







Vector Approximate Message Passing, VAMP
前言
事实上,到今天为止,我才知道AMP/VAMP的推导方式并不局限,而且多种多样。此篇博客所介绍的VAMP推导方法基于期望传播算法(Expecation Propagation, EP),相对来说较为简单,也便于理解。
问题模型
考虑要从观测信号
y
=
A
x
0
+
w
∈
R
M
(1)
\boldsymbol{y}=\boldsymbol{Ax}^0+\boldsymbol{w}\in \mathbb{R} ^M \tag{1}
y=Ax0+w∈RM(1)
中恢复向量
x
0
∈
R
N
\boldsymbol{x}^0\in \mathbb{R} ^N
x0∈RN,其中,
A
∈
R
M
×
N
\boldsymbol{A} \in \mathbb{R}^{M \times N}
A∈RM×N已知。对于该问题,主要有以下两种解决思路:
思路1(优化方向):
x
^
=
a
r
g
min
x
∈
R
N
1
2
∥
y
−
A
x
∥
2
2
+
f
(
x
)
(2)
\hat {\pmb x} = \mathrm{arg} \underset{\boldsymbol{x}\in \mathbb{R} ^{\mathrm{N}}}{\min}\frac{1}{2}\left\| \boldsymbol{y}-\boldsymbol{Ax} \right\| _{2}^{2}+f\left( \boldsymbol{x} \right) \tag{2}
xxx^=argx∈RNmin21∥y−Ax∥22+f(x)(2)
式(2)中的
f
(
x
)
f(\pmb x)
f(xxx)的选取是为了提升估计
x
^
\hat {\pmb x}
xxx^的结构性,比如选取
f
(
x
)
=
λ
∥
x
∥
1
f(\pmb x)=\lambda {\Vert {\pmb x} \Vert}_1
f(xxx)=λ∥xxx∥1是考虑到
x
0
\boldsymbol{x}^0
x0的稀疏性。
思路2(贝叶斯方向):
MAP估计
MAP:
x
^
MAP
=
a
r
g
max
x
p
(
x
∣
y
)
=
a
r
g
max
x
p
(
y
∣
x
)
p
(
x
)
(3)
\text{MAP: } \ \hat {\pmb x}_{\text{MAP}}=\mathrm{arg} \underset{\boldsymbol x} {\max} p(\pmb x | \pmb y) = \mathrm{arg} \underset{\boldsymbol x} {\max} p(\pmb y | \pmb x) p(\pmb x) \tag{3}
MAP: xxx^MAP=argxmaxp(xxx∣yyy)=argxmaxp(yyy∣xxx)p(xxx)(3)
MMSE估计
MMSE:
x
^
MMSE
=
a
r
g
min
x
~
∫
∥
x
−
x
~
∥
2
p
(
x
∣
y
)
d
x
=
E
[
x
∣
y
]
(4)
\text{MMSE: } \ \hat {\pmb x}_{\text{MMSE}}=\mathrm{arg} \underset{\boldsymbol{\tilde{x}}} {\min} \int {\Vert \boldsymbol x - \boldsymbol{\tilde{x}} \Vert}^2p(\pmb x | \pmb y) \text{d} \pmb x = \mathbb E[\pmb x | \pmb y] \tag{4}
MMSE: xxx^MMSE=argx~min∫∥x−x~∥2p(xxx∣yyy)dxxx=E[xxx∣yyy](4)
后验概率密度函数
{
p
(
x
n
∣
y
)
}
n
=
1
N
(5)
{\{p(x_n|\pmb y)\}}^N_{n=1} \tag{5}
{p(xn∣yyy)}n=1N(5)
优化和贝叶斯的共通性:若式(1)中观测信号被高斯噪声破坏,即
w
∼
N
(
0
,
γ
ω
−
1
I
)
\pmb w \sim \mathcal N(\pmb 0, {\gamma_{\omega}}^{-1} \pmb I)
www∼N(000,γω−1III),那么当MAP准则中的先验概率
p
(
x
)
p(\pmb x)
p(xxx)与优化中的正则项
f
(
x
)
f(\pmb x)
f(xxx)满足
p
(
x
)
∝
exp
