, pool_features=64)
# 35 x 35 x 288
x = self.Mixed_5d(x) # InceptionA(288, pool_features=64)
# 35 x 35 x 288
x = self.Mixed_6a(x) # InceptionB(288)
# 17 x 17 x 768
x = self.Mixed_6b(x) # InceptionC(768, channels_7x7=128)
# 17 x 17 x 768
x = self.Mixed_6c(x) # InceptionC(768, channels_7x7=160)
# 17 x 17 x 768
x = self.Mixed_6d(x) # InceptionC(768, channels_7x7=160)
# 17 x 17 x 768
x = self.Mixed_6e(x) # InceptionC(768, channels_7x7=192)
# 17 x 17 x 768
if self.training and self.aux_logits:
aux = self.AuxLogits(x) # InceptionAux(768, num_classes)
# 17 x 17 x 768
x = self.Mixed_7a(x) # InceptionD(768)
# 8 x 8 x 1280
x = self.Mixed_7b(x) # InceptionE(1280)
# 8 x 8 x 2048
x = self.Mixed_7c(x) # InceptionE(2048)
'''进入分类部分。
经过平均池化层+dropout+打平+全连接层输出'''
x = F.adaptive_avg_pool2d(x, (1, 1))
# N x 2048 x 1 x 1
x = F.dropout(x, training=self.training)
# N x 2048 x 1 x 1
x = torch.flatten(x, 1)#Flatten()就是将2D的特征图压扁为1D的特征向量,是展平操作,进入全连接层之前使用,类才能写进nn.Sequential
# N x 2048
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux
def forward(self, x):
x, aux = self._forward(x)
return x, aux第五步*:网络结构参数初始化
'''-----------------------网络结构参数初始化--------------------------'''
# 目的:使网络更好收敛,准确率更高
def _initialize_weights(self): # 将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。
# 遍历网络中的每一层
for m in self.modules():
# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True
'''如果是卷积层Conv2d'''
if isinstance(m, nn.Conv2d):
# Kaiming正态分布方式的权重初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
'''判断是否有偏置:'''
# 如果偏置不是0,将偏置置成0,对偏置进行初始化
if m.bias is not None:
# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数val
nn.init.constant_(m.bias, 0)
'''如果是全连接层'''
elif isinstance(m, nn.Linear):
# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量
# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)实现效果
完整代码
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
'''-------------------------第一步:定义基础卷积模块-------------------------------'''
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
'''-----------------第二步:定义Inceptionv3模块---------------------'''
'''---InceptionA---'''
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features, conv_block=None):
super(InceptionA, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 64, kernel_size=1)
self.branch5x5_1 = conv_block(in_channels, 48, kernel_size=1)
self.branch5x5_2 = conv_block(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, padding=1)
self.branch_pool = conv_block(in_channels, pool_features, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
'''---InceptionB---'''
class InceptionB(nn.Module):
def __init__(self, in_channels, conv_block=None):
super(InceptionB, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch3x3 = conv_block(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, stride=2)
def _forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
'''---InceptionC---'''
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7, conv_block=None):
super(InceptionC, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = conv_block(in_channels, c7, kernel_size=1)
self.branch7x7_2 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = conv_block(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = conv_block(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = conv_block(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = conv_block(in_channels, 192, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
'''---InceptionD---'''
class InceptionD(nn.Module):
def __init__(self, in_channels, conv_block=None):
