







面板数据为实证分析中最常见的数据类型之一,但是从国家统计局、Wind等网站上下载的一些数据往往需要进行相关处理,才满足stata软件对面板数据的要求。
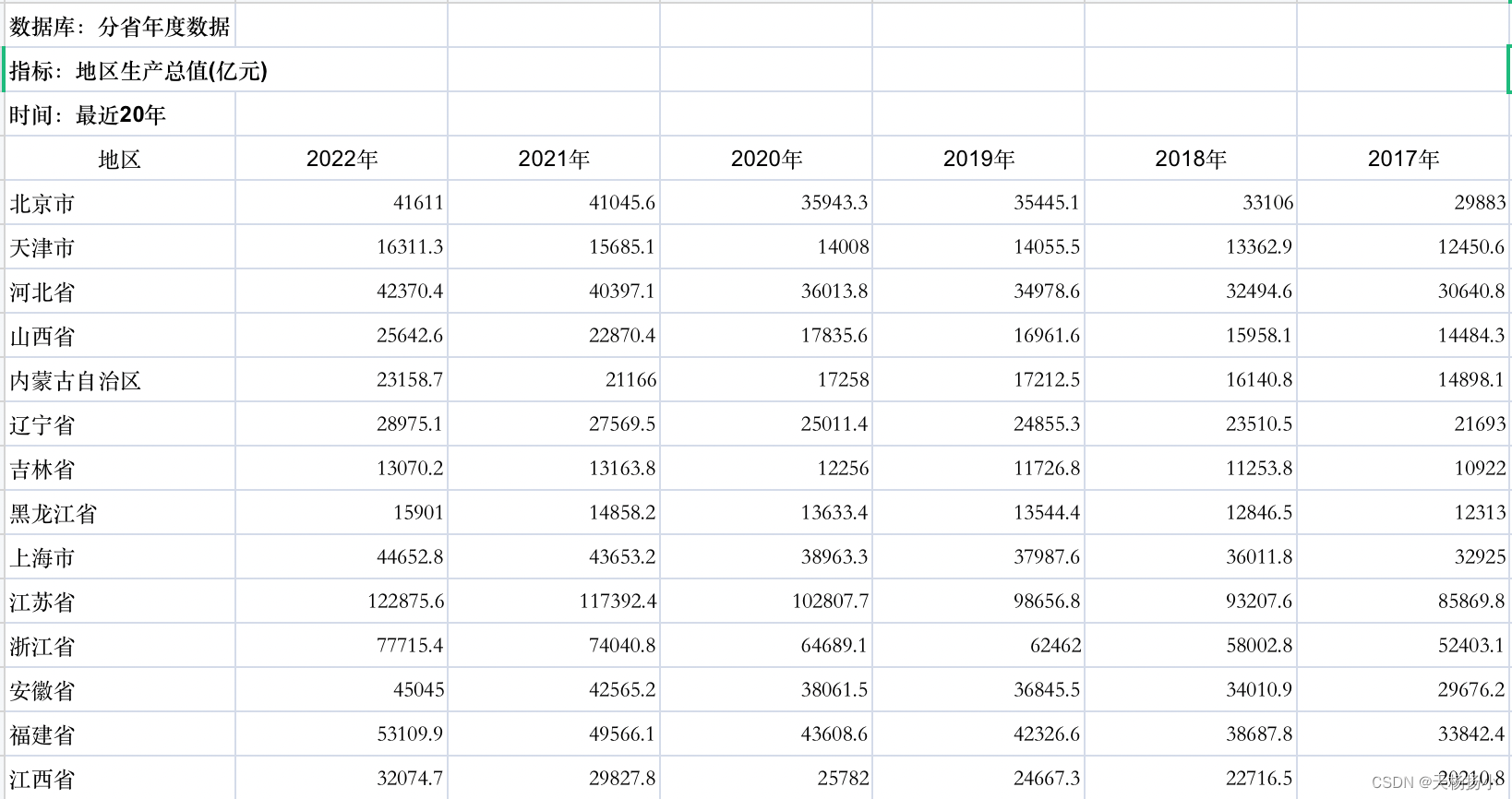
比如,从国家统计局下载2003-2022年各地区生产总值的数据,部分数据如下图所示:
而stata能识别的面板数据类型为:(即本文的目标数据)
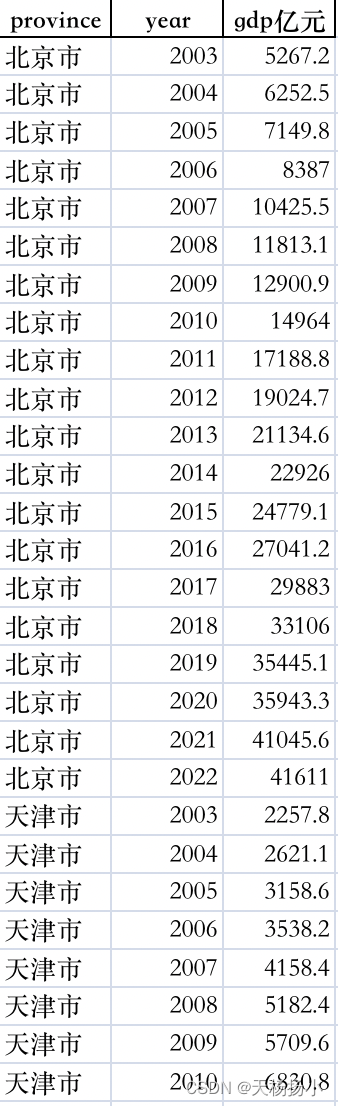
步骤如下:
