







目录
00 学习链接
 https://www.bilibili.com/video/BV1hQ4y1e7js?spm_id_from=333.999.0.0&vd_source=711939c38bbd6809e3d4ec1bb84c88e4
https://www.bilibili.com/video/BV1hQ4y1e7js?spm_id_from=333.999.0.0&vd_source=711939c38bbd6809e3d4ec1bb84c88e4Swin Transformer论文精读【论文精读】_哔哩哔哩_bilibili更多论文见:https://github.com/mli/paper-reading https://www.bilibili.com/video/BV13L4y1475U?spm_id_from=333.337.search-card.all.click&vd_source=711939c38bbd6809e3d4ec1bb84c88e412.1 Swin-Transformer网络结构详解_哔哩哔哩_bilibili详细介绍了Swin-Transformer网络的具体结构,包括Patch partition,Windows Multi-head Self-Attention(W-MSA), Shifted Windows Multi-head Self-Attention(SW-MSA), 相对位置偏执(relative position bias)等。
https://www.bilibili.com/video/BV13L4y1475U?spm_id_from=333.337.search-card.all.click&vd_source=711939c38bbd6809e3d4ec1bb84c88e412.1 Swin-Transformer网络结构详解_哔哩哔哩_bilibili详细介绍了Swin-Transformer网络的具体结构,包括Patch