






标题:Knowledge Base Question Answering: A Semantic Parsing Perspective
原文链接:https://arxiv.org/abs/2209.04994
作者:Yu Gu …
发表年份:2022
收录期刊:
摘要:作者从语义解析(semantic parsing)的角度,提出了KBQA的两大挑战,模式级复杂性(schema complexity)和事实级复杂性(fact complexity),介绍了常用的数据集、方法、指标等,并对KBQA未来的发展提出了自己的想法。
文章目录
Introduction
KBQA中的SP主要面临着两大独特的挑战,模式级复杂性(schema complexity)和事实级复杂性(fact complexity)。
模式级复杂性(schema complexity):KB中的schema非常多。
例如,Freebase中有超过8k个schema(6k个关系,2k种类型),而关系型数据库中通常只包含十几个schema(表名和表头)。
因此,模型要学习从自然语言到模式的对齐相对于其他来说是更加困难的。此外,比起其他语义解析任务,KBQA对schema的理解要求更高。
事实级复杂性(fact complexity):由于KB中的模式项的实例化是动态变化的,所以事实级的信息非常重要。
例如,person 类型可以与超过 1K 种不同的关系相关联,而 person 的每个实例只能与其中的几个相关联。
因此,生成可以基于 KB 的非空答案的逻辑形式,即 faithful to KB,需要紧密结合事实级信息。此外,由于知识库事实的图结构的组合爆炸而导致的巨大的搜索空间,使得生成faithful的查询变得更加具有挑战性。
Background
与关系数据库相比,知识库具有更加复杂的模式。
格式良好(well-formed)的查询在语法上是正确的,因此可以无一例外地执行,但可能会出现空答案,而faithful的查询必须从 KB 中找到非空答案。
Datasets & Metrics
现有数据集:
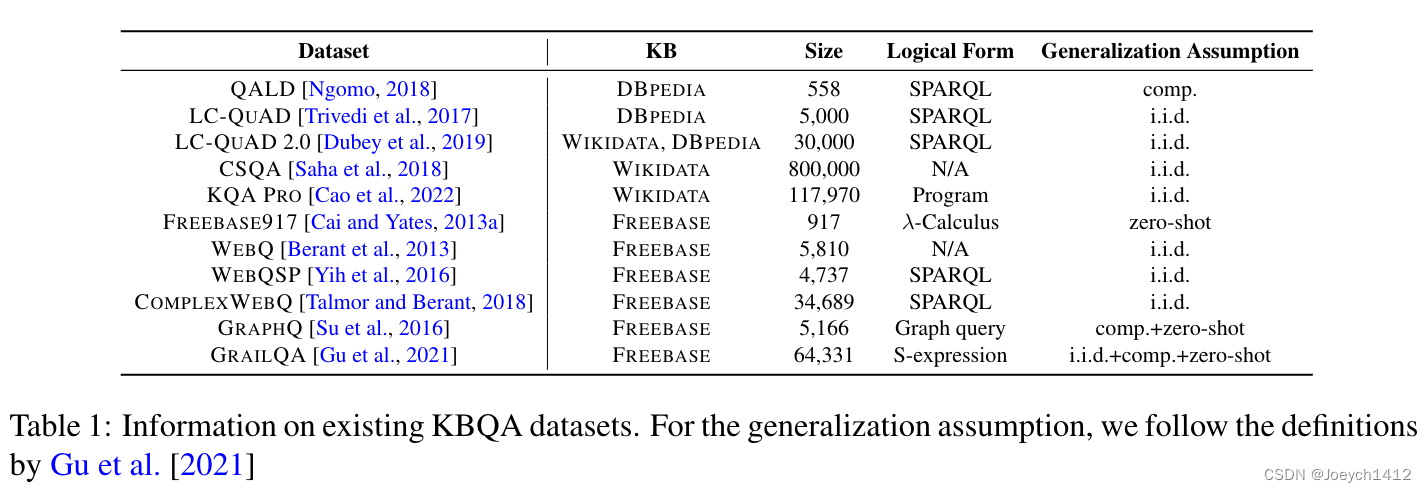
常用的指标:
基于执行的指标:F1
严格指标:ExactMatch
Approachs
现有方法可分为三类:ranking methods、coarse-to-fine methods、generation methods。
Ranking Methods:首先遍历从KB中用某种方法得到的候选queries,然后对这些候选queries和question计算匹配分数,选出分数最高的query进行输出。
Coarse-to-fine Methods:首先生成query skeleton,然后将骨架ground到KB中。
Generation Methods:通过约束decoding的方式把query ground到KB中,因此动态减小了搜索空间。
Ranking Methods
候选query遍历
通过图谱中的事实信息(实体/关系的邻域)生成可能的sparql语句(faithful),再对这些sparql candidates进行打分,选择得分最高的candidate作为最终输出。
传统方法:提前制定一些query模版,然后具体的语句进行填充。
另一种常见的策略是首先从问题中识别主题实体,然后将其用作锚点来遍历知识库中的邻域以枚举可能的查询。
