







 本文详细解析了在第三届华为杯研究生创芯大赛中,如何通过优化流水线架构、模块复用和非线性映射来减小128bit密钥扩展模块的面积。从四级流水线到串行化设计,展示了面积与性能的权衡过程,最终通过复用和优化策略,面积降低40%。
本文详细解析了在第三届华为杯研究生创芯大赛中,如何通过优化流水线架构、模块复用和非线性映射来减小128bit密钥扩展模块的面积。从四级流水线到串行化设计,展示了面积与性能的权衡过程,最终通过复用和优化策略,面积降低40%。
数字芯片的面积优化:第三届“华为杯”研究生创芯大赛数字方向上机题1详解
引言:数字芯片中的PPA优化
在数字芯片的设计过程中,功耗,性能,面积,即Power, Performance, Area (PPA),是设计者最为关注的三个指标。这三个指标往往是互相取舍的关系,好的设计应该在三者之间取得平衡。但是在一些特殊场景下,我们可能会针对某一个指标进行优化,以满足场景的特定需求,如在移动端设备上追求极致的低功耗,在成本敏感的环节追求极致的小面积。这里,我们采用“华为杯”研究生创芯大赛中的一个上机题来说明数字芯片中对面积的一些优化手段,有不足之处,还希望大家多多指正!
题目说明
本题目为第三届“华为杯”研究生创芯大赛数字方向上机题第一题,设计目标是完成一个小面积的 128bit 位宽密钥扩展模块,题目说明如下图所示,完整题目链接和测试样例可以通过以下链接公开获取:2020年大赛上机设计题-数字组.

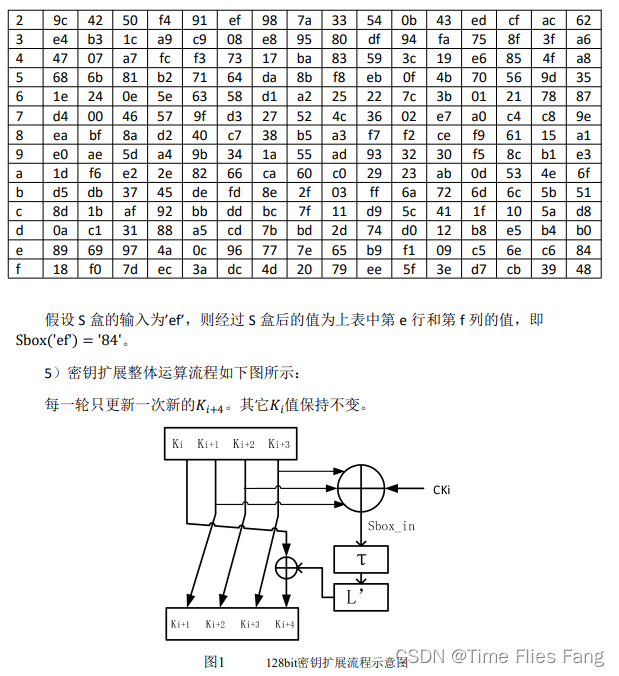
整体阅读下来,我们可以总结出题目所需要完成的几个基本算子:
- 32 bit的异或运算;
- 非线性查找表;
- 循环左移。
算子集本身非常简单,密钥扩展的数据流也不复杂,理论上,将题设中涉及的变量与计算理清楚,就可以很容易地完成题目所需要的功能。一番快速建模后,第一版的架构迭代先把功能实现:
迭代1:四级流水硬件架构
题目中涉及的组合逻辑较多,而且基本都具有前后依赖关系,链条较长。首先想到的就是用流水线技术进行优化。所谓流水线技术简单地讲就是在组合逻辑中间插入时序逻辑单元(D触发器),把长组合逻辑链拆解,以免产生过长的路径延时,并提高处理器的运行频率和吞吐量。我设计了一个四级的硬件架构,每一级架构分别负责的运算为:
第一级:
A
=
K
i
+
1
⊕
K
i
+
2
A={K_{i + 1}} \oplus {K_{i + 2}}
A=Ki+1⊕Ki+2,
B
=
C
K
i
⊕
K
i
+
3
B={CK_{i}} \oplus {K_{i + 3}}
B=CKi⊕Ki+3
第二级:
C
=
τ
(
A
⊕
B
)
C=\tau(A\oplus B)
C=τ(A⊕B)
第三级:
D
=
K
i
⊕
C
D={K_{i}} \oplus C
D=Ki⊕C,
E
=
(
D
<
<
<
13
)
⊕
(
D
<
<
<
23
)
E=(D<<<13) \oplus (D<<<23)
E=(D<<<13)⊕(D<<<23)
第四级:
R
e
s
u
l
t
=
D
⊕
E
Result = D \oplus E
Result=D⊕E;
这四级流水将组合逻辑链中可并行计算的部分提取出来放到同一级,同时,每一级的逻辑链长度都等于或者略长于两个32bit数的异或运算,理论上是一种较为均衡的划分方式。
要使得流水线有序执行,必须要有控制器来对输入控制进行解码,并产生对应的输出有效信号,这里我设计了一个有限状态机(FSM),共三个状态,IDLE, BUSY, DONE,IDLE状态在接收到解码开始信号后进入BUSY状态,BUSY状态在每轮密钥计算结束后进入DONE状态,DONE状态判断当前总轮数是否达到要求,若未达到则重新回到BUSY状态,达到则回到IDLE状态。
软件仿真