[
−
γ
ω
f
(
x
)
]
(6)
p(\pmb x) \propto \exp[-\gamma_{\omega} f(\pmb x)] \tag{6}
p(xxx)∝exp[−γωf(xxx)](6)
时,认为式(2),即该优化方法与MAP等效。
AMP与贝叶斯推理的简要介绍
若
x
\pmb x
xxx的先验分布满足元素之间独立同分布(i.i.d.),那么
p
(
x
)
=
∏
n
=
1
N
p
(
x
n
)
(7)
p(\pmb x) = \prod_{n=1}^N p(x_n) \tag{7}
p(xxx)=n=1∏Np(xn)(7)
对于AMP算法所使用的滤波函数,这里考虑依据以下两个准则分别建立:
准则1(MAP):滤波函数为(
k
k
k表示迭代次数,
γ
k
\gamma _k
γk表示AMP状态演化时的噪声精度)
g
1
(
r
k
n
,
γ
k
)
=
a
r
g
min
x
n
∈
R
[
γ
k
2
∣
x
n
−
r
k
n
∣
2
−
ln
p
(
x
n
)
]
(8)
\mathrm{g}_1\left( r_{kn},\gamma _k \right) =\mathrm{arg} \underset{x_n\in \mathbb{R}}{\min}\left[ \frac{\gamma _k}{2}\left| x_n-r_{kn} \right|^2-\ln p\left( x_n \right) \right] \tag{8}
g1(rkn,γk)=argxn∈Rmin[2γk∣xn−rkn∣2−lnp(xn)](8)
准则2(MMSE):滤波函数为
g
1
(
r
k
n
,
γ
k
)
=
E
p
(
x
n
∣
r
k
n
,
γ
k
)
[
x
n
∣
r
k
n
,
γ
k
]
(9)
\mathrm{g}_1\left(r_{kn},\gamma _k \right)=\mathbb E_{p(x_n|r_{kn},\gamma _k)} \left [ x_n|r_{kn},\gamma _k \right ] \tag{9}
g1(rkn,γk)=Ep(xn∣rkn,γk)[xn∣rkn,γk](9)
其中,
p
(
x
n
∣
r
k
n
,
γ
k
)
∝
exp
[
−
γ
k
2
∣
x
n
−
r
k
n
∣
2
+
ln
p
(
x
n
)
]
(10)
p(x_n|r_{kn},\gamma _k) \propto \exp \left [-\frac{\gamma _k}{2}\left| x_n-r_{kn} \right|^2+\ln p\left( x_n \right) \right ] \tag{10}
p(xn∣rkn,γk)∝exp[−2γk∣xn−rkn∣2+lnp(xn)](10)
事实上,式(10)中的
p
(
x
n
∣
r
k
n
,
γ
k
)
p(x_n|r_{kn},\gamma _k)
p(xn∣rkn,γk)可以被看作是AMP在第
k
k
k次迭代下的后验概率
p
(
x
n
∣
y
)
p(x_n|\pmb y)
p(xn∣yyy)。另外,对于式(9)所描述的MMSE滤波函数
g
1
(
r
k
n
,
γ
k
)
\mathrm{g}_1\left(r_{kn},\gamma _k \right)
g1(rkn,γk)关于
r
k
n
r_{kn}
rkn的一阶导为:
g
1
′
(
r
k
n
,
γ
k
)
=
γ
k
var
[
x
n
∣
r
k
n
,
γ
k
]
(11)
\mathrm{g}^{\prime}_1\left(r_{kn},\gamma _k \right) = \gamma_k \text{var} [ x_n | r_{kn},\gamma _k ] \tag{11}
g1′(rkn,γk)=γkvar[xn∣rkn,γk](11)
AMP的算法描述

AMP算法中的第7行,“Select
γ
k
+
1
\gamma_{k+1}
γk+1”建议使用
γ
k
+
1
=
M
∥
v
k
∥
2
(12)
\gamma_{k+1} = \frac{M}{{\Vert \pmb v_k \Vert}^2} \tag{12}
γk+1=∥vvvk∥2M(12)
其中
v
k
\pmb v_k
vvvk是第
k
k
k次迭代线性估计(第5行)的残差。
基于期望传播的VAMP推导
我们将联合概率密度函数做分解:
p
(
y
,
x
)
=
p
(
x
)
N
(
y
;
A
x
,
γ
