







问题描述:
使用命令行在服务器训练yolov8模型的时候,有时候会遇到time out或者Input/Output error的问题造成还没训练完的模型中断训练,导致需要重头训练模型。
![]()
(使用命令行训练模型的解决方法,python请看最后的链接)
解决方法:
在yolo模型的yaml文件中设置每训练多少轮就保存一次模型
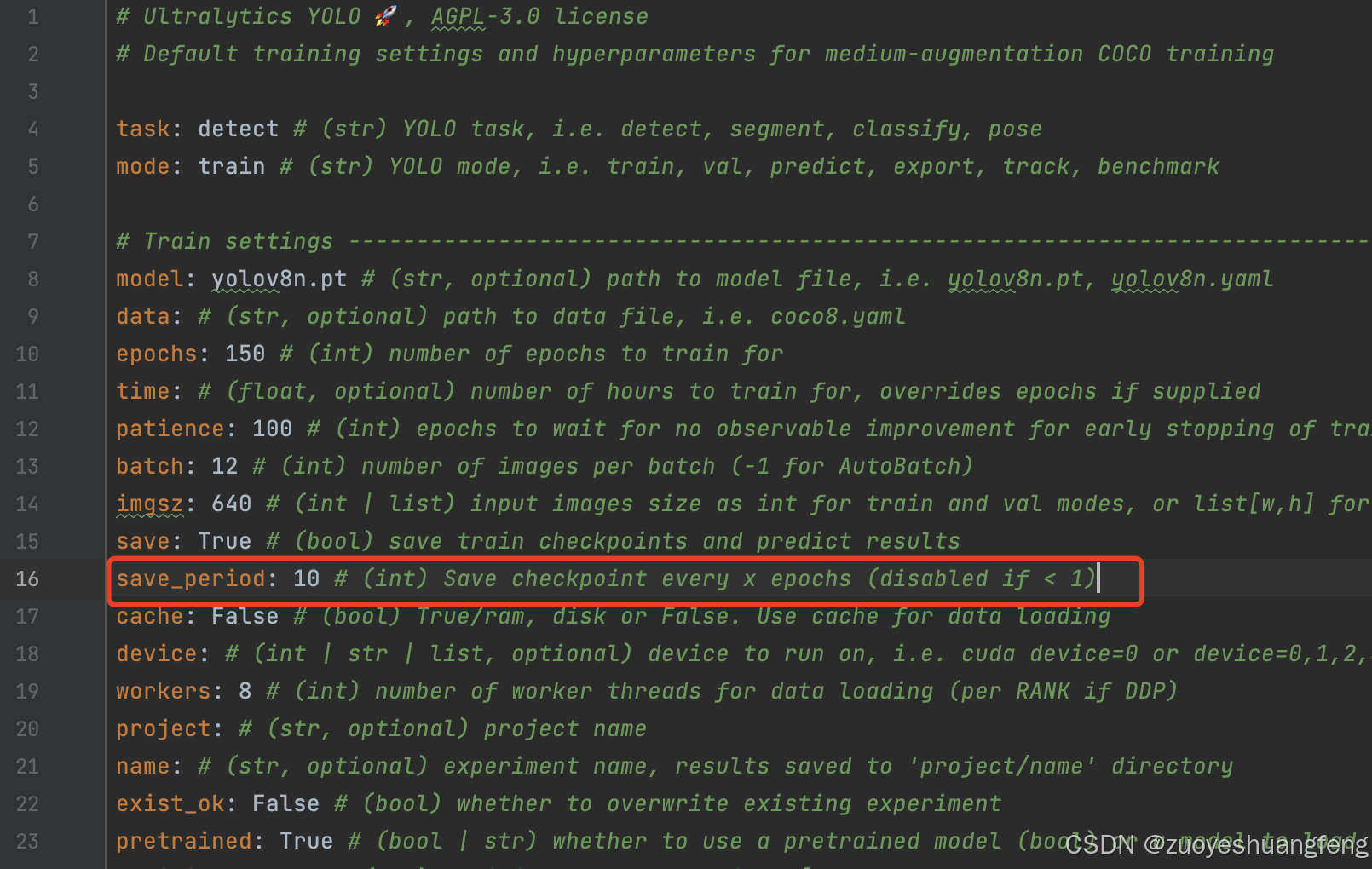
找到
save_period:-1
默认值为-1是在训练过程中不保存模型,想多少轮保存一次就修改成多少。这里我修改成每10轮保存一次。
然后先正常使用命令行语句启动模型训练:
yolo cfg=xx.yaml如果想指定GPU来训练可使用命令行语句:
CUDA_VISIBLE_DEVICES=1 yolo train cfg=XX.yaml这里'CUDA_VISIBLE_DEVICES=1' 是选择的gpu的序号,选择第几个gpu输入序号几。
如果在训练途中遇到time out或者Input/Output error的问题,比如我设置epoch=150,在epoch=112的时候训练中断,但我前面设置的每10轮保存一次的模型还在,则可以从epoch10继续训练。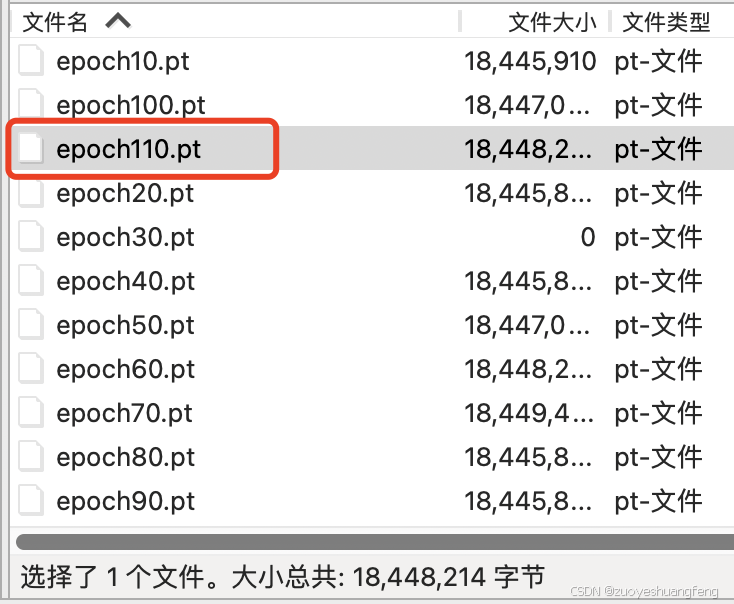
cd进入模型所在的文件夹或者直接使用语句:
yolo train resume model=path/to/last.pt这里可以直接将last.pt改为epoch=110.pt,可以看到模型从上次停止的地方重新开始训练了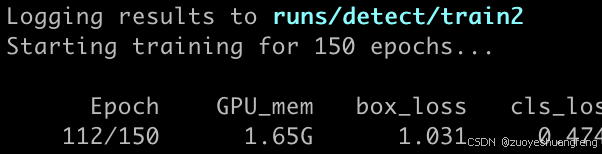
使用python脚本修改或者其他命令行语句可参考官网:
https://docs.ultralytics.com/modes/train/#resuming-interrupted-trainings


















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









