







原创:张春阳

应用和数据集
- QA
- SQuAD
后续影响
- ELMo
- BERT
原始论文
BI-DIRECTIONAL ATTENTION FLOW FOR MACHINE COMPREHENSION.pdf
- 原文的主要阅读难度在于,有大量的 block 组装在一起
- 这些模块又由很多复杂的符号组装在一起
模型概览
Type of MRC
- Open-domain vs Closed-domain
- Abstractive vs Extractive
- Ability to answer non-factoid queries
BiDAF is a closed-domain, extractive Q&A model that can only answer factoid questions.

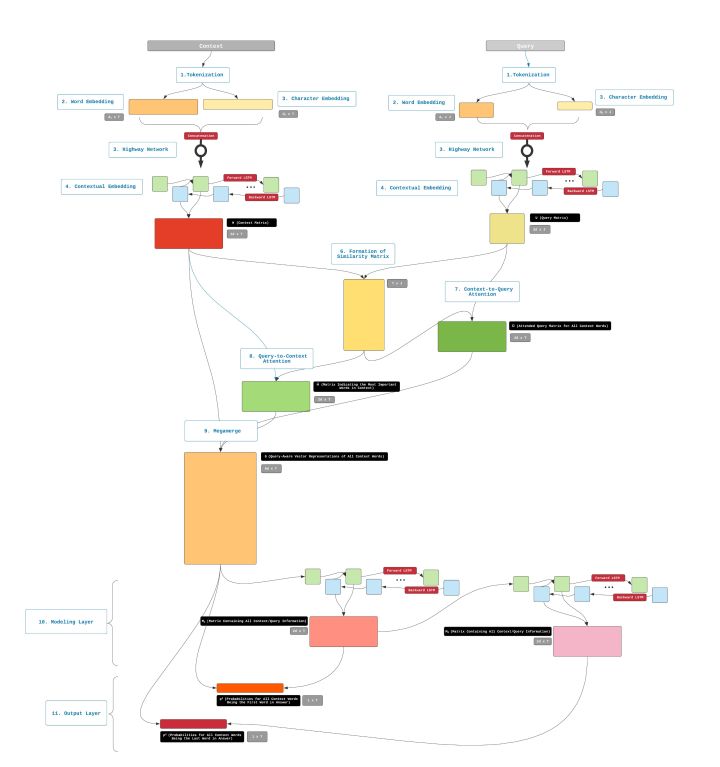
模型整体结构
-
Embedding Layers
BiDAF 有3个 embedding layers,每一个都是用来把 Query 和 Context 字符串转变成向量的
-
Attention and Modeling Layers
通过 Attention 和 Modeling Layer,把 Query 和 Context 的信息进行合并,这部分的输出为另一个带有混合信息的向量表达。在原文中叫做 "Query-aware Context representation"
-
Output Layer
输出层会把 “Query-aware Context representation” 转化成一连串的概率,这些概率用来决定 Answer 的起始和结束位置。
Glossary
- Context : the accompanying text to the Query that contains an answer to that Query
- Query : the question to which the model is supposed to give an answer
- Answer : a substring of the Context that contains information that can answer Query. This substring is to be extracted out by the model
- T : 表示在 Context 中 words/tokens 的数量
- J : 表示在 Query 中 words/tokens 的数量
- d1 : the dimension from the word embedding step (GloVe)
- d2 : the dimension from the character embedding step
- d : the dimension of the matrices obtained by vertically concatenating word and character embeddings. d is equal to d1 + d2.