ω
−
1
I
)
(13)
p(\pmb y, \pmb x) = p (\pmb x) \mathcal N(\pmb y; \pmb {Ax}, {\gamma_{\omega}}^{-1}\pmb I) \tag{13}
p(yyy,xxx)=p(xxx)N(yyy;AxAxAx,γω−1III)(13)
进一步引入Dirac符号,把
x
\pmb x
xxx拆分为两个等价的向量
x
1
\pmb x_1
xxx1和
x
2
\pmb x_2
xxx2,则式(13)可分解为
p
(
y
,
x
1
,
x
2
)
=
p
(
x
1
)
δ
(
x
1
−
x
2
)
N
(
y
;
A
x
2
,
γ
ω
−
1
I
)
(13)
p(\pmb y, \pmb x_1, \pmb x_2) = p (\pmb x_1) \delta(\pmb x_1 - \pmb x_2) \mathcal N(\pmb y; \pmb {A} \pmb x_2, {\gamma_{\omega}}^{-1}\pmb I) \tag{13}
p(yyy,xxx1,xxx2)=p(xxx1)δ(xxx1−xxx2)N(yyy;AAAxxx2,γω−1III)(13)
式(13)分解结果所对应的因子图为
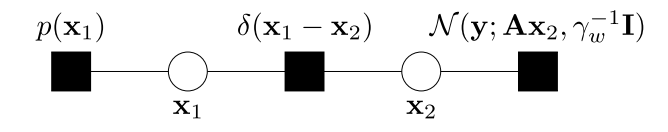
可以看出,该因子图的变量节点为向量形式而非标量。这里首先定义一下三个消息传递规则:
- 规则1(估计信念):在变量节点
x
\pmb x
xxx上的估计信念(Approximate Beliefs)
b
a
p
p
(
x
)
=
N
(
x
;
x
^
,
η
−
1
I
)
b_{app}(\pmb x) = \mathcal N(\pmb x; \hat {\pmb x},\eta^{-1} \pmb I)
bapp(xxx)=N(xxx;xxx^,η−1III),其中
{ x ^ = E b s p [ x ] η − 1 = < diag ( Cov b s p [ x ] ) > (14) \begin{cases} \hat {\pmb x}=\mathbb E_{b_{sp}}[\pmb x] \\ \eta^{-1} = <\text{diag}(\text{Cov}_{b_{sp}}[\pmb x])> \\ \end{cases} \tag{14} {xxx^=Ebsp[xxx]η−1=<diag(Covbsp[xxx])>(14)
其中, b s p ( x ) b_{sp}(\pmb x) bsp(xxx)表示所有到变量节点 x \pmb x xxx的信念之积,即 b s p ( x ) ∝ ∏ i μ f i → x ( x ) b_{sp}(\pmb x) \propto \prod_{i} \mu_{f_i \rightarrow \boldsymbol x}(\pmb x) bsp(xxx)∝∏iμfi→x(xxx)。 - 规则2(变量节点到因子节点的消息):本质上与经典的和积算法一致,假设消息从变量节点
x
\boldsymbol x
x传递到相邻的一个因子节点
f
i
f_i
fi,那么
μ x → f i ( x ) ∝ b a p p ( x ) μ f i → x ( x ) (15) \mu_{\boldsymbol x \rightarrow f_i}(\boldsymbol x) \propto \frac{b_{app}(\pmb x)}{\mu_{f_i \rightarrow \boldsymbol x}(\pmb x)} \tag{15} μx→fi(x)∝μfi→x(xxx)bapp(xxx)(15) - 规则3(因子节点到变量节点的消息):本质上与经典的和积算法一致,假设消息从因子节点
f
f
f传递到相邻的一个变量节点
x
i
\boldsymbol x_i
xi,那么
μ f → x i ( x i ) ∝ ∫ f ( x i , { x j } j ≠ i ) ∏ j ≠ i μ x j → f d x j (16) \mu_{f \rightarrow \boldsymbol x_i} (\boldsymbol x_i) \propto \int f(\boldsymbol x_i,{\{ \boldsymbol x_j \}}_{j \neq i}) \prod_{j \neq i} \mu_{\boldsymbol x_j \rightarrow f} \text{d} \boldsymbol x_j \tag{16} μf→xi(xi)∝∫f(xi,{xj}j=i)j=i∏μxj→fdxj(16)
