







 本文介绍了一种使用Python和pandas库从MongoDB数据库中读取亚马逊Canada商品数据的方法,并展示了如何处理和转换数据,包括读取关键词下流量ASIN的详细信息,处理链接ID中的NaN值,以及将链接ID中的列表展开为多行。
本文介绍了一种使用Python和pandas库从MongoDB数据库中读取亚马逊Canada商品数据的方法,并展示了如何处理和转换数据,包括读取关键词下流量ASIN的详细信息,处理链接ID中的NaN值,以及将链接ID中的列表展开为多行。
1、读取关键词下流量ASIN的详细信息,
https://zhuanlan.zhihu.com/p/48854436 大佬的pandas详解
import numpy as np
import pandas as pd
from numpy import nan as NA
import re
import pymongo
conn = pymongo.MongoClient(host='127.0.0.1', port=27017)
db = conn.amazon_Canada
db_table = db.amazon_Canada_goods
#数据库的链接
res=[]
for search in db_table.find({},{'_id':0,'img':0}): #不要图片
# print(search)
res.append(search)
df1=pd.DataFrame(res)
def get_kinds_id(x):
if len(x) > 0:
link_list = []
for link in x:
str_index = link.index('/ref')
cut_str = link[:str_index] # 字符串截取
each_link_1 = 'https://www.amazon.ca' + cut_str + '/?&pg=1' # 第一页
link_list.append(each_link_1)
return link_list
else:
return NA