super(InceptionD, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch3x3_1 = conv_block(in_channels, 192, kernel_size=1)
self.branch3x3_2 = conv_block(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = conv_block(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = conv_block(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = conv_block(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = conv_block(192, 192, kernel_size=3, stride=2)
def _forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
'''---InceptionE---'''
class InceptionE(nn.Module):
def __init__(self, in_channels, conv_block=None):
super(InceptionE, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 320, kernel_size=1)
self.branch3x3_1 = conv_block(in_channels, 384, kernel_size=1)
self.branch3x3_2a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = conv_block(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = conv_block(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = conv_block(in_channels, 192, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
'''-------------------第三步:定义辅助分类器InceptionAux-----------------------'''
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes, conv_block=None):
super(InceptionAux, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.conv0 = conv_block(in_channels, 128, kernel_size=1)
self.conv1 = conv_block(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
# N x 768 x 17 x 17
x = F.avg_pool2d(x, kernel_size=5, stride=3)
# N x 768 x 5 x 5
x = self.conv0(x)
# N x 128 x 5 x 5
x = self.conv1(x)
# N x 768 x 1 x 1
# Adaptive average pooling
x = F.adaptive_avg_pool2d(x, (1, 1))
# N x 768 x 1 x 1
x = torch.flatten(x, 1)
# N x 768
x = self.fc(x)
# N x 1000
return x
'''-----------------------第四步:搭建GoogLeNet网络--------------------------'''
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, transform_input=False,
inception_blocks=None):
super(GoogLeNet, self).__init__()
if inception_blocks is None:
inception_blocks = [
BasicConv2d, InceptionA, InceptionB, InceptionC,
InceptionD, InceptionE, InceptionAux
]
assert len(inception_blocks) == 7
conv_block = inception_blocks[0]
inception_a = inception_blocks[1]
inception_b = inception_blocks[2]
inception_c = inception_blocks[3]
inception_d = inception_blocks[4]
inception_e = inception_blocks[5]
inception_aux = inception_blocks[6]
self.aux_logits = aux_logits
self.transform_input = transform_input
self.Conv2d_1a_3x3 = conv_block(3, 32, kernel_size=3, stride=2)
self.Conv2d_2a_3x3 = conv_block(32, 32, kernel_size=3)
self.Conv2d_2b_3x3 = conv_block(32, 64, kernel_size=3, padding=1)
self.Conv2d_3b_1x1 = conv_block(64, 80, kernel_size=1)
self.Conv2d_4a_3x3 = conv_block(80, 192, kernel_size=3)
self.Mixed_5b = inception_a(192, pool_features=32)
self.Mixed_5c = inception_a(256, pool_features=64)
self.Mixed_5d = inception_a(288, pool_features=64)
self.Mixed_6a = inception_b(288)
self.Mixed_6b = inception_c(768, channels_7x7=128)
self.Mixed_6c = inception_c(768, channels_7x7=160)
self.Mixed_6d = inception_c(768, channels_7x7=160)
self.Mixed_6e = inception_c(768, channels_7x7=192)
if aux_logits:
self.AuxLogits = inception_aux(768, num_classes)
self.Mixed_7a = inception_d(768)
self.Mixed_7b = inception_e(1280)
self.Mixed_7c = inception_e(2048)
self.fc = nn.Linear(2048, num_classes)
'''输入(229,229,3)的数据,首先归一化输入,经过5个卷积,2个最大池化层。'''
def _forward(self, x):
# N x 3 x 299 x 299
x = self.Conv2d_1a_3x3(x)
# N x 32 x 149 x 149
x = self.Conv2d_2a_3x3(x)
# N x 32 x 147 x 147
x = self.Conv2d_2b_3x3(x)
# N x 64 x 147 x 147
x = F.max_pool2d(x, kernel_size=3, stride=2)
# N x 64 x 73 x 73
x = self.Conv2d_3b_1x1(x)