在下面的推导中,我们使用索引 k k k表示第 k k k次迭代,用 n n n表示向量的第 n n n个元素。
第一步(初始化): k = 0 k=0 k=0时,初始化消息 μ δ → x 1 ( x 1 ) = N ( x 1 ; r 10 , γ 10 − 1 I ) \mu_{\delta \rightarrow \boldsymbol x_1}(\boldsymbol x_1) =\mathcal N(\boldsymbol x_1; \boldsymbol r_{10}, {\gamma_{10}}^{-1} \boldsymbol I) μδ→x1(x1)=N(x1;r10,γ10−1I),以下几个步骤交替迭代(for k = 0 , 1 , … k=0,1,\ldots k=0,1,…)
第二步(
x
1
\boldsymbol x_1
x1处的信念估计):变量节点
x
1
\boldsymbol x_1
x1在和积算法操作下的真实信念为
b
s
p
(
x
1
)
∝
p
(
x
1
)
N
(
x
1
;
r
1
k
,
γ
1
k
−
1
I
)
b_{sp}(\boldsymbol x_1) \propto p(\boldsymbol x_1) \mathcal N(\boldsymbol x_1; \boldsymbol r_{1k}, {\gamma_{1k}}^{-1} \boldsymbol I)
bsp(x1)∝p(x1)N(x1;r1k,γ1k−1I),其均值为
x
^
1
k
=
E
[
x
1
∣
b
s
p
(
x
1
)
]
\hat {\boldsymbol x}_{1k} =\mathbb E[\boldsymbol x_1 | b_{sp}(\boldsymbol x_1)]
x^1k=E[x1∣bsp(x1)],”平均方差“为
η
1
k
−
1
=
<
diag
(
Cov
[
x
1
∣
b
s
p
(
x
1
)
]
)
>
\eta_{1k}^{-1}=<\text{diag}(\text{Cov}[\boldsymbol x_1|b_{sp}(\boldsymbol x_1)])>
η1k−1=<diag(Cov[x1∣bsp(x1)])>(”平均方差“这个概念只是为了好叙述,实质上表示的是该分布协方差矩阵对角元素的均值)。进一步使用估计信念
b
a
p
p
(
x
1
)
=
N
(
x
1
;
x
^
1
k
,
η
1
k
−
1
I
)
b_{app}(\boldsymbol x_1)=\mathcal N(\boldsymbol x_1;\hat {\boldsymbol x}_{1k},\eta_{1k}^{-1} \pmb I)
bapp(x1)=N(x1;x^1k,η1k−1III)来近似,联合式(9)(滤波函数使用MMSE准则),可以写出
{
[
x
^
1
k
]
n
=
g
1
(
r
k
n
,
γ
k
)
η
1
k
−
1
=
γ
1
k
−
1
g
1
′
(
r
k
n
,
γ
k
)
(17)
\begin{cases} [\hat {\boldsymbol x}_{1k}]_n =\mathrm{g}_1\left(r_{kn},\gamma _k \right) \\ \eta_{1k}^{-1} = {\gamma_{1k}}^{-1}{\mathrm{g}_1}^{\prime}\left(r_{kn},\gamma _k \right) \\ \end{cases} \tag{17}
{[x^1k]n=g1(rkn,γk)η1k−1=γ1k−1g1′(rkn,γk)(17)
第三步(消息传递):从变量节点
x
1
\boldsymbol x_1
x1到因子节点
δ
\delta
δ的消息为
μ
x
1
→
δ
(
x
1
)
∝
N
(
x
1
;
x
^
1
k
,
η
1
k
−
1
I
)
N
(
x
1
;
r
1
k
,
γ
1
k
−
1
I
)
(18)
\mu_{\boldsymbol x_1 \rightarrow \delta}(\boldsymbol x_1) \propto \frac{\mathcal N(\boldsymbol x_1;\hat {\boldsymbol x}_{1k},\eta_{1k}^{-1} \pmb I)}{\mathcal N(\boldsymbol x_1; \boldsymbol r_{1k}, {\gamma_{1k}}^{-1} \boldsymbol I)} \tag{18}