partition,Windows Multi-head Self-Attention(W-MSA), Shifted Windows Multi-head Self-Attention(SW-MSA), 相对位置偏执(relative position bias)等。 https://www.bilibili.com/video/BV1pL4y1v7jC?spm_id_from=333.337.search-card.all.click&vd_source=711939c38bbd6809e3d4ec1bb84c88e4文章作者回复:
https://www.bilibili.com/video/BV1pL4y1v7jC?spm_id_from=333.337.search-card.all.click&vd_source=711939c38bbd6809e3d4ec1bb84c88e4文章作者回复:
01 研究背景
由于CNN在图像处理中具有局部性(locality)和平移不变性(Translation equivariance),因此在很多CV领域都表现得很优秀,但随着任务复杂度的提高,CNN在一些任务上达不到很好的效果,引出了VIT(Vision Transformer)[1]。

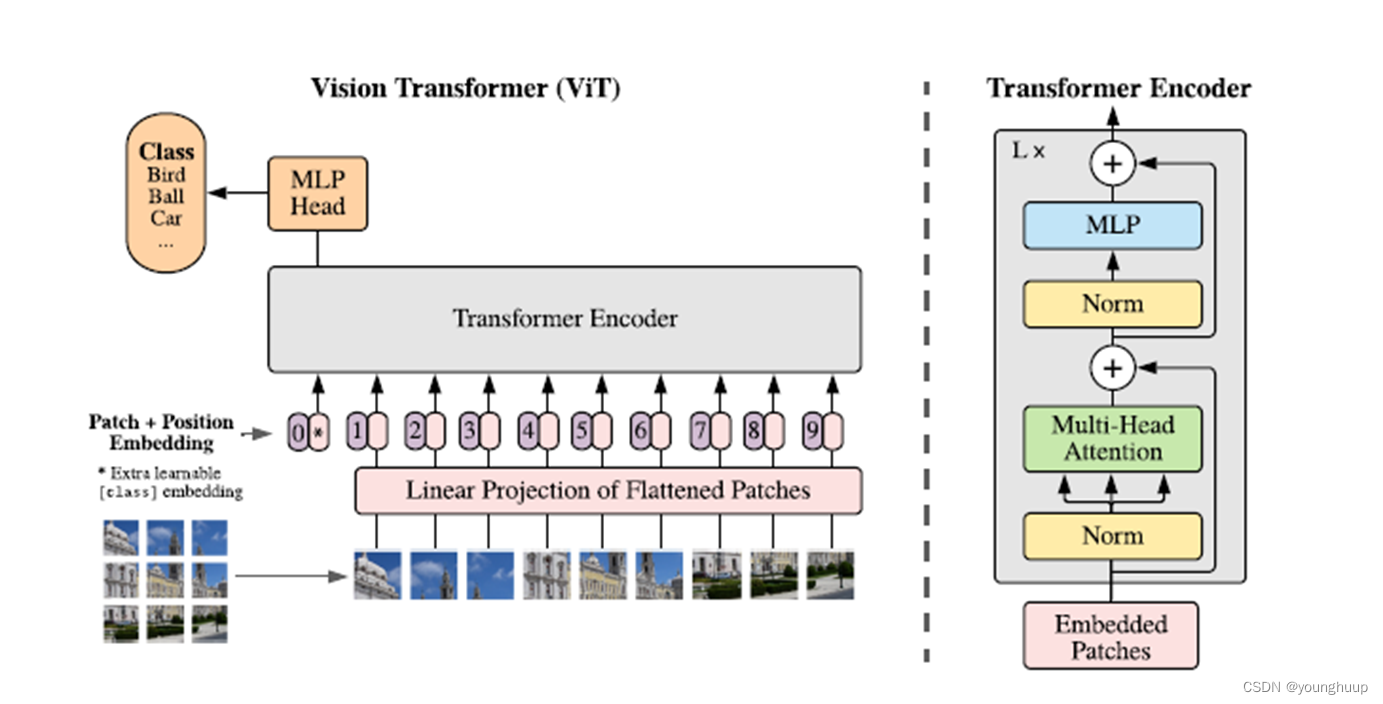
VIT:Vision Transformer[2]
CNN
优点:具有归纳偏置和平移不变性,可以轻易的提取到局部特征。
缺点:缺少全局注意力,泛化能力较弱。
VIT(Vision Transformer)
优点:具有全局注意力,能够处理比较复杂的下游任务,泛化能力较强。
缺点:对硬件计算能力要求高,输入的图像块尺寸固定,缺乏灵活性
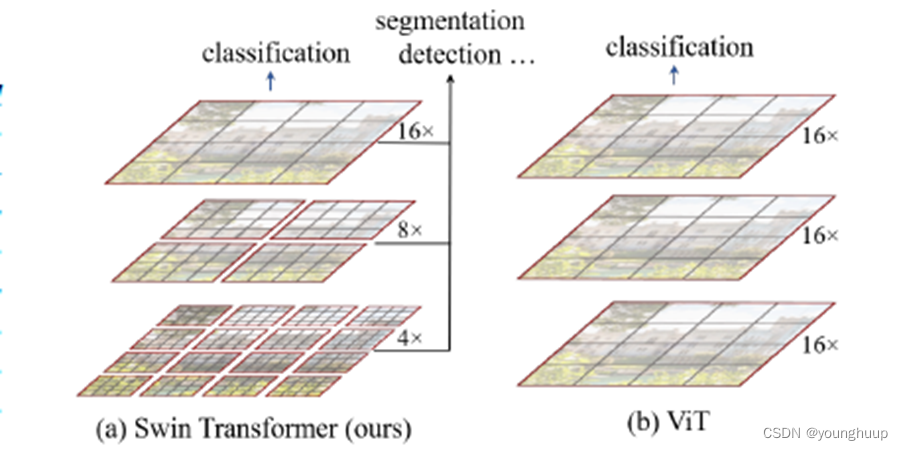
Swin Transformer