在写RTL代码之前,最好先利用MATLAB或者C等高级语言快速实现一次算法,这样子可以获得算法计算过程中的一些中间数据,作为RTL debug时的有效参考,这里贴一下我用MATLAB写的软件仿真代码:
Sbox = hex2dec(textread("hex.txt",'%s'));
MK = [0x01234567, 0x89ABCDEF, 0xFEDCBA98, 0x76543210];
FK = [0xa3b1bac6,0x56aa3350,0x677d9197,0xb27022dc];
K = zeros(36,1);
K_4 = bitxor(MK,FK);
K(1:4) = K_4;
CK = zeros(32,1);
CK_sub = zeros(32,4);
for i=1:32
for j = 1:4
CK_sub(i,j) = mod((4*(i-1)+(j-1))*7,256);
end
CK(i) = concat(CK_sub(i,:));
end
for i = 1:32
K_middle = dec2bin(bitxor(bitxor(bitxor(K(i+1),K(i+2)),K(i+3)),CK(i)),32);
// nonlinear function, 拆分为4个8bit进行查找
K_nonlin_index = [bin2dec(K_middle(1:8)),bin2dec(K_middle(9:16)),bin2dec(K_middle(17:24)),bin2dec(K_middle(25:32))]+1;
K_nonlin = [Sbox(K_nonlin_index(1)),Sbox(K_nonlin_index(2)),Sbox(K_nonlin_index(3)),Sbox(K_nonlin_index(4))];
// 拼接回32bit
K_nonlin = concat(K_nonlin);
// linear function
K_nonlin_13 = bin2dec(circshift(dec2bin(K_nonlin,32),[0,-13]));
K_nonlin_23 = bin2dec(circshift(dec2bin(K_nonlin,32),[0,-23]));
K_lin = bitxor(bitxor(K_nonlin,K_nonlin_13), K_nonlin_23);
// K_i+4 = K_i xor K_lin
K(i+4) = bitxor(K(i), K_lin);
end
rk = dec2hex(K(5:36));
硬件行为级仿真
使用Verilog进行RTL编写,代码本身很简单,就是一个三段式状态机+四级流水线的标准实现。FK, CK还有Sbox这三个变量属于常量,由于题目要求必须使用可综合的风格,实际代码中对这三个变量都采用了硬编码的方式,由于篇幅有限就没有写在下面的代码里面。
`define ALU_STAGE 4
module encrypt (
input clk_sys,
input reset_sys_n,
input [127:0] crypto_key,
input key_expansion_run,
output key_expansion_busy,
output crypto_rnd_key_vld,
output [31:0] crypto_rnd_key
);
parameter IDLE = 2'b00;
parameter BUSY = 2'b01;
parameter DONE = 2'b11;
// 硬编码常量
wire [31:0] FK [3:0];
wire [31:0] CK [31:0];
wire [7:0] Sbox [255:0];
reg [2:0] state, next_state;
reg [3:0] alu_stage;