# N x 80 x 73 x 73
x = self.Conv2d_4a_3x3(x)
# N x 192 x 71 x 71
x = F.max_pool2d(x, kernel_size=3, stride=2)
'''然后经过3个InceptionA结构,
1个InceptionB,3个InceptionC,1个InceptionD,2个InceptionE,
其中InceptionA,辅助分类器AuxLogits以经过最后一个InceptionC的输出为输入。'''
# 35 x 35 x 192
x = self.Mixed_5b(x) # InceptionA(192, pool_features=32)
# 35 x 35 x 256
x = self.Mixed_5c(x) # InceptionA(256, pool_features=64)
# 35 x 35 x 288
x = self.Mixed_5d(x) # InceptionA(288, pool_features=64)
# 35 x 35 x 288
x = self.Mixed_6a(x) # InceptionB(288)
# 17 x 17 x 768
x = self.Mixed_6b(x) # InceptionC(768, channels_7x7=128)
# 17 x 17 x 768
x = self.Mixed_6c(x) # InceptionC(768, channels_7x7=160)
# 17 x 17 x 768
x = self.Mixed_6d(x) # InceptionC(768, channels_7x7=160)
# 17 x 17 x 768
x = self.Mixed_6e(x) # InceptionC(768, channels_7x7=192)
# 17 x 17 x 768
if self.training and self.aux_logits:
aux = self.AuxLogits(x) # InceptionAux(768, num_classes)
# 17 x 17 x 768
x = self.Mixed_7a(x) # InceptionD(768)
# 8 x 8 x 1280
x = self.Mixed_7b(x) # InceptionE(1280)
# 8 x 8 x 2048
x = self.Mixed_7c(x) # InceptionE(2048)
'''进入分类部分。
经过平均池化层+dropout+打平+全连接层输出'''
x = F.adaptive_avg_pool2d(x, (1, 1))
# N x 2048 x 1 x 1
x = F.dropout(x, training=self.training)
# N x 2048 x 1 x 1
x = torch.flatten(x, 1)#Flatten()就是将2D的特征图压扁为1D的特征向量,是展平操作,进入全连接层之前使用,类才能写进nn.Sequential
# N x 2048
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux
def forward(self, x):
x, aux = self._forward(x)
return x, aux
'''-----------------------第五步:网络结构参数初始化--------------------------'''
# 目的:使网络更好收敛,准确率更高
def _initialize_weights(self): # 将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。
# 遍历网络中的每一层
for m in self.modules():
# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True
'''如果是卷积层Conv2d'''
if isinstance(m, nn.Conv2d):
# Kaiming正态分布方式的权重初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
'''判断是否有偏置:'''
# 如果偏置不是0,将偏置置成0,对偏置进行初始化
if m.bias is not None:
# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数val
nn.init.constant_(m.bias, 0)
'''如果是全连接层'''
elif isinstance(m, nn.Linear):
# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量
# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
'''---------------------------------------显示网络结构-------------------------------'''
if __name__ == '__main__':
net = GoogLeNet(1000).cuda()
from torchsummary import summary
summary(net, (3, 299, 299))
参考文章:经典卷积模型(四)GoogLeNet-Inception(V3)代码解析_
torchvision中inception v3的实现_/home/liupc的博客-CSDN博客
感谢大佬们!
番外
上面实现的是torchvision中的Inception v3结构,和论文中不太一样。因此我上GitHub上找到了论文复现的代码。先放个链接:https://github.com/AlgorithmicIntelligence/GoogLeNetv3_Pytorch/tree/master/models
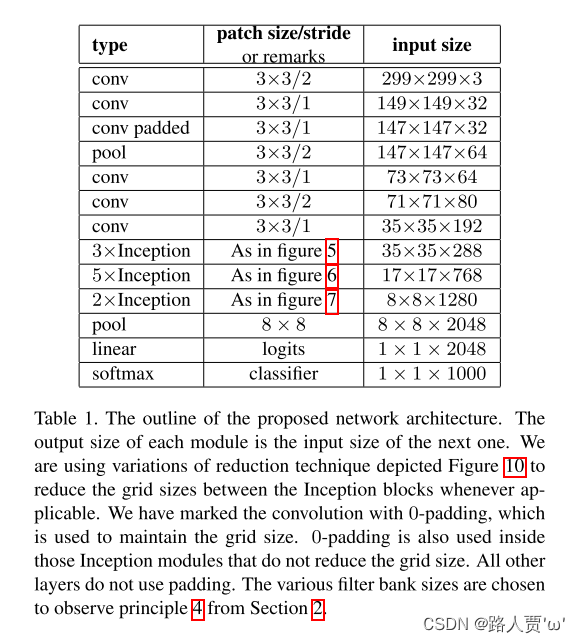
(论文中结构)
代码
import torch
import torch.nn as nn
from functools import partial
# functools.partial():减少某个函数的参数个数。 partial() 函数允许你给一个或多个参数设置固定的值,减少接下来被调用时的参数个数
'''-----------------------第一步:定义卷积模块-----------------------'''
#基础卷积模块
class Conv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, output=False):
super(Conv2d, self).__init__()
'''卷积层'''
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
'''输出层'''
self.output = output
if self.output == False:
'''bn层'''
self.bn = nn.BatchNorm2d(out_channels)
'''relu层'''
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
if self.output:
return x
else:
x = self.bn(x)
x = self.relu(x)
return x
class Separable_Conv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(Separable_Conv2d, self).__init__()
self.conv_h = nn.Conv2d(in_channels, in_channels, (kernel_size, 1), stride=(stride, 1), padding=(padding, 0))