df1['link_id']=df1.ranking_href.apply(get_kinds_id) #返回的还是一哥列表
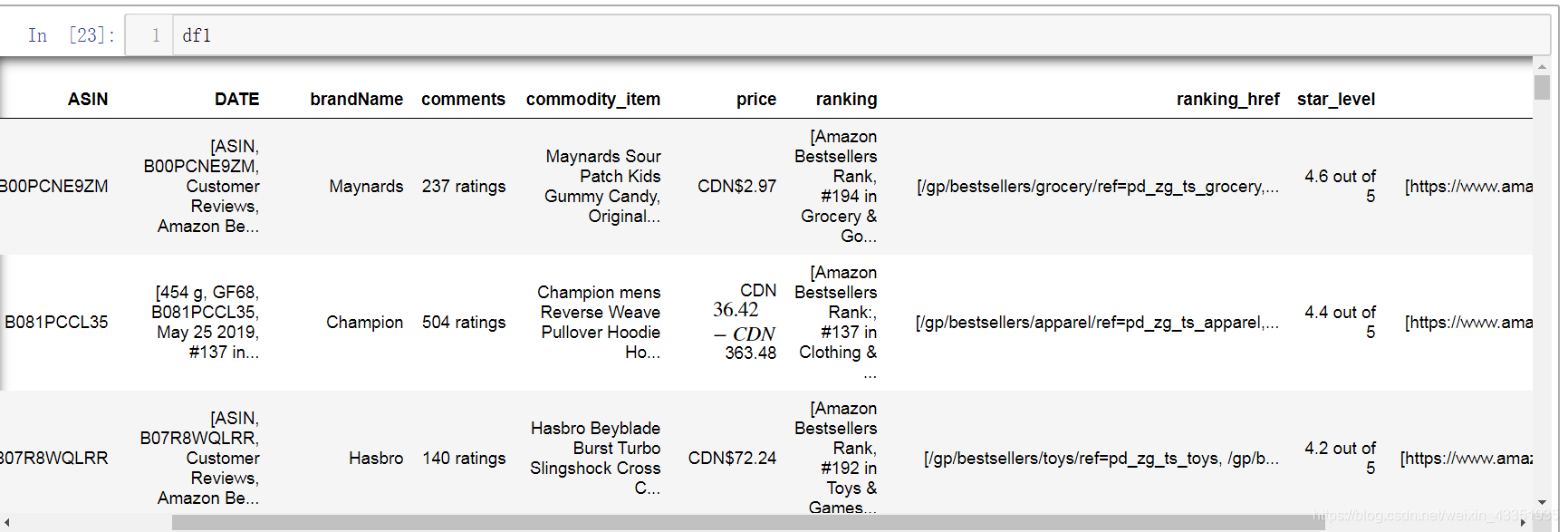
2、读取第6行数据的信息,发现link-id有nan,
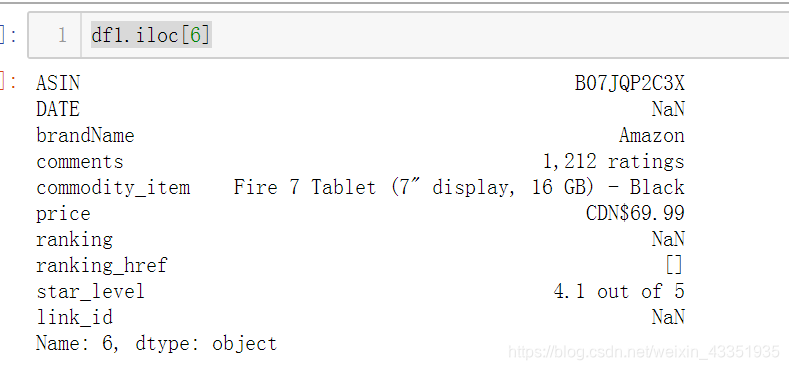
3、查看link_id中的nan的个数
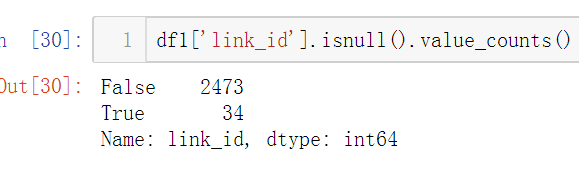
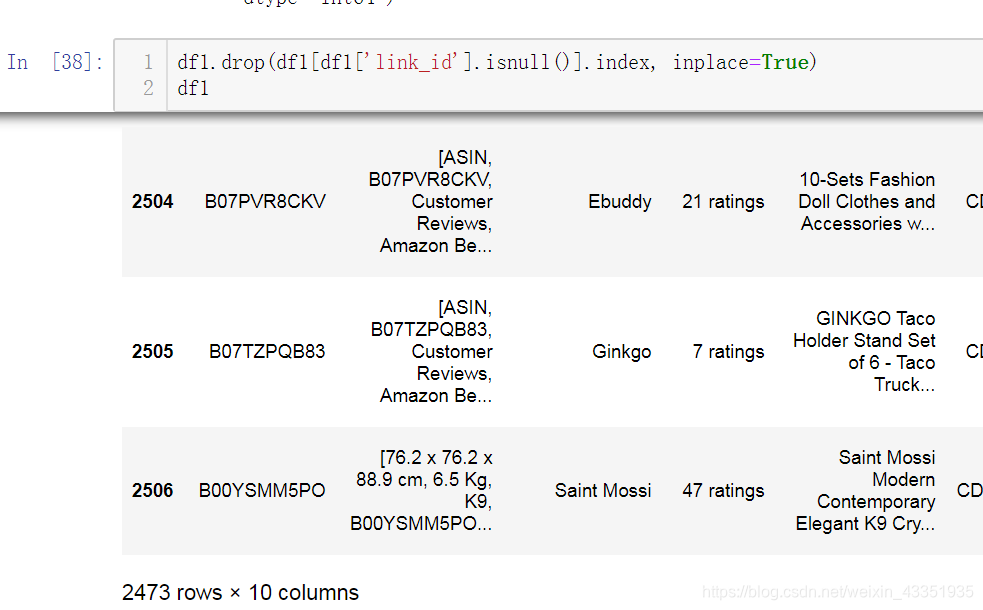
4.将link_id中的nan删除,将link_id中的列表展开为多行。
找到nan的索引。。
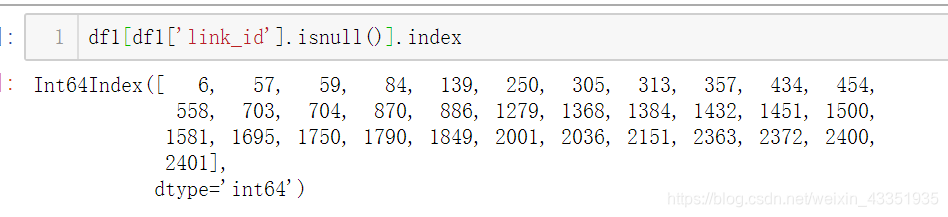
将这些索引行,进行删除。
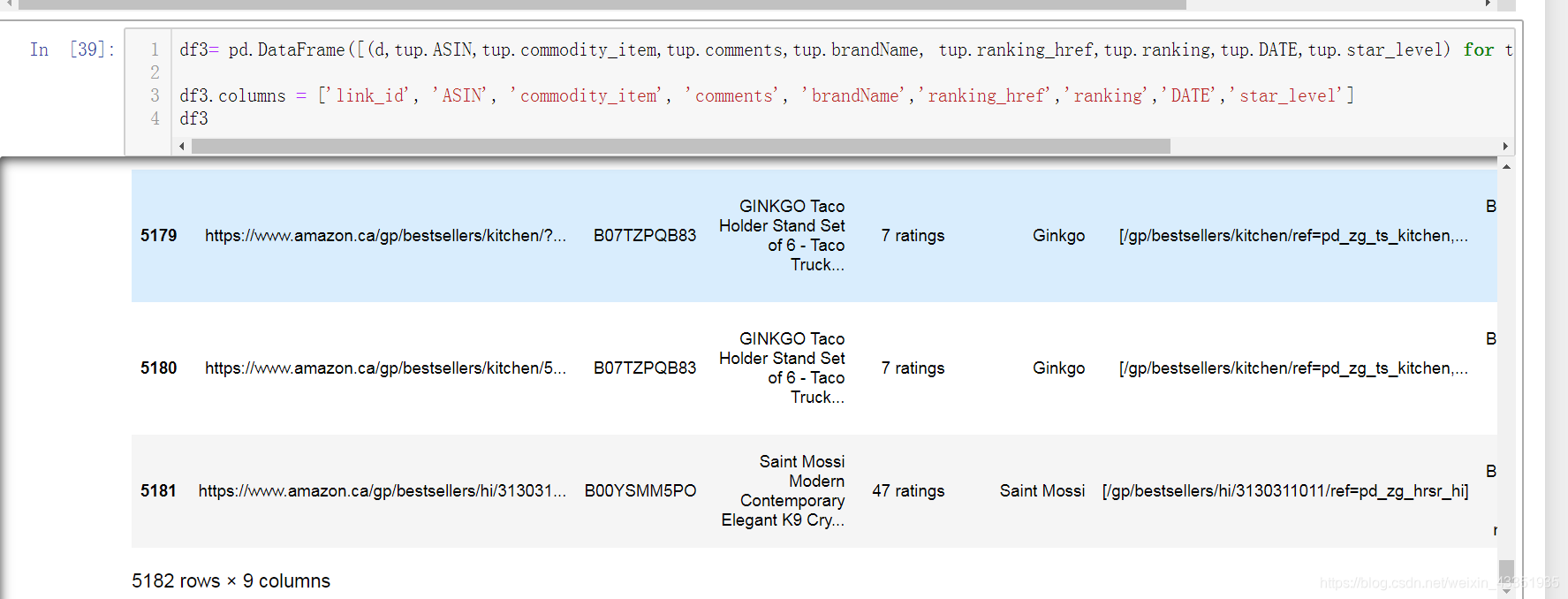
df3= pd.DataFrame([(d,tup.ASIN,tup.commodity_item,tup.comments,tup.brandName, tup.ranking_href,tup.ranking,tup.DATE,tup.star_level) for