reg [6:0] counter_round;
reg [31:0] K [3:0];
reg [127:0] crypto_key_reg;
reg [31:0] alu_res_stage_1_a,alu_res_stage_1_b, alu_res_stage_2, alu_res_stage_3_a, alu_res_stage_3_b, alu_res_stage_4;
always @(posedge clk_sys or negedge reset_sys_n) begin
if(~reset_sys_n) begin
state <= IDLE;
end else begin
state <= next_state;
end
end
always @(*) begin
case (state)
IDLE: begin
if(key_expansion_run) next_state = BUSY;
else next_state = IDLE;
end
BUSY: begin
if(alu_stage == `ALU_STAGE) next_state = DONE;
else next_state = BUSY;
end
DONE: begin
if(counter_round == 7'd31) next_state = IDLE;
else next_state = BUSY;
end
default: next_state = IDLE;
endcase
end
always @(posedge clk_sys or negedge reset_sys_n) begin
if(~reset_sys_n) begin
K[0] <= 'b0;
K[1] <= 'b0;
K[2] <= 'b0;
K[3] <= 'b0;
counter_round <= 'b0;
alu_stage <= 'b0;
end else begin
case (state)
IDLE: begin
K[0] <= crypto_key_reg[127:96] ^ FK[0];
K[1] <= crypto_key_reg[95:64] ^ FK[1];
K[2] <= crypto_key_reg[63:32] ^ FK[2];
K[3] <= crypto_key_reg[31:0] ^ FK[3];
counter_round <= 'b0;
alu_stage <= 'b0;
end
BUSY: begin
counter_round <= counter_round;
alu_stage <= alu_stage + 1;
end
DONE: begin
counter_round <= counter_round + 1;
alu_stage <= 'b0;
K[0] <= K[1];
K[1] <= K[2];
K[2] <= K[3];
K[3] <= alu_res_stage_4;
end
endcase
end
end
assign crypto_rnd_key_vld = (state==DONE) ? 1'b1 : 1'b0;
assign crypto_rnd_key = alu_res_stage_4;
assign key_expansion_busy = (state==IDLE) ? 1'b0 : 1'b1;
always @(posedge clk_sys or negedge reset_sys_n) begin
if(~reset_sys_n) begin
crypto_key_reg <= 'b0;
end else begin
crypto_key_reg <= crypto_key;
end
end
// Stage 1: K_i+1 ^ K_i+2, K_i+3 ^ CK_i
