






本文是机器阅读理解论文的第二篇,发表于2015年。论文提出了新的训练集,即CNN和每日邮报的新闻语料库,并针对此数据集构建了新的深度学习模型。以下是对论文的部分翻译和解读
摘要:
让机器阅读自然语言文件仍然是一个非常难的挑战。目前可以根据机器阅读系统阅读过文章后回答问题的能力进行测试,但是这类评估还缺少大规模的训练和测试数据集。本文提出了一种新的方法以解决这个问题,并提供大规模的可用于监督学习的阅读理解数据。 这使我们能够开发一类基于注意力的深度神经网络,可以学习阅读真实文档并以最少的语言结构的先验知识来回答复杂问题。
1.简介:
传统的机器阅读理解算法通常是基于手工设置语法,或者信息抽取方法,检测谓词元组然后可以用关系数据库查询。因为缺少大规模的训练数据,以及在构建可以学习文档结构的概率模型上还有困难,监督学习的方法还没有被大量使用。(2015年)
本文提出了一个新的方法用于构建用于监督学习的阅读理解数据。我们发现使用简单的实体检测和匿名算法可以将总结性和释义性的句子与相关文档转化成(上下文-查询-答案)的元组。使用这种算法我们在CNN和每日邮报(Daily Mail)网站上采集了约一百万个新闻和相应的问题,组成了两个新的语料库。
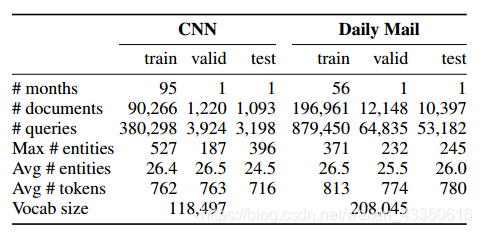
上图是语料库的数据。CNN语料库采集了2007年4月到2015年4月CNN上的文章,其中2015年3月的数据作为验证集,2015年4月的数据作为测试集。每日邮报语料库采集了2010年5月到2015年4月的文章,与CNN一样,也是用最后两个月的数据分别作为验证集和测试集。另外,还剔除了超过2000字的文章和文本中没有确切答案的问题。
为了展示两个新语料库的带来的效果,本文还针对阅读理解任务构建了新的深度学习的模型。这些模型基于循环神经网络和注意力机制,在与传统方法的比较中更胜一筹。
2.阅读理解中的监督训练数据
阅读理解任务是一个监督学习问题,具体来说就是估计条件概率p(a|c,q),c是上下文文档,q是与该文档相关的查询,a是这个查询的答案。为了能够更好的评估模型的性能,我们希望能够去掉如常识(world knowledge)之类的额外信息。我们在CNN和每日邮报网站上各采集了93k和220k篇文章。两个新闻提供商还为每篇文章补充了一定数量的要点、总结。这些总结都是比较凝练的,并不是从文章中的句子copy出来的。通过将这些要点转化为完形填空风格的问题,每次替换其中的一个实体,我们创建了一个文档-查询-答案的语料库。
2.1实体替换和置换
本文旨在提供以评估模型阅读理解单篇文档的能力的语料库,而不是为了提取出常识或共现词(co-occurrence),比如如下完形填空风格的查询:
- The hi-tech bra that helps you beat breast X;
- Could Saccharin help beat X ?;
- Can fish oils help fight prostate X ?
虽然没有完整地上下文,但在每日邮报数据集上训练出来的n元语言模型依然可以准确地预测到(X=cancer),仅仅因为这是在语料库中经常出现的词。为了防止出现这种情况,本文按照如下过程对语料库进行了匿名化和随机化处理:
- 使用指代系统为每个数据点创建指代(coreferent)。
- 根据指代将所有的实体(Entity)替换为抽象的实体标记。
- 加载数据的时候对这些实体标记进行置换。
3.模型
本文对符号匹配模型和神经网络模型进行了比较和测试。
未完待续…














 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