tup in df1.itertuples() for d in tup.link_id])
df3.columns = ['link_id', 'ASIN', 'commodity_item', 'comments', 'brandName','ranking_href','ranking','DATE','star_level']
df3
将link_id中的列表进行展开成为多行。
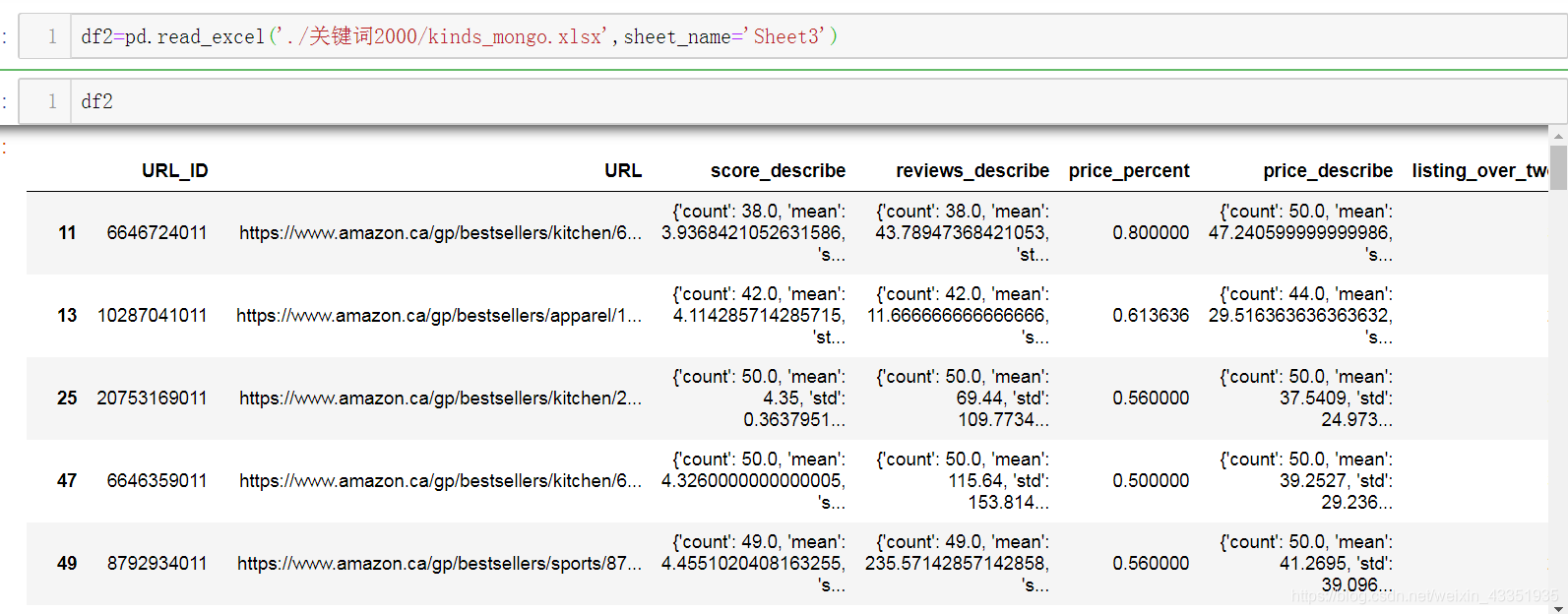
5.读取另外一张表的关于类目的信息
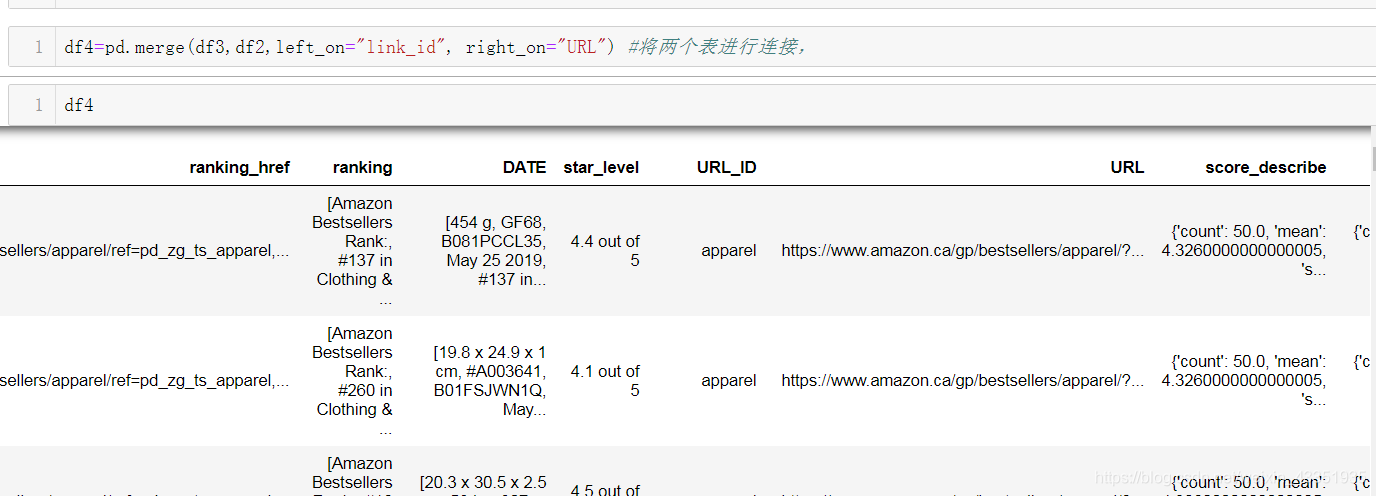
6、将两张表安装类目的链接进行合并。以相同的列的内容进行拼接。


















 3484
3484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