self.conv_w = nn.Conv2d(in_channels, out_channels, (1, kernel_size), stride=(1, stride), padding=(0, padding))
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv_h(x)
x = self.conv_w(x)
x = self.bn(x)
x = self.relu(x)
return x
class Concat_Separable_Conv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(Concat_Separable_Conv2d, self).__init__()
self.conv_h = nn.Conv2d(in_channels, out_channels, (kernel_size, 1), stride=(stride, 1), padding=(padding, 0))
self.conv_w = nn.Conv2d(in_channels, out_channels, (1, kernel_size), stride=(1, stride), padding=(0, padding))
self.bn = nn.BatchNorm2d(out_channels * 2)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x_h = self.conv_h(x)
x_w = self.conv_w(x)
x = torch.cat([x_h, x_w], dim=1)
x = self.bn(x)
x = self.relu(x)
return x
#Flatten()就是将2D的特征图压扁为1D的特征向量,是展平操作,进入全连接层之前使用,类才能写进nn.Sequential
class Flatten(nn.Module):
# 传入输入维度和输出维度
def __init__(self):
# 调用父类构造函数
super(Flatten, self).__init__()
# 实现forward函数
def forward(self, x):
# 保存batch维度,后面的维度全部压平
return torch.flatten(x, 1)
#Squeeze()降维
class Squeeze(nn.Module):
def __init__(self):
super(Squeeze, self).__init__()
def forward(self, x):
return torch.squeeze(x)
'''-----------------------搭建GoogLeNet网络--------------------------'''
class GoogLeNet(nn.Module):
def __init__(self, num_classes, mode='train'):
super(GoogLeNet, self).__init__()
self.num_classes = num_classes
self.mode = mode
self.layers = nn.Sequential(
Conv2d(3, 32, 3, stride=2),
Conv2d(32, 32, 3, stride=1),
Conv2d(32, 64, 3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
Conv2d(64, 80, kernel_size=3),
Conv2d(80, 192, kernel_size=3, stride=2),
Conv2d(192, 288, kernel_size=3, stride=1, padding=1),
#输入:35*35*288。将5*5用两个3*3代替
Inceptionv3(288, 64, 48, 64, 64, 96, 64, mode='1'), # 3a
Inceptionv3(288, 64, 48, 64, 64, 96, 64, mode='1'), # 3b
Inceptionv3(288, 0, 128, 384, 64, 96, 0, stride=2, pool_type='MAX', mode='1'), # 3c
#输入:17*17*768。
Inceptionv3(768, 192, 128, 192, 128, 192, 192, mode='2'), # 4a
Inceptionv3(768, 192, 160, 192, 160, 192, 192, mode='2'), # 4b
Inceptionv3(768, 192, 160, 192, 160, 192, 192, mode='2'), # 4c
Inceptionv3(768, 192, 192, 192, 192, 192, 192, mode='2'), # 4d
Inceptionv3(768, 0, 192, 320, 192, 192, 0, stride=2, pool_type='MAX', mode='2'), # 4e
#8*8*1280
Inceptionv3(1280, 320, 384, 384, 448, 384, 192, mode='3'), # 5a
Inceptionv3(2048, 320, 384, 384, 448, 384, 192, pool_type='MAX', mode='3'), # 5b
nn.AvgPool2d(8, 1),
Conv2d(2048, num_classes, kernel_size=1, output=True),
Squeeze(),
)
if mode == 'train':
self.aux = InceptionAux(768, num_classes)
def forward(self, x):
for idx, layer in enumerate(self.layers):
if (idx == 14 and self.mode == 'train'):
aux = self.aux(x)
x = layer(x)
if self.mode == 'train':
return x, aux
else:
return x
'''-----------------------网络结构参数初始化--------------------------'''
# 目的:使网络更好收敛,准确率更高
def _initialize_weights(self): # 将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。
# 遍历网络中的每一层
for m in self.modules():
# isinstance(object, type),如果指定的对象拥有指定的类型,则isinstance()函数返回True
'''如果是卷积层Conv2d'''
if isinstance(m, nn.Conv2d):
# Kaiming正态分布方式的权重初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
'''判断是否有偏置:'''
# 如果偏置不是0,将偏置置成0,对偏置进行初始化
if m.bias is not None:
# torch.nn.init.constant_(tensor, val),初始化整个矩阵为常数val
nn.init.constant_(m.bias, 0)
'''如果是全连接层'''
elif isinstance(m, nn.Linear):
# init.normal_(tensor, mean=0.0, std=1.0),使用从正态分布中提取的值填充输入张量
# 参数:tensor:一个n维Tensor,mean:正态分布的平均值,std:正态分布的标准差
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
'''---------------------Inceptionv3-------------------------------------'''