- H : the Context matrix outputted by the contextual embedding step. H has a dimension of 2dby-T
- U : the Query matrix outputted by the contextual embedding step. U has a dimension of 2dby-J
Embedding Layers
步骤1: Tokenization
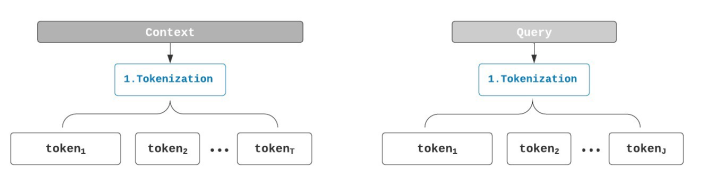
T: 表示在 Context 中 words/tokens 的数量
J: 表示在 Query 中 words/tokens 的数量
把 tokenization 的结果转换成向量的形式,在 BiDAF 中使用三个维度来表示这些信息。
- word level embedding
- character level embedding
- contextual level embedding
步骤2: Word Level Embedding
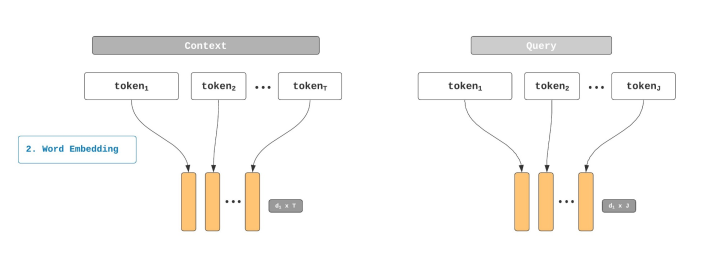
BiDAF 使用预训练的 GloVe 向量来获取 Query 和 Context 的表达。
使用 GloVe 处理后的输出为两个矩阵,一个是 Context 的,一个是 Query 的。
这两个矩阵的长度分别为 T(Context) 和 J(Query),其中矩阵的维度为 d 1 d_1 d1,这是一个预设的向量大小的值,可以是50/100/200/300。
步骤3: Character Level Embedding
我们使用 GloVe 处理后的矩阵并不够,因为还有一些单词是在 GloVe 中不存在的(OOV,在GloVe中,oov 的值为随机的一些向量),我们要使用一些补救方法来处理这些值。
所以,这里我们引入了一个 1D 的卷积神经网络来寻找这些 token 的 character 级别的向量表示。

步骤4: Highway Network
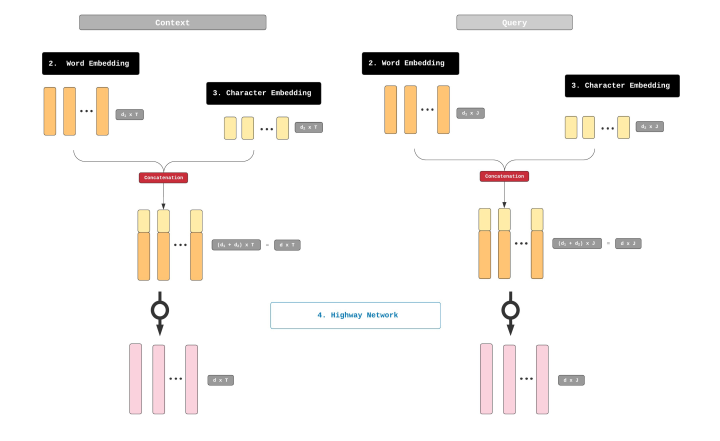
我们从之前的步骤中,得到了两个表示单词的向量, GloVe 和 1D-CNN 的向量。接下来把两个向量,在垂直方向上连接(concatenate)。这样会产生两个矩阵,分别表示 Contex 和 Query。它们的高度是 d = d 1 + d 2 d = d_1 + d_2 d=d1+d2。同时,它们的长度和之前的相同,Contex 的是 T T T,Query 是 J J J。
如果我们把一个输入的向量 y y y 放到单层的神经网络中,在生成 z z z 的过程中,会经过以下的过程:
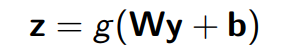