1.继承Vinsion Transformer:网络中没有卷积层(CNN)。
2.能够利用到视觉信号中比较好的性质,层次性、局部性和平移不变性。
3.计算复杂度低,数据流与图片尺寸成线性相关。
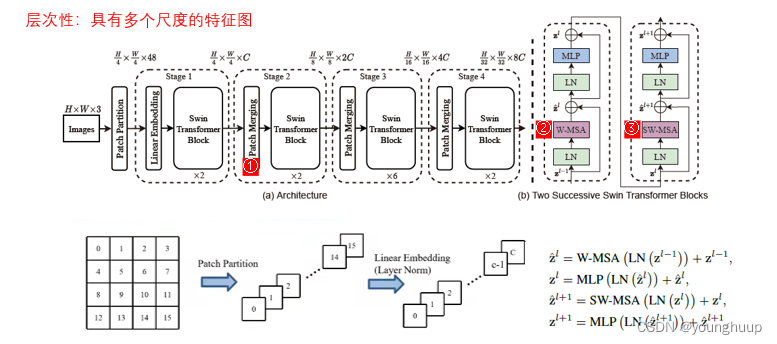
02 整体框架
整体框架如下:
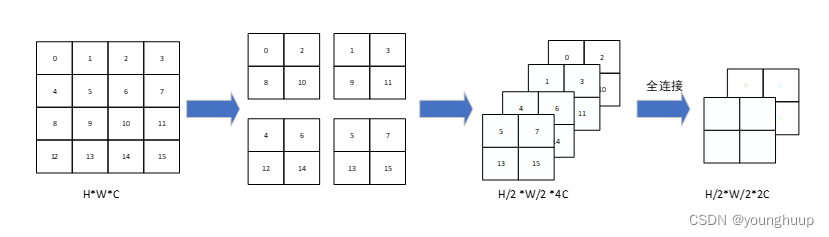
2.1 Patch merging
作用:缩小分辨率,调整通道数,减少计算量,类似于CNN中的池化。
2.2基于窗口的自注意力机制(W-MSA)
MSA操作:全局的patch做自注意力,其计算复杂度为:
W-MSA操作:局部的patch做自注意力,其计算复杂度为: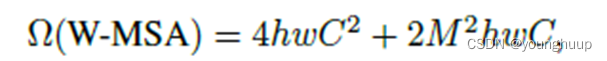
优:减少运算量操作:将全局注意力转换为局部注意力,具有局部性
缺:块与块缺少交流
2.3基于移动窗口的自注意力机制(SW-MSA)
这也是本篇论文的核心创新点:
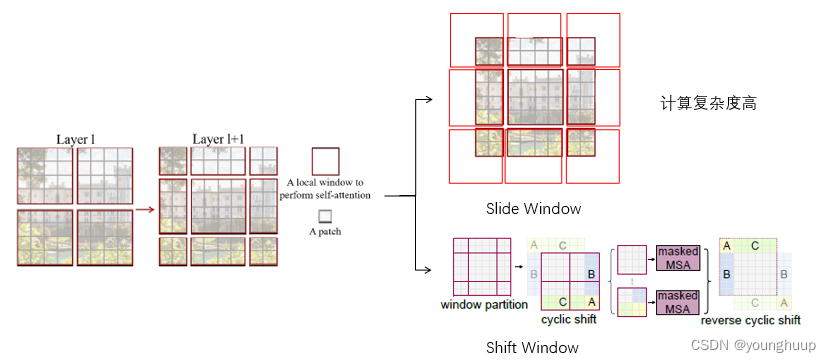
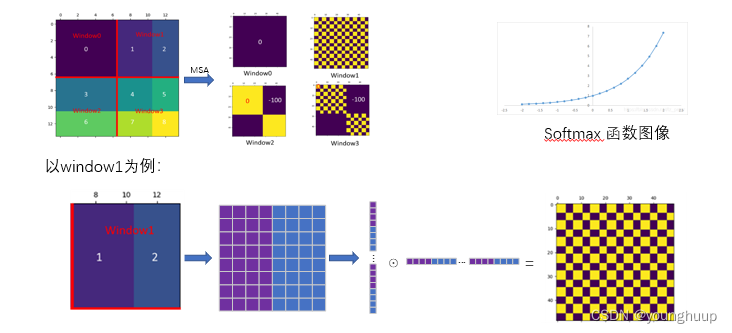
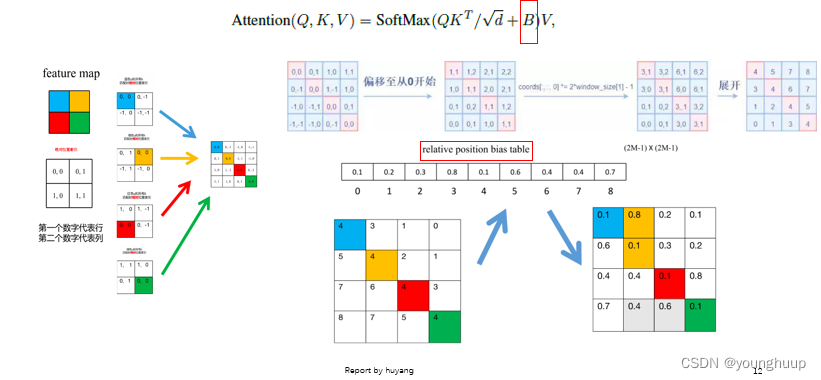
2.4 相对位置偏差计算
详情参考论文[3]
03 实验分析
模型设置:
3.1 分类任务表现

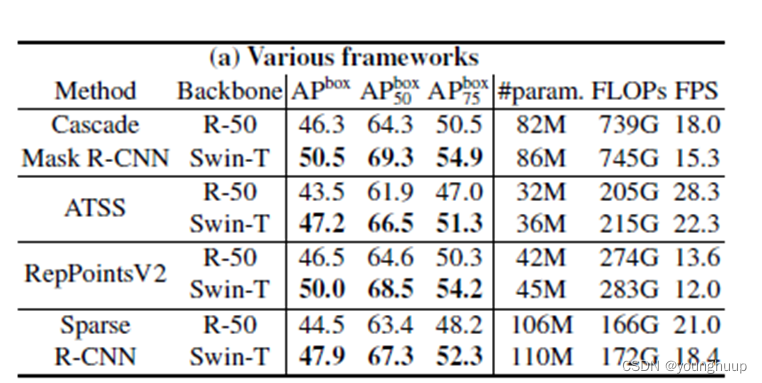
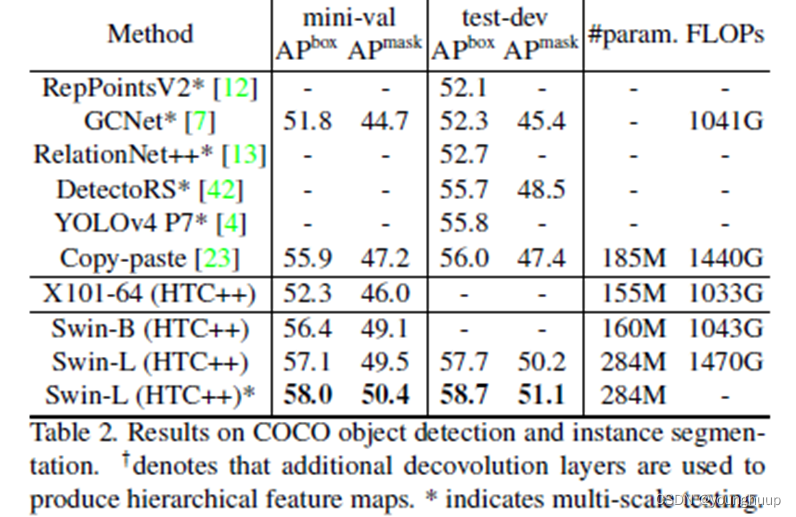
3.2 目标检测任务表现
3.3 语义分割任务表现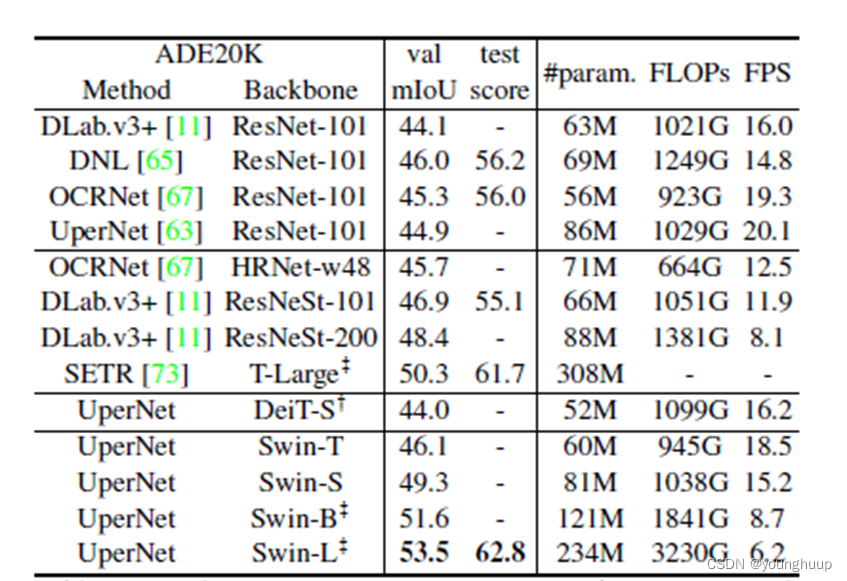
3.4 消融实验

04 总结
本文提出了:
1.使用了基于移动窗口的自注意力机制,使得计算复杂度降低。
2.首次证明用Transformer作为骨干网络在语义分割和目标检测上的效果要比CNN好,终结了CNN在视觉的统治地位。
3.将层次性、局部性和平移不变性等先验引入Transformer网络结构设计能帮助在视觉任务中取得更好的性能。
4.由于用了统一的Transformer架构,从而可以结合NLP与CV进行融合处理,为多模态做了铺垫。
不足:
1.牺牲了自注意力机制的全局性来节省运算的内存
2.窗口分辨率低,只能在小图片上做处理
文献参考
[1] Naseer, Muhammad Muzammal, et al. “Intriguing properties of vision transformers.” Advances in Neural Information Processing Systems 34 (2021).
[2] Dosovitskiy, Alexey, et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” International Conference on Learning Representations. 2020.
[3]Hang bo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiaodong Liu, YuWang, Jianfeng Gao, Song hao Piao, MingZhou, et al. Unilmv2: Pseudo-masked language models for unified language model pre-training. In International Conference on Machine Learning, pages 642–652. PMLR, 2020.















 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