// Stage 2~5: S(K_i+1 ^ K_i+2 ^ K_i+3 ^ CK_i), nonlinear function, time_multiplexed
// Stage 6: K_i ^ B, (B<<<13) ^ (B<<<23)
// Stage 7: (K_i ^ B) ^ ((B<<<13) ^ (B<<<23))
wire [31:0] alu_res_stage_xor_2 = alu_res_stage_1_a ^ alu_res_stage_1_b;
always @(posedge clk_sys or negedge reset_sys_n) begin
if(~reset_sys_n) begin
// Stage 1
alu_res_stage_1_a <= 'b0;
alu_res_stage_1_b <= 'b0;
// Stage 2~5
alu_res_stage_2 <= 'b0;
// Stage 6
alu_res_stage_3_a <= 'b0;
alu_res_stage_3_b <= 'b0;
// Stage 7
alu_res_stage_4 <= 'b0;
end else begin
// Stage 1
alu_res_stage_1_a <= K[1]^K[2];
alu_res_stage_1_b <= K[3]^CK[counter_round];
// Stage 2
alu_res_stage_2 <= {Sbox[alu_res_stage_xor_2[31:24]],
Sbox[alu_res_stage_xor_2[23:16]],
Sbox[alu_res_stage_xor_2[15:8]],
Sbox[alu_res_stage_xor_2[7:0]]};
// Stage 3
alu_res_stage_3_a <= K[0] ^ alu_res_stage_2;
alu_res_stage_3_b <= {alu_res_stage_2[18:0], alu_res_stage_2[31:19]} ^ {alu_res_stage_2[8:0], alu_res_stage_2[31:9]};
// Stage 4
alu_res_stage_4 <= alu_res_stage_3_a ^ alu_res_stage_3_b;
end
end
endmodule
使用Synposys VCS逻辑仿真工具,在golden数据上仿真结果正确,表明我们设计的逻辑在功能上是没有问题的。并且每4个周期就可以完成一轮运算。


逻辑综合
使用Design Compiler工具对上述RTL代码进行逻辑综合。逻辑综合指的是将行为级的RTL代码通过EDA工具的翻译,优化和映射,转化为特定工艺库下的门级网表单元,来给下一步的后端物理设计做准备。行为级仿真主要关注功能的正确性,而经过综合之后,就可以初步地评估我们所设计的电路的性能,在这里我们主要关注两个指标,分别是面积和速度。题目要求的是“面积越小越好”,我们首先来看看DC对面积的估算情况:
Number of ports: 165
Number of nets: 2675
Number of cells: 2544
Number of combinational cells: 2083
Number of sequential cells: 461
Number of macros/black boxes: 0
Number of buf/inv: 344
Number of references: 47
Combinational area: 2211.526828
Buf/Inv area: 188.395206
Noncombinational area: 1909.882775