尽管这些方法可以有效地使用已识别的锚点进行faithful的查询枚举,但它们都存在可扩展性问题,例如,它们通常对关系路径施加最大长度限制为 2。
语义匹配
早期方法通过人工制定的特征和可学习的排序方法找到分数最高的候选query。
现在多用PLMs进行语义匹配,例如BERT等。
Coarse-to-fine Methods
将语义解析分解为两个阶段。首先,模型只预测粗略的查询骨架skeleton(或草图),它侧重于高层结构(粗略的解析)。其次,该模型通过将查询骨架ground到 KB(精细解析)来填充缺失的细节。
骨架生成
目前通常使用encoder-decoder来预测骨架。达斯等人 [2021] 使用 T5 直接从问题中输出粗查询并从训练数据中检索案例。查询可能包含不准确的模式项,需要在基础期间进一步修改。
Grounding
The grounding step fills (or revises) a query skeleton to produce the final faithful query
丁等 [2019] 使用现成的系统来链接问题中可能的实体和关系,然后为每个骨架尝试它们所有可能的组合。最终分数基于链接概率和骨架解析概率。
孙等 [2020] 从训练数据中找到最相似的问题,并使用该问题中的模式项来构建骨架。
达斯等人 [2021] 通过使用字符串级别和嵌入级别的相似性将它们与主题实体附近的项目对齐来修改不准确的模式项目。
Generation Methods
生成式方法已成为许多语义解析任务的实际选择,并且由于其灵活性和可扩展性,也已成为 KBQA 的趋势范例。生成式方法对产生faithful的查询提出了独特的挑战,这需要在生成(解码)过程中紧密结合KB结构。
Literatures
Discusion
End-to-End
KBQA Based on Encoder-Decoders
尽管编码器-解码器范式彻底改变了语义解析的研究并成为许多下游任务的规范,但它在 KBQA 中并不那么流行。这是由于使用编码器-解码器模型为 KBQA 生成faithful查询的挑战。
具体来说,编码器-解码器模型可以使用三个不同级别的控制进行预测,即无约束解码、具有模式级约束的解码和具有事实级约束的解码。对于text-to-SQL,无约束解码在i.i.d设置 [Hwang et al., 2019]下可以取得满意的结果。而对于 KBQA,无约束解码的 Seq2Seq 模型的性能明显低于排序方法 [Gu et al., 2021]。这是因为KB具有更加复杂的模式,无法使用无约束的解码器以数据驱动的方式很好地学习其结构。
我们可以注入有关模式的先验知识来限制解码输出空间。例如,在 text-to-SQL 中,此类约束包括从它所属的表中选择一列,而在 KBQA 中,此类约束可以根据关系的域/范围信息定义。
对于现有的 text-to-SQL benchmarks,well-formed几乎等于faithful,而这不适用于 KBQA,因为 KB 是动态实例化的。因此,要在 KBQA 中使用编码器-解码器,更复杂的事实级约束是必不可少的。
Joint Entity Linking
现有的 KBQA 研究通常依赖于现成的实体链接器。作者认为当前的规范是有问题的,因为 1) pipelines会受到错误传播的影响,以及 2) 它禁止实体链接和语义解析相互促进。