μx1→δ(x1)∝N(x1;r1k,γ1k−1I)N(x1;x^1k,η1k−1III)(18)
又因为
N
(
x
;
x
^
,
η
−
1
I
)
N
(
x
;
r
,
γ
−
1
I
)
∝
N
(
x
;
(
x
^
η
−
r
γ
)
/
(
η
−
γ
)
,
(
η
−
γ
)
−
1
I
)
(19)
\frac{\mathcal N(\boldsymbol x; \hat{\boldsymbol x},\eta^{-1}\pmb I)}{\mathcal N(\boldsymbol x; \boldsymbol r,\gamma^{-1}\pmb I)} \propto \mathcal N(\boldsymbol x; (\hat {\boldsymbol x} \eta - \boldsymbol r \gamma)/(\eta-\gamma),({\eta - \gamma)}^{-1} \pmb I) \tag{19}
N(x;r,γ−1III)N(x;x^,η−1III)∝N(x;(x^η−rγ)/(η−γ),(η−γ)−1III)(19)
将式(18)带入到式(19)中,得到
μ
x
1
→
δ
(
x
1
)
=
N
(
x
1
;
r
2
k
,
γ
2
k
−
1
I
)
\mu_{\boldsymbol x_1 \rightarrow \delta}(\boldsymbol x_1)=\mathcal N(\boldsymbol x_1;\boldsymbol r_{2k}, {\gamma_{2k}}^{-1} \pmb I)
μx1→δ(x1)=N(x1;r2k,γ2k−1III),其中
{
r
2
k
=
(
x
^
1
k
η
1
k
−
r
1
k
γ
1
k
)
/
(
η
1
k
−
γ
1
k
)
γ
2
k
=
η
1
k
−
γ
1
k
(20)
\begin{cases} \boldsymbol r_{2k}={(\hat {\boldsymbol x}_{1k} \eta_{1k} - \boldsymbol r_{1k} \gamma_{1k})} / {(\eta_{1k} - \gamma_{1k})} \\ \gamma_{2k}^{} = \eta_{1k} - \gamma_{1k}\\ \end{cases} \tag{20}
{r2k=(x^1kη1k−r1kγ1k)/(η1k−γ1k)γ2k=η1k−γ1k(20)
进一步,从因子节点
δ
\delta
δ到变量节点
x
2
\boldsymbol x_2
x2的消息为
μ
δ
→
x
2
(
x
2
)
=
∫
δ
(
x
1
−
x
2
)
μ
x
1
→
δ
(
x
1
)
d
x
1
=
μ
x
1
→
δ
(
x
2
)
(21)
\mu_{\delta \rightarrow \boldsymbol x_2}(\boldsymbol x_2) = \int \delta(\boldsymbol x_1 - \boldsymbol x_2) \mu_{\boldsymbol x_1 \rightarrow \delta}(\boldsymbol x_1) \text{d} \boldsymbol x_1 = \mu_{\boldsymbol x_1 \rightarrow \delta}(\boldsymbol x_2) \tag{21}
μδ→x2(x2)=∫δ(x1−x2)μx1→δ(x1)dx1=μx1→δ(x2)(21)
因此,
μ
δ
→
x
2
(
x
2
)
=
N
(
x
2
;
r
2
k
,
γ
2
k
−
1
I
)
\mu_{\delta \rightarrow \boldsymbol x_2}(\boldsymbol x_2) = \mathcal N(\boldsymbol x_2;\boldsymbol r_{2k}, {\gamma_{2k}}^{-1} \pmb I)
μδ→x2(x2)=N(x2;r2k,γ2k−1III)
第四步(
x
2
\boldsymbol x_2
x2处的信念估计):类似第二步,在变量节点
x
2
\boldsymbol x_2
x2处的真实信念为
b
s
p
(
x
2
)
∝
N
(
x
2
;
r
2
k
,
γ
2
k
−
1
I
)
N
(
y
;
A
x
2
,
γ
ω
−
1