Macro/Black Box area: 0.000000
Net Interconnect area: undefined (Wire load has zero net area)
Total cell area: 4121.409603
上述单位为μm^2,仍然具有一定的优化空间,我们再看时序的情况,报告时序最差的一条路径:
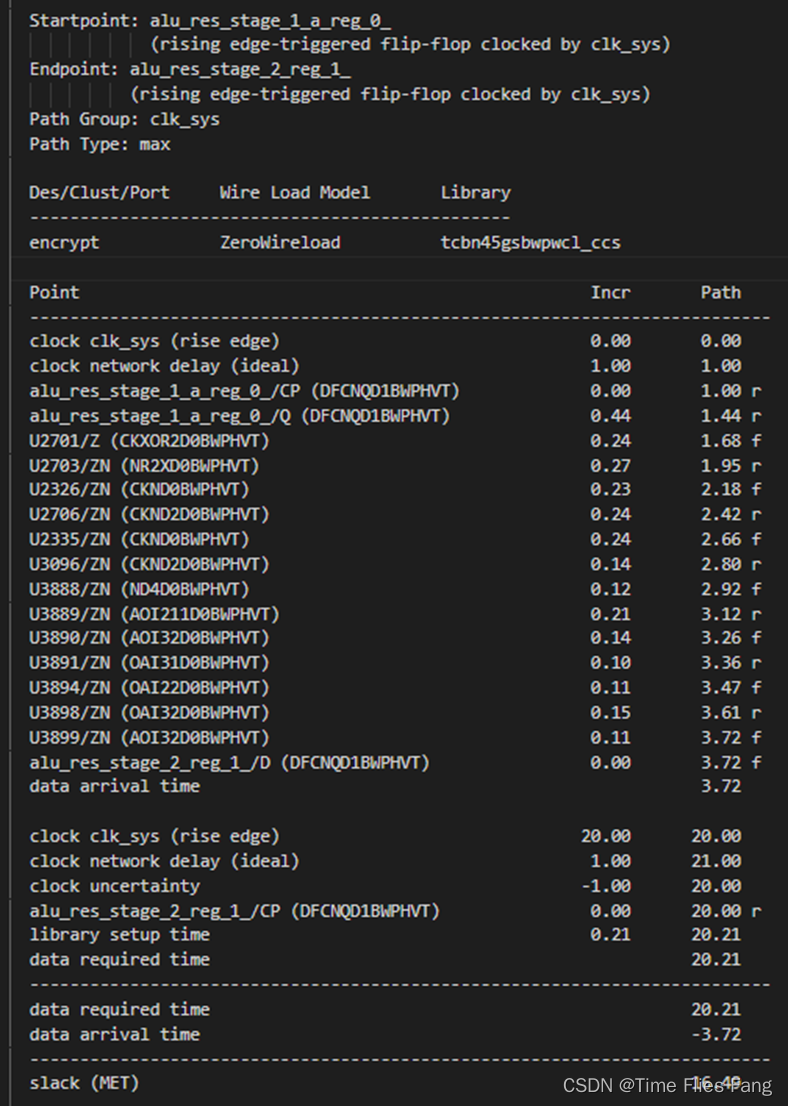
我们可以看到,stage_1到stage_2之间的运算成为了瓶颈,造成这一点的原因是非线性运算过程中由于进行了对查找表进行了硬编码,综合工具产生了一系列的组合逻辑单元,而非像一般情况下的那样从片上SRAM按地址进行查找。这一个硬编码组合逻辑网络产生了较大的延迟,使得这一级运算的延时远超另外三级的延时。
迭代2:模块复用+串行化
如上所述,迭代1的设计还有许多优化空间,最直接的一个优化思路来自于面积优化。实际上,流水线级数越高,所需要插入的DFF就越多,面积消耗也就越多,此外,在本题中,由于没有源源不断的数据从输入端输入,下一轮运算的输入是上一轮运算的输出,因此这里的流水线是伪流水线,实际上大量的寄存器和组合逻辑硬件资源在此处被浪费了。因此在第二轮迭代中,我采用了模块复用+串行化的思想来节省对面积的占用。
模块复用
观察题设中所涉及的算子,我们发现,32bit的异或运算被反复的使用,因此,我们有理由复用这个运算模块,这样子就节省了流水线架构下每一级内和每一级间被反复堆叠的组合逻辑单元
串行化
模块复用必然会导致从本来可以并行处理的数据,现在只能串行地加载到唯一的运算模块当中,这也是速度与面积之间tradeoff的直接体现。
上述两个思想对应到硬件结构上大概可以用下面这张简图表示,XOR电路的两个输入一个只与结果寄存器RES相连,另一个则在状态机的控制下按照时间顺序依次写入不同的数据,XOR电路输出接到RES寄存器上。
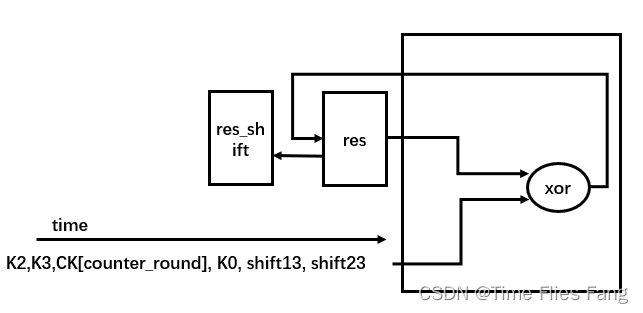
新架构删除了第一版架构中的流水线部分,并补充了这一段控制模块输入数据流的代码
wire [31:0] xor_input_a, xor_result;
reg [31:0] xor_input_b;
assign xor_input_a = res_reg;
assign xor_result = xor_input_a ^ xor_input_b;
always @(*) begin
case (alu_stage)
3'd0: xor_input_b = K[2];
3'd1: xor_input_b = K[3];
3'd2: xor_input_b = CK[counter_round];
3'd3: xor_input_b = CK[counter_round]; //nonlinear function, don't care
3'd4: xor_input_b = {res_reg[18:0], res_reg[31:19]};
3'd5: xor_input_b = {res_reg_reg[8:0], res_reg_reg[31:9]};
3'd6: xor_input_b = K[0];
default: xor_input_b = {res_reg[18:0], res_reg[31:19]};
endcase
end
行为级仿真结果表明新的电路结构功能仍然正确,但是处理每轮运算的周期从4个周期变成了7个周期。

综合结果
Number of ports: 165
Number of nets: 2625
Number of cells: 2494
Number of combinational cells: 2129
Number of sequential cells: 365
Number of macros/black boxes: 0