通过增强关系的实体消歧 [Ye et al., 2022] 以及关系和实体的联合链接(但仅限于预先过滤的一组候选者),已经做出了初步努力来打破规范。我们设想了一个 KBQA 模型,它以真正端到端的方式联合执行实体链接和语义解析。一个有前途的方向是将实体投影到连续空间中并对它们执行可微分操作 [Ren et al., 2021],因为在离散空间中操作数百万个实体可能很棘手。
Pre-training
KBQA with PLMs
大量的 KB 模式项阻止 KBQA 通过输入串联使用 PLM 对问题和所有模式项进行联合编码,就像在文本到 SQL 中所做的那样。为了适应 KBQA,Gu 等人 [2021]和陈等人 [2021]建议缩小候选模式项的大小以适应 PLM 的长度限制。然而,预先识别相关模式项是不灵活的。一个更有希望的方向是将 PLM 与受限解码集成 [Liang et al., 2017, Gu and Su, 2022],其中相关的模式项是动态选择的。
此外,为了更好地理解 KB 模式,未来的工作可能会显式地对模式项和问题标记之间的关系进行建模 [Wang et al., 2020],而不是仅通过输入串联将其隐式委托给 PLM 的自注意力层。
使用 类似于PICARD [Scholak et al., 2021] 的受限解码算法来增强编码器-解码器 PLM 是 KBQA 的一个有前途的方向。
KBQA-specific Pre-training
KBQA 中的现有工作表明了跨数据集预训练的可行性 [Gu et al., 2021, Cao et al., 2021],而针对 KBQA 特定预训练的通用解决方案(如用于文本到 SQL 的 GRAPPA)仍然缺乏。在 KBQA 中应用特定于任务的预训练具有挑战性。首先,合成对齐的问题-查询对语料库可能会导致数据污染,尤其是在评估 KBQA 中的零样本泛化时。其次,KBQA 特定的预训练任务需要考虑查询中的结构化信息,而像 SSP 这样的二元分类任务将达不到这个目标。解决这些问题的一个可能的方向是综合与知识库无关的查询并指定用于预训练的结构化预测任务。
More Generalizable
同样,对 KBQA 的研究最近将其重点转移到了非独立同分布泛化。非独立同分布之间的主要区别text-to-SQL 和 KBQA 中的泛化是相关表作为 text-to-SQL 中的输入给出,而 KBQA 中所有问题共享相同的 KB,因此模型需要自行确定 KB 的哪一部分是相关的。
因此,顾等人 [2021] 建议高度泛化的模型应该具有有效的搜索空间修剪功能。一个有前途的方向是,比起 PICARD [Scholak 等人,2021 年,Xie 等人,2022 年],对编码器-解码器 PLM 使用更加特定于 KB 的约束解码算法。
虽然 Gu 等人的定义 [2021] 可扩展到具有多个 KB 的 KBQA,它们的数据集是用单个 KB(即 FREEBASE)收集的。需要一个支持对这种跨 KB 泛化进行系统评估的数据集。
Other Trends
未来的工作可能会研究交互式 KBQA 以更好地处理复杂的 KB 查询。
KBQA 中的prompt tuning [Lester et al., 2021] 仍有待研究。
最近的工作考虑了文本到 SQL 中跨域泛化的少样本设置 [Lee et al., 2021],未来的工作还可能探索 KBQA 中的少样本上下文学习和非独立同分布泛化中prompting的潜力。















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