I
)
b_{sp}(\boldsymbol x_2) \propto \mathcal N(\boldsymbol x_2;\boldsymbol r_{2k}, {\gamma_{2k}}^{-1} \pmb I) \mathcal N(\boldsymbol y; \boldsymbol {Ax}_2, {\gamma_\omega}^{-1} \pmb I)
bsp(x2)∝N(x2;r2k,γ2k−1III)N(y;Ax2,γω−1III),其均值和方差分别为
{
x
^
2
k
=
(
γ
ω
A
T
A
+
γ
2
k
I
)
−
1
(
γ
ω
A
T
y
+
γ
2
k
+
r
2
k
)
Cov
[
x
2
∣
b
s
p
(
x
2
)
]
=
(
γ
ω
A
T
A
+
γ
2
k
I
)
−
1
(22)
\begin{cases} \hat{\boldsymbol x}_{2k} = {\left( \gamma_\omega \boldsymbol A^T \boldsymbol A + \gamma_{2k} \pmb I \right)}^{-1} \left( \gamma_\omega \boldsymbol A^T \boldsymbol y + \gamma_{2k}+\boldsymbol r_{2k} \right) \\ \text{Cov}[\boldsymbol x_2|b_{sp}(\boldsymbol x_2)] = {\left( \gamma_\omega \boldsymbol A^T \boldsymbol A + \gamma_{2k} \pmb I \right)}^{-1}\\ \end{cases} \tag{22}
⎩⎪⎨⎪⎧x^2k=(γωATA+γ2kIII)−1(γωATy+γ2k+r2k)Cov[x2∣bsp(x2)]=(γωATA+γ2kIII)−1(22)
依据规则一,令
x
2
\boldsymbol x_2
x2处的估计信念为
N
(
x
2
;
x
^
2
k
,
η
2
k
−
1
I
)
\mathcal N(\boldsymbol x_2;\hat {\boldsymbol x}_{2k}, {\eta}^{-1}_{2k} \pmb I)
N(x2;x^2k,η2k−1III),则
x
^
2
k
\hat {\boldsymbol x}_{2k}
x^2k直接可得,
η
2
k
−
1
=
<
diag
(
Cov
[
x
2
∣
b
s
p
(
x
2
)
]
)
>
{\eta}^{-1}_{2k}=<\text{diag}(\text{Cov}[\boldsymbol x_2|b_{sp}(\boldsymbol x_2)])>
η2k−1=<diag(Cov[x2∣bsp(x2)])>。
令
g
2
(
r
2
k
,
γ
2
k
)
≔
(
γ
ω
A
T
A
+
γ
2
k
I
)
−
1
(
γ
ω
A
T
y
+
γ
2
k
+
r
2
k
)
(23)
\pmb {\mathrm{g}}_2 (\boldsymbol r_{2k},\gamma_{2k}) \coloneqq {\left( \gamma_\omega \boldsymbol A^T \boldsymbol A + \gamma_{2k} \pmb I \right)}^{-1} \left( \gamma_\omega \boldsymbol A^T \boldsymbol y + \gamma_{2k}+\boldsymbol r_{2k} \right) \tag{23}
ggg2(r2k,γ2k):=(γωATA+γ2kIII)−1(γωATy+γ2k+r2k)(23)
并且有
<
g
2
′
(
r
2
k
,
γ
2
k
)
>
=
γ
2
k
N
Tr
[
(
γ
ω
A
T
A
+
γ
2
k
I
)
−
1
]
(24)
<\pmb {\mathrm{g}}^{\prime}_2 (\boldsymbol r_{2k},\gamma_{2k})>=\frac{\gamma_{2k}}{N}\text{Tr}\left[ {\left( \gamma_\omega \boldsymbol A^T \boldsymbol A + \gamma_{2k} \pmb I \right)}^{-1} \right] \tag{24}
<ggg2′(r2k,γ2k)>=Nγ2kTr[(γωATA+γ2kIII)−1](24)