在我们的 highway network 中,只有一小部分的输入会被执行上面的步骤;剩下的部分会不经过转换直接穿过 highway network。这个比例被一个权重 t t t 管理着,那么 ( 1 − t ) (1-t) (1−t) 就是 transform gate。这个 t t t 被使用 s i g m o i d sigmoid sigmoid 函数计算,通常是一个0到1之间的值。
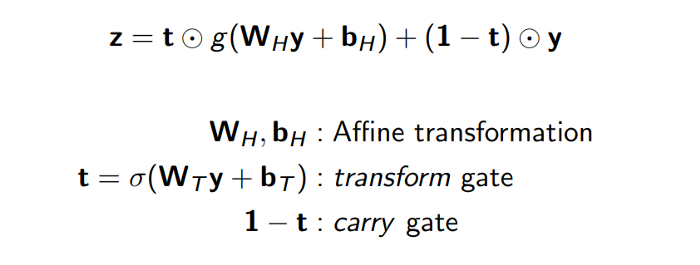
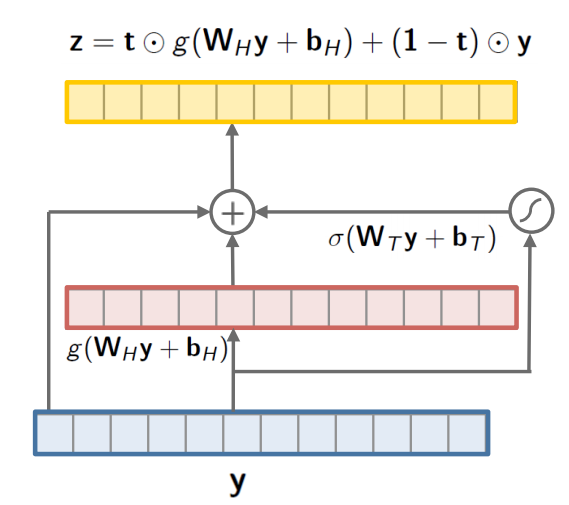
这个网络的主要作用是,调整 word embedding 和 character embedding 的相对贡献。
这里面的逻辑是,当我们遇到一个 OOV 的单词 “misunderestimate”,我们就可以提高这个单词 1D-CNN 表示的权重,因为这里识别到 GloVe 是一个随机的没有意义的值。另一方面,如果我们有一个普遍的不模糊的单词 “table”,我们就可以给 GloVe 的表示更高的权重。
这一步的输出也是两个矩阵,一个是 Context 矩阵( d ∗ T d * T d∗T),另一个是 Query 矩阵( d ∗ J d * J d∗J)。他们分别代表了 Query 和 Contex 的混合表示。
步骤5: Contextual Embedding
对于我们的任务,上面的对于文本的表示还不足够。这里主要的原因是,上面的这些表示并没有考虑到上下文的含义,我们需要把上下文的含义也表示在 Embedding 中。
这里有一个例子可以解释为什么要这么做,比如说有一对单词 “tear”(眼泪) 和 “tear”(撕扯),他们都是相同的拼写,却有着截然不同的含义,如果不把上下文考虑进去,我们很难去对这两者作区分。
因此,我们需要一个能够理解单词上下文的结构。BiDAF 使用一个双向的 LSTM(bi-LSTM).
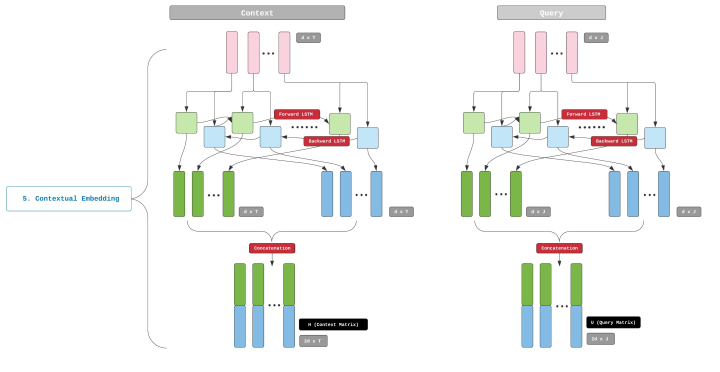
这一步的输出是两个矩阵,一个 Context 矩阵,另一个 Query 矩阵。 分别使用 H H H( d ∗ T d*T d∗T) 和 U U U ( d ∗ J d*J d∗J)来表示(这里的 H H H 不同于之前从卷积中获得的矩阵 H H H, 这里只是一个巧合)。
以上这些就是在 BiDAF 中所有关于 embedding 的部分,接下来我们会使用 Attention 把 Context 和 Query 进行融合。
Attention Mechanism
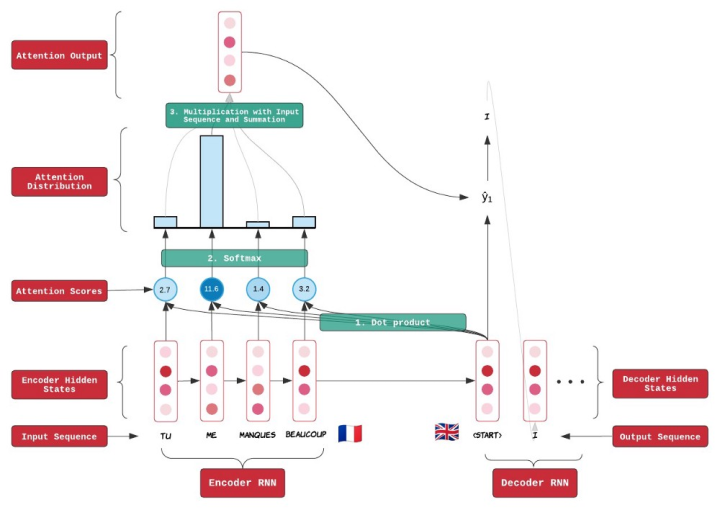
之前的输出, H H H 表示 Context,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3094
3094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