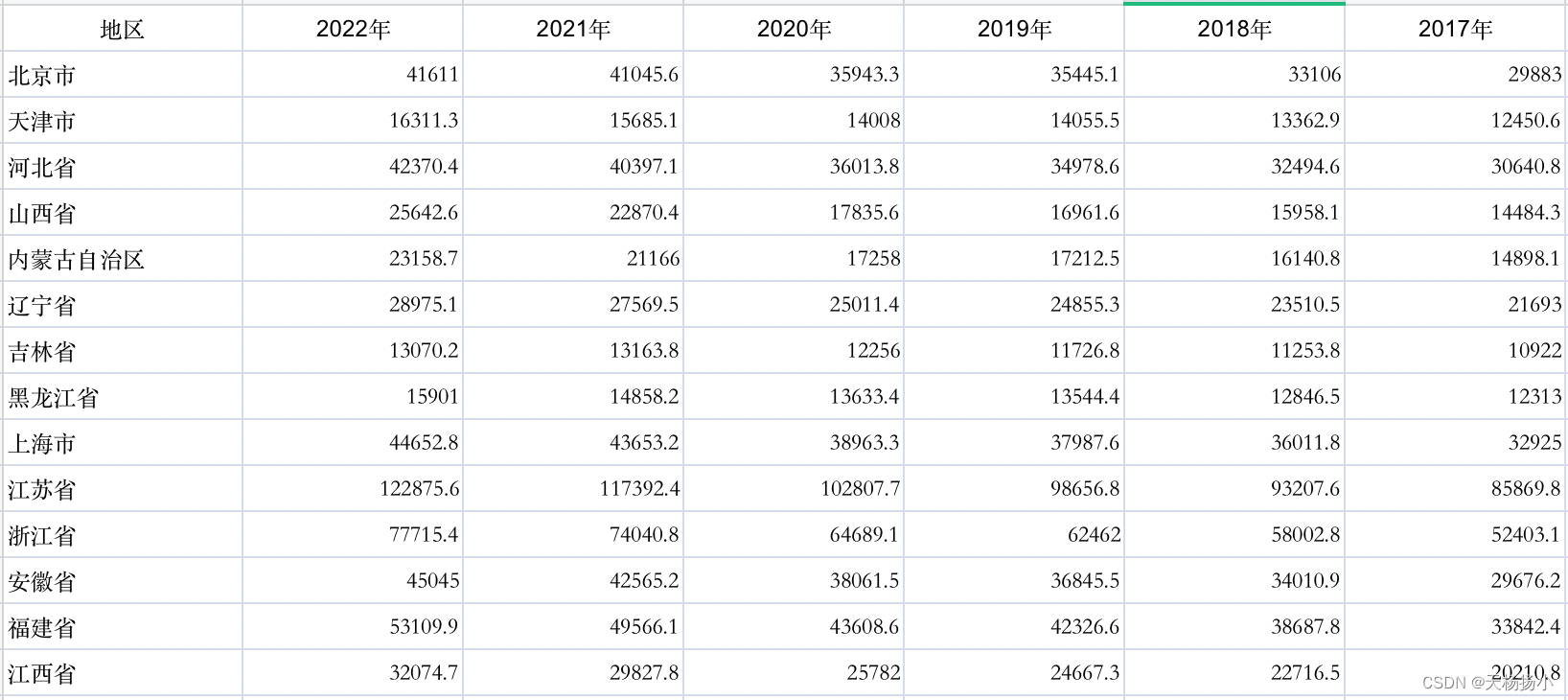
首先,把原始数据表中无关信息手工删掉,如第一张图的前三行等,初步处理如下:
其次,导入pandas包,用其打开数据表,代码如下:
import pandas as pd
df = pd.read_excel('备份:地区生产总值亿元2003-2022.xls')接着,用for循环遍历表格行号,取出各地区省市名称,代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