类似于式(17),可以写出
{
x
^
2
k
=
g
2
(
r
2
k
,
γ
2
k
)
η
2
k
−
1
=
γ
2
k
−
1
<
g
2
′
(
r
2
k
,
γ
2
k
)
>
(25)
\begin{cases} \hat{\boldsymbol x}_{2k} =\pmb {\mathrm{g}}_2 (\boldsymbol r_{2k},\gamma_{2k}) \\ \eta_{2k}^{-1} = {\gamma_{2k}}^{-1}<\pmb {\mathrm{g}}^{\prime}_2 (\boldsymbol r_{2k},\gamma_{2k})> \\ \end{cases} \tag{25}
{x^2k=ggg2(r2k,γ2k)η2k−1=γ2k−1<ggg2′(r2k,γ2k)>(25)
第五步(消息传递):类似于第三步,从变量节点
x
2
\boldsymbol x_2
x2传递到因子节点
δ
\delta
δ的消息为
μ
x
2
→
δ
(
x
2
)
∝
N
(
x
2
;
x
^
2
k
,
η
2
k
−
1
I
)
N
(
x
2
;
r
2
k
,
γ
2
k
−
1
I
)
(26)
\mu_{\boldsymbol x_2 \rightarrow \delta}(\boldsymbol x_2) \propto \frac{\mathcal N(\boldsymbol x_2;\hat {\boldsymbol x}_{2k},\eta_{2k}^{-1} \pmb I)}{\mathcal N(\boldsymbol x_2; \boldsymbol r_{2k}, {\gamma_{2k}}^{-1} \boldsymbol I)} \tag{26}
μx2→δ(x2)∝N(x2;r2k,γ2k−1I)N(x2;x^2k,η2k−1III)(26)
令
μ
x
2
→
δ
(
x
2
)
=
N
(
x
2
;
r
1
,
k
+
1
,
γ
1
,
k
+
1
−
1
I
)
\mu_{\boldsymbol x_2 \rightarrow \delta}(\boldsymbol x_2)=\mathcal N(\boldsymbol x_2 ; \boldsymbol r_{1,k+1},\gamma^{-1}_{1,k+1} \pmb I)
μx2→δ(x2)=N(x2;r1,k+1,γ1,k+1−1III),联合式(19)和式(26)可得
{
r
1
,
k
+
1
=
(
x
^
2
k
η
2
k
−
r
2
k
γ
2
k
)
/
(
η
2
k
−
γ
2
k
)
γ
1
,
k
+
1
=
η
2
k
−
γ
2
k
(27)
\begin{cases} \boldsymbol r_{1,k+1}={(\hat {\boldsymbol x}_{2k} \eta_{2k} - \boldsymbol r_{2k} \gamma_{2k})} / {(\eta_{2k} - \gamma_{2k})} \\ \gamma_{1,k+1}^{} = \eta_{2k} - \gamma_{2k}\\ \end{cases} \tag{27}
{r1,k+1=(x^2kη2k−r2kγ2k)/(η2k−γ2k)γ1,k+1=η2k−γ2k(27)
而从因子节点
δ
\delta
δ传递到变量节点
x
1
\boldsymbol x_1
x1的消息与
μ
x
2
→
δ
(
x
2
)
\mu_{\boldsymbol x_2 \rightarrow \delta}(\boldsymbol x_2)
μx2→δ(x2)是一致的。整个消息传递过程和信念估计操作依次迭代直至收敛。
总结:初始化因子节点 δ \delta δ到变量节点 x 1 \boldsymbol x_1 x1的消息后,首先计算变量节点 x 1 \boldsymbol x_1 x1的估计信念;然后将消息传递至 x 2 \boldsymbol x_2 x2,类似地计算变量节点 x 2 \boldsymbol x_2 x2的估计信念,这样依次迭代直至收敛。

对矩阵 A \boldsymbol A A做SVD分解,代入到Algorithm-3 (LMMSE Form)中,可以得到另一个等效的简化形式(尤其是简化了矩阵求逆!):
















 5833
5833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