'''
Inceptionv3由三个连续的Inception模块组组成
'''
class Inceptionv3(nn.Module):
def __init__(self, input_channel, conv1_channel, conv3_reduce_channel,
conv3_channel, conv3_double_reduce_channel, conv3_double_channel, pool_reduce_channel, stride=1,
pool_type='AVG', mode='1'):
super(Inceptionv3, self).__init__()
self.stride = stride
if stride == 2:
padding_conv3 = 0
padding_conv7 = 2
else:
padding_conv3 = 1
padding_conv7 = 3
if conv1_channel != 0:
self.conv1 = Conv2d(input_channel, conv1_channel, kernel_size=1)
else:
self.conv1 = None
self.conv3_reduce = Conv2d(input_channel, conv3_reduce_channel, kernel_size=1)
#第一种Inception模式:输入的特征图尺寸为35x35x288,采用了论文中图5中的架构,将5x5以两个3x3代替。
if mode == '1':
self.conv3 = Conv2d(conv3_reduce_channel, conv3_channel, kernel_size=3, stride=stride,
padding=padding_conv3)
self.conv3_double1 = Conv2d(conv3_double_reduce_channel, conv3_double_channel, kernel_size=3, padding=1)
self.conv3_double2 = Conv2d(conv3_double_channel, conv3_double_channel, kernel_size=3, stride=stride,
padding=padding_conv3)
#第二种Inception模块:输入特征图尺寸为17x17x768,采用了论文中图6中nx1+1xn的不对称卷积结构
elif mode == '2':
self.conv3 = Separable_Conv2d(conv3_reduce_channel, conv3_channel, kernel_size=7, stride=stride,
padding=padding_conv7)
self.conv3_double1 = Separable_Conv2d(conv3_double_reduce_channel, conv3_double_channel, kernel_size=7,
padding=3)
self.conv3_double2 = Separable_Conv2d(conv3_double_channel, conv3_double_channel, kernel_size=7,
stride=stride, padding=padding_conv7)
#第三种Inception模块:输入特征图尺寸为8x8x1280, 采用了论文图7中所示的并行模块的结构
elif mode == '3':
self.conv3 = Concat_Separable_Conv2d(conv3_reduce_channel, conv3_channel, kernel_size=3, stride=stride,
padding=1)
self.conv3_double1 = Conv2d(conv3_double_reduce_channel, conv3_double_channel, kernel_size=3, padding=1)
self.conv3_double2 = Concat_Separable_Conv2d(conv3_double_channel, conv3_double_channel, kernel_size=3,
stride=stride, padding=1)
self.conv3_double_reduce = Conv2d(input_channel, conv3_double_reduce_channel, kernel_size=1)
if pool_type == 'MAX':
self.pool = nn.MaxPool2d(kernel_size=3, stride=stride, padding=padding_conv3)
elif pool_type == 'AVG':
self.pool = nn.AvgPool2d(kernel_size=3, stride=stride, padding=padding_conv3)
if pool_reduce_channel != 0:
self.pool_reduce = Conv2d(input_channel, pool_reduce_channel, kernel_size=1)
else:
self.pool_reduce = None
def forward(self, x):
output_conv3 = self.conv3(self.conv3_reduce(x))
output_conv3_double = self.conv3_double2(self.conv3_double1(self.conv3_double_reduce(x)))
if self.pool_reduce != None:
output_pool = self.pool_reduce(self.pool(x))
else:
output_pool = self.pool(x)
if self.conv1 != None:
output_conv1 = self.conv1(x)
outputs = torch.cat([output_conv1, output_conv3, output_conv3_double, output_pool], dim=1)
else:
outputs = torch.cat([output_conv3, output_conv3_double, output_pool], dim=1)
return outputs
'''------------辅助分类器---------------------------'''
class InceptionAux(nn.Module):
def __init__(self, input_channel, num_classes):
super(InceptionAux, self).__init__()
self.layers = nn.Sequential(
nn.AvgPool2d(5, 3),
Conv2d(input_channel, 128, 1),
Conv2d(128, 1024, kernel_size=5),
Conv2d(1024, num_classes, kernel_size=1, output=True),
Squeeze()
)
def forward(self, x):
x = self.layers(x)
return x
'''-------------------显示网络结构-------------------------------'''
if __name__ == '__main__':
net = GoogLeNet(1000).cuda()
from torchsummary import summary
summary(net, (3, 299, 299))本篇到这里就结束了,有什么问题欢迎大家留言讨论呀!
















 5181
5181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