Number of buf/inv: 299
Number of references: 53
Combinational area: 2218.759217
Buf/Inv area: 180.104405
Noncombinational area: 1424.959187
Macro/Black Box area: 0.000000
Net Interconnect area: undefined (Wire load has zero net area)
Total cell area: 3643.718404
我们可以观察到,新架构的时序单元逻辑面积和个数都与第一版流水线架构有了明显的优化,总面积减少了12%。
还可以再小一点吗
非线性映射模块的复用
在第一版架构中,我们就已经发现了,非线性查找表消耗的硬件资源比我们想象要的要多,不难想象,数据bit数越多,综合出来的逻辑资源越复杂,面积也就越大。由于我们在设计中要求一个周期内输出非线性查找表的结果,因此4个8bit非线性查找的必然是并行进行,而且查找电路具有很大的相似性。将模块复用+串行化的思想在这个环节继续贯彻落实,我们修改该部分的代码如下:
if (alu_stage >= 3'd3 && alu_stage <= 3'd6) begin
res_reg <= {res_reg[23:0], Sbox[res_reg[31:24]]};
end
这段代码十分简洁,但是其实已经完成了并串转化,通过一个类似于移位寄存器的逻辑,每个周期取res_reg的高八位作为非线性查找的索引,并且将查找结果放到res_reg的低八位中,剩下的部分左移8位;如此反复进行4个周期,实际上就完成了对原res_reg中4个8bit值的非线性映射,但是只消耗了一份解码资源。
综合结果
Number of ports: 165
Number of nets: 1502
Number of cells: 1371
Number of combinational cells: 1037
Number of sequential cells: 334
Number of macros/black boxes: 0
Number of buf/inv: 172
Number of references: 44
Combinational area: 1115.553611
Buf/Inv area: 100.371603
Noncombinational area: 1369.040387
Macro/Black Box area: 0.000000
Net Interconnect area: undefined (Wire load has zero net area)
Total cell area: 2484.593997
DC综合结果表明,这次优化带来了更为可观的提高!尤其是在组合逻辑的优化上,把最占资源的非线性映射再次利用复用的思想进行优化,将总面积降低了40%!
需要注意的是,这么做是有代价的。最直接的代价就是处理周期的延长,从第二版中的7个cycle变成了需要10个cycle才能完成一轮运算。此外,在一个周期内完成查找+移位,本身也是一个较长的逻辑链,DC时序分析结果表明这部分成为了新的时序bottleneck,这也会进一步制约工作频率的提高。
小结
如果说奥林匹克精神是“更高,更快,更强”,推之到芯片设计里面,芯片设计的精神就可以总结为“更小,更快,更节能”。这篇文章仅仅是众多芯片人在追求更极致的性能一个缩影,笔者水平有限,也在持续地学习。后续我也将从不同的角度继续从设计者的角度,讨论如何在有限的约束下最大化芯片的工作性能。

















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